026、流式计算:Kafka与Spark Streaming实时处理 序列化:用Kryo,别用Java原生序列化。配置时记得注册自定义类:并行度:Kafka分区数和Spark分区数最好保持1:1或整数倍关系。曾经设了60个Kafka分区,Spark却只有10个core... 国内服务器 1周前100
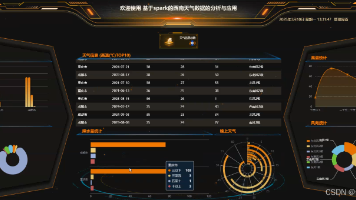
基于Spark+爬虫+Echarts的地区天气数据分析系统设计与实现 今天带来的是基于Spark+爬虫+Echarts的西南天气数据分析系统设计与实现,本研究基于Spark大数据技术,对西南地区气象数据进行多维度分析。通过Python爬虫采集多源气象数据,利用Spark... 国内服务器 1周前100
将 Logstash Pipeline 从 Azure Event Hubs 迁移到 OTel Collector Kafka Receiver 本文介绍了将Logstash pipeline从Azure Event Hubs插件迁移到OpenTelemetry Collector Kafka receiver的详细指南。主要内容包括:配置转换... 国内服务器 1周前120
RabbitMQ 消息 TTL 配置:消息过期时间设置全攻略(两种方案+流程图+实战代码) 在实际业务场景中,很多消息并非需要永久保存,比如订单超时未支付自动取消、验证码过期失效、临时通知过期等。RabbitMQ 提供的TTL(Time-To-Live)过期时间功能,正是用来解决这类“限时处... 国内服务器 1周前140
十五、Zookeeper【待完善】 Zookeeper主要应用于大数据开发中的,统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等场景。该框架相当于大数据框架中的润滑剂。是大数据大数据开发工程师要会的框架之一。 国内服务器 1周前100
RabbitMQ 虚拟主机(vhost)全面解析:是什么、作用、使用场景+实战配置 在 RabbitMQ 中,Virtual Host(vhost,虚拟主机)是一个非常核心且容易被新手忽略的概念。它类似于操作系统的用户空间,也类似于 MySQL 的数据库,是 RabbitMQ 实现资... 国内服务器 1周前90
Cursor vs Claude Code vs Codex:三款 AI 编程工具深度对比 市面上最热门的三款 AI 编程工具——Cursor、Claude Code、GitHub Copilot/Codex,到底有什么区别?该怎么选?Cursor→ AI 原生 IDE,改造你的编辑器→ 终... AI 1周前120
Qdrant 向量数据库完全指南:从入门到 Spring AI/LangChain4J 集成实践 Qdrant(读音:quadrant)是一个用 Rust 编写的开源向量相似度搜索引擎,专门用于存储、搜索和管理向量嵌入(Vector Embeddings)。它提供了高性能的向量搜索能力,支持过滤... AI# Langchain 1周前70
大数据领域数据标注:从入门到精通 数据标注是机器学习项目中最基础也最关键的环节之一。本文旨在为读者提供全面的数据标注知识体系,从入门概念到高级技巧,帮助数据科学家、AI工程师和项目经理更好地理解和实施数据标注工作。本文将首先介绍数据标... 国内服务器 1周前80
Trae AI 辅助编程超全技巧:从入门到提效 Trae 是字节跳动推出的 AI 原生 IDE,核心价值在于深度上下文理解与全流程自动化,能显著提升编码、调试与项目构建效率。以下是分场景的实用技巧,帮你快速上手并发挥最大价值。 AI 1周前90