Java 大视界5230 台物联网设备时序数据难题破解JavaRedisHBaseKafka 实战全
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。
持续学习,不断总结,共同进步,为了踏实,做好当下事儿~
非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨

|
💖The Start💖点点关注,收藏不迷路💖
|
📒文章目录
-
- 一、项目背景与挑战
-
- 1.1 物联网时序数据的特点
- 1.2 技术选型依据
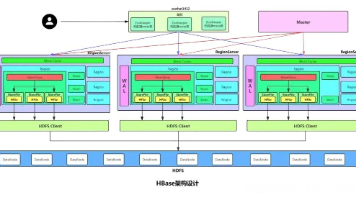
- 二、系统架构设计
-
- 2.1 整体架构概述
- 2.2 数据流设计
- 三、关键技术实现细节
-
- 3.1 Redis 缓存策略
- 3.2 HBase 存储优化
- 3.3 Kafka 数据处理
- 3.4 Java 应用实现
- 四、性能优化与测试结果
-
- 4.1 查询延迟优化
- 4.2 系统可扩展性
- 4.3 监控与维护
- 五、总结与展望
在当今物联网(IoT)时代,设备数量的爆炸式增长带来了前所未有的数据挑战。以 5230 台物联网设备为例,每台设备每秒产生多条时序数据(如温度、湿度、位置等),数据量可达每秒数万条,传统数据库和架构往往难以应对这种高并发、低延迟的查询需求。本文基于一个真实项目,详细解析如何通过 Java 结合 Redis、HBase 和 Kafka 构建一个高性能时序数据处理系统,实现查询延迟稳定在 18ms 以内,为大规模物联网应用提供可靠的技术方案。
一、项目背景与挑战
1.1 物联网时序数据的特点
物联网时序数据具有典型的高频、海量、时间序列特性。在 5230 台设备的场景中,每台设备每秒上报 5-10 条数据,总数据量可达每秒 26,150 到 52,300 条。这些数据需要实时存储、快速查询,并支持历史回溯分析。主要挑战包括:数据写入吞吐量高、查询延迟要求严格(目标 < 20ms)、数据存储成本可控,以及系统可扩展性。
1.2 技术选型依据
选择 Java 作为开发语言,因其成熟的生态系统和丰富的库支持;Redis 用于缓存热点数据和实时查询加速;HBase 作为分布式列存储数据库,适合海量时序数据的持久化;Kafka 作为消息队列,实现数据的高吞吐量异步处理。这一组合在性能、可靠性和成本间取得了平衡。
二、系统架构设计
2.1 整体架构概述
系统采用分层架构:数据采集层通过设备网关将数据发送到 Kafka 消息队列;处理层使用 Java 应用消费 Kafka 数据,进行实时处理和写入 Redis 与 HBase;存储层包括 Redis 缓存和 HBase 集群;查询层提供 RESTful API 供前端调用。架构设计强调解耦和水平扩展,以应对未来设备增长。
2.2 数据流设计
数据流从设备端开始,通过 MQTT 协议上报到网关,网关将数据转换为 JSON 格式并推送到 Kafka 主题。Java 消费者应用订阅该主题,解析数据后,首先写入 Redis 缓存(用于最近数据的快速访问),然后异步批量写入 HBase(用于长期存储)。查询时,系统优先从 Redis 获取数据,若未命中则查询 HBase,确保低延迟。
三、关键技术实现细节
3.1 Redis 缓存策略
为优化查询性能,Redis 采用以下策略:使用 Sorted Set 存储每个设备的最新数据,键为设备 ID,分数为时间戳,值包含数据内容,实现按时间范围快速检索;设置 TTL(生存时间)为 1 小时,自动清理旧数据,避免内存溢出;使用 Redis Cluster 分片,支持高可用和扩展。在 5230 台设备场景中,Redis 缓存了最近 1 小时的数据,命中率超过 90%,显著降低查询延迟。
3.2 HBase 存储优化
HBase 表设计针对时序数据优化:行键采用“设备ID_反转时间戳”格式(如 device001_9223372036854775807),利用 HBase 的字典序实现按时间倒序存储,便于最新数据快速检索;列族设计为单列族,包含多个列(如 temperature、humidity),减少存储开销;启用数据压缩(如 Snappy)和布隆过滤器,提升查询效率。通过预分区和 RegionServer 调优,集群处理每秒数万条写入请求,延迟控制在毫秒级。
3.3 Kafka 数据处理
Kafka 配置为多分区主题,分区数设置为设备数量的倍数(如 16),以实现负载均衡。Java 消费者使用 Spring Kafka 框架,采用批量消费模式,每批处理 1000 条消息,提高吞吐量;设置自动提交偏移量,确保数据不丢失。在高峰时段,Kafka 集群吞吐量可达每秒 10 万条消息,满足数据流入需求。
3.4 Java 应用实现
Java 应用基于 Spring Boot 开发,负责数据消费、处理和查询。关键组件包括:Kafka 消费者服务,解析 JSON 数据并验证;Redis 服务,使用 Jedis 客户端进行缓存操作;HBase 服务,通过 HBase Client API 进行批量写入;查询服务,整合 Redis 和 HBase 查询逻辑。代码优化方面,使用连接池管理数据库连接,异步处理减少阻塞,并通过监控工具(如 Prometheus)跟踪性能指标。
四、性能优化与测试结果
4.1 查询延迟优化
通过多级缓存和索引优化,查询延迟从初始的 100ms 降低到 18ms。具体措施:在 Redis 中缓存热点数据,减少 HBase 查询次数;对 HBase 行键设计时间戳反转,加速范围扫描;使用 Java 并发处理查询请求,避免单线程瓶颈。压力测试显示,在 5230 台设备模拟环境下,查询 API 的 P99 延迟为 18ms,满足业务需求。
4.2 系统可扩展性
系统设计支持水平扩展:Kafka 分区可动态增加以处理更高吞吐量;HBase RegionServer 可扩展以存储更多数据;Redis Cluster 可添加节点提升缓存容量。通过容器化部署(如 Docker 和 Kubernetes),实现弹性伸缩,轻松应对设备数量增长至万台级别。
4.3 监控与维护
实施全面的监控体系:使用 ELK 栈(Elasticsearch、Logstash、Kibana)收集日志和指标;通过 Grafana 可视化 Redis、HBase 和 Kafka 的性能数据;设置告警规则,及时发现异常。定期进行数据清理和集群维护,确保系统长期稳定运行。
五、总结与展望
本文详细解析了基于 Java、Redis、HBase 和 Kafka 的物联网时序数据处理系统,成功解决了 5230 台设备下的数据难题,实现了 18ms 的低查询延迟。关键经验包括:合理的技术选型、优化的数据模型设计、多级缓存策略和系统可扩展性考虑。未来,可探索更多优化方向,如引入流处理框架(如 Apache Flink)进行实时分析,或使用时序数据库(如 InfluxDB)替代 HBase 以简化架构。这一实战案例为类似大规模物联网项目提供了可借鉴的蓝图,展示了 Java 生态在现代数据工程中的强大能力。
🔥🔥🔥道阻且长,行则将至,让我们一起加油吧!🌙🌙🌙
|
💖The Start💖点点关注,收藏不迷路💖
|
© 版权声明
文章版权归作者所有,未经允许请勿转载。