用Python解锁《红楼梦》的文本密码:从分卷到TF-IDF关键词分析
____simple_html_dom__voku__html_wrapper____>
作为中国古典小说的巅峰之作,《红楼梦》的文本深处藏着无数值得挖掘的细节。如果说传统的文本分析靠的是逐字逐句的品读,那么用Python来分析《红楼梦》,则能让我们以更高效、更量化的方式解锁这部经典的文本密码。今天就来分享一套完整的《红楼梦》文本分析流程:从分卷处理到分词,再到用TF-IDF提取各卷核心关键词。
一、前期准备:数据与环境
在开始代码编写前,我们需要准备好基础素材:
1. 文本文件:完整的《红楼梦》txt文件(编码为utf-8);
2. 辅助文件:停用词表(StopwordsCN.txt)、自定义词库(红楼梦词库.txt),用于优化分词效果;
3. 环境依赖:确保安装了pandas、jieba、scikit-learn等库,可通过pip install pandas jieba scikit-learn快速安装。
二、拆分《红楼梦》分卷文本
《红楼梦》原著以“卷”“回”划分章节,直接分析整本文本不利于聚焦局部内容,因此第一步先将整书按“卷 第”的标识拆分成独立的分卷文件,方便后续逐卷分析。
import os
# 创建分卷存储目录
output_dir = r"./分卷"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 读取整本《红楼梦》文本
file = open('红楼梦.txt', encoding='utf-8')
flag = 0 # 标记是否为首次创建分卷文件
juan_file = None
for line in file:
# 识别分卷标识行
if '卷 第' in line:
# 拼接分卷文件名
juan_name = line.strip() + '.txt'
path = os.path.join(output_dir, juan_name)
print(f"正在创建分卷文件:{path}")
# 首次创建文件直接打开,非首次先关闭上一个文件再新建
if flag == 0:
juan_file = open(path, 'w', encoding='utf-8')
flag = 1
else:
juan_file.close()
juan_file = open(path, 'w', encoding='utf-8')
continue
# 将内容写入对应分卷文件
if juan_file:
juan_file.write(line)
# 关闭最后一个分卷文件和整书文件
if juan_file:
juan_file.close()
file.close()
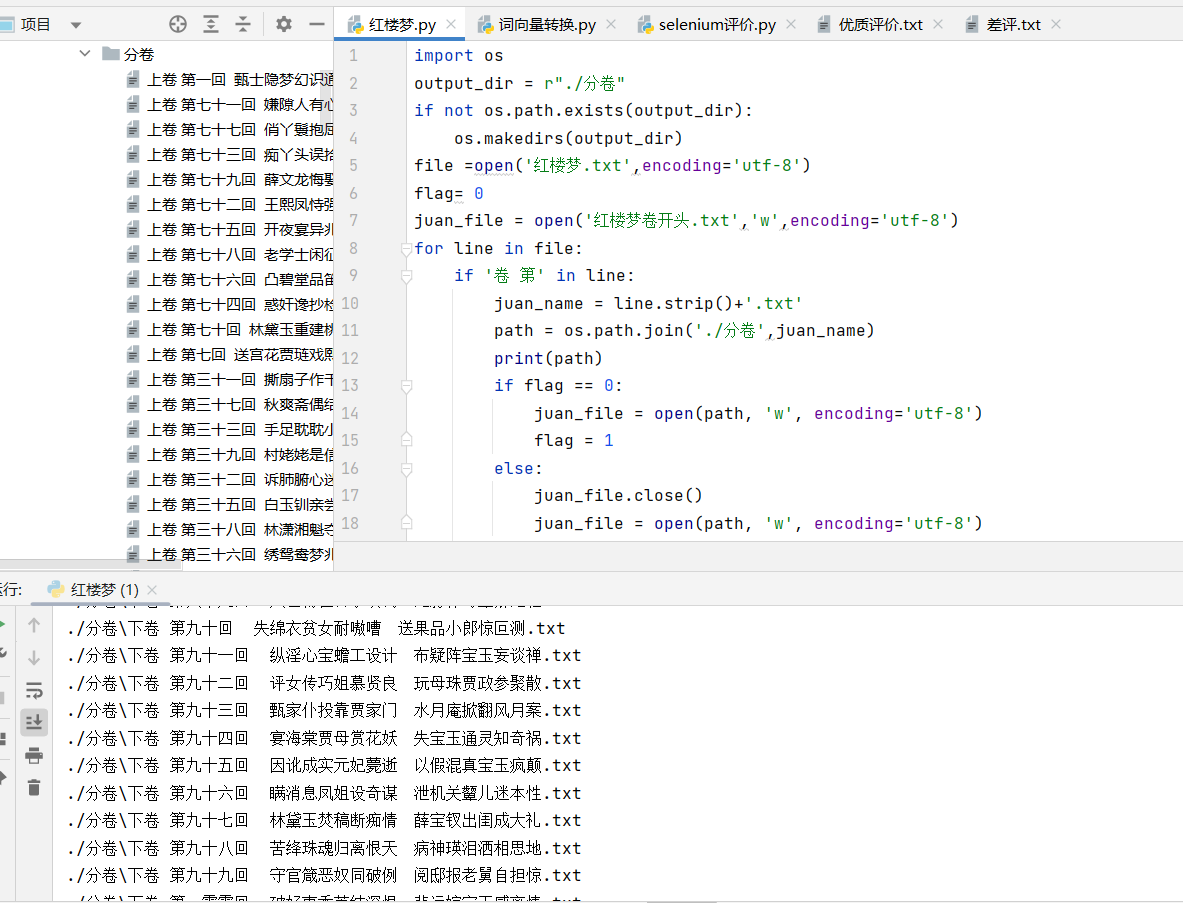
这段代码的核心逻辑是:遍历整书文本的每一行,当识别到包含“卷 第”的行时,判定为新卷的开始,随即创建对应的分卷txt文件,并将后续内容写入该文件,直到识别到下一个分卷标识。执行后,所有分卷文件会被统一保存到“分卷”目录下,方便后续调用。
三、读取分卷文本,构建文本数据集
拆分完成后,我们需要将所有分卷文件的路径和内容读取出来,构建成结构化的DataFrame,为后续分词和分析打下基础。
import pandas as pd
filePaths = []
fileContents = []
# 遍历分卷目录,读取所有文件
for root, dirs, files in os.walk(r"./分卷"):
for name in files:
filePath = os.path.join(root, name)
filePaths.append(filePath)
with open(filePath, 'r', encoding='utf-8') as f:
fileContent = f.read()
fileContents.append(fileContent)
# 构建DataFrame
corpos = pd.DataFrame({
'filePath': filePaths,
'fileContent': fileContents
})
print("分卷文本数据集构建完成:")
print(corpos.head())

通过os.walk遍历目录,我们能自动获取所有分卷文件的路径,再通过文件读取操作获取文本内容,最终用pandas构建成包含“文件路径”和“文本内容”的数据集,既方便查看,也便于后续按行(按卷)处理。
四、中文分词与停用词过滤
中文文本分析的核心步骤之一是分词——将连续的文本拆分成单个词汇。这里我们使用jieba分词库,并结合自定义词库和停用词表优化分词效果:
• 自定义词库:补充《红楼梦》专属词汇(如人名、地名),避免分词时被拆分;• 停用词表:过滤无实际语义的词汇(如“的”“了”“之”),减少无效信息。
import jieba
# 加载自定义词库
jieba.load_userdict(r"./红楼梦词库.txt")
# 读取停用词表
stopwords = pd.read_csv(r"./StopwordsCN.txt", encoding='utf-8', engine='python', index_col=False)
# 转换为集合,提升查询效率
stopwords_set = set(stopwords.iloc[:, 0].tolist())
# 打开文件,存储分词结果
file_to_jieba = open(r'./分词后汇总.txt', 'w', encoding='utf-8')
# 逐卷分词
for index, row in corpos.iterrows():
juan_ci = ''
fileContent = row['fileContent']
# 分词
segs = jieba.cut(fileContent)
for seg in segs:
seg_stripped = seg.strip()
# 过滤停用词和空字符串
if seg_stripped not in stopwords_set and len(seg_stripped) > 0:
juan_ci += seg_stripped + ' '
# 写入分词结果
file_to_jieba.write(juan_ci + 'n')
file_to_jieba.close()
print("分词完成,结果已保存至「分词后汇总.txt」")
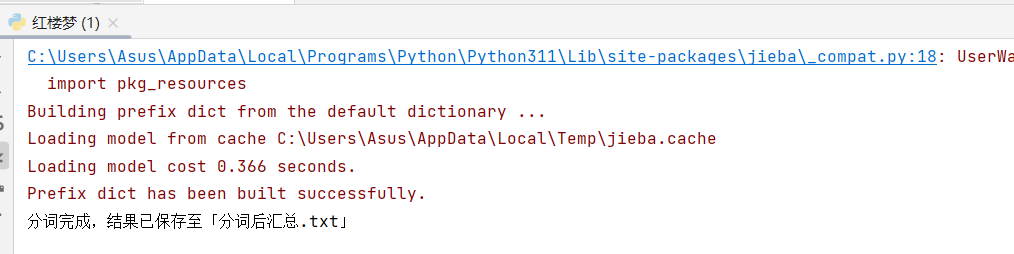
五、用TF-IDF提取各卷核心关键词
TF-IDF(词频-逆文档频率)是文本挖掘中常用的关键词提取方法,核心思想是:一个词汇在某篇文档中出现频率越高,且在所有文档中出现频率越低,就越能代表该文档的核心内容。我们用scikit-learn的TfidfVectorizer实现这一过程,并提取每一卷的Top10核心关键词:
from sklearn.feature_extraction.text import TfidfVectorizer
# 读取分词后的文本
inFile = open(r"./分词后汇总.txt", 'r', encoding='utf-8')
corpos = inFile.readlines()
inFile.close()
# 初始化TF-IDF向量化器
vectorizer = TfidfVectorizer()
# 计算TF-IDF矩阵
tfidf = vectorizer.fit_transform(corpos)
# 获取所有词汇列表
wordlist = vectorizer.get_feature_names_out()
# 将TF-IDF矩阵转换为DataFrame,方便查看
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)
# 提取每一卷的Top10关键词
for i in range(len(corpos)):
# 获取该卷所有词汇的TF-IDF值
featurelist = df.iloc[:, i].tolist()
# 构建词汇-权重字典
resdict = dict(zip(wordlist, featurelist))
# 按TF-IDF值降序排序
resdict_sorted = sorted(resdict.items(), key=lambda x: x[1], reverse=True)
# 输出Top10关键词
print(f'第{i+1}卷的核心关键词: ', resdict_sorted[0:10])

执行这段代码后,我们就能看到每一卷的核心关键词——比如某一卷的关键词可能是“宝玉”“黛玉”“大观园”,另一卷可能是“王熙凤”“宁国府”等,这些关键词能精准反映对应章节的核心内容。
六、分析与延伸:从代码到文本洞察
通过这套流程,我们不仅完成了《红楼梦》的文本拆分、分词和关键词提取,更能从量化角度获得对文本的新认知:
1. 核心人物关联:通过各卷关键词的重叠度,分析宝玉、黛玉、宝钗等核心人物在不同章节的出场频次和核心度;
2. 情节脉络梳理:某一卷若高频出现“抄检”“大观园”等词汇,可快速定位到对应情节;
3. 风格特征挖掘:对比不同卷的关键词分布,能感知前八十回与后四十回在词汇使用、叙事焦点上的差异。
七、总结
用Python分析经典文本,不是为了替代传统的文学品读,而是为经典解读提供新的视角和工具。从分卷处理到TF-IDF关键词提取,整个流程既体现了Python在文本处理上的高效性,也让我们能以更客观、更量化的方式走进《红楼梦》的文本世界。
当然,这只是文本分析的入门玩法,后续还可以基于这些数据做更多延伸:比如词云可视化、人物关系网络分析、情感倾向分析等。经典之所以为经典,就在于它能在不同的解读方式下持续焕发新的生命力,而Python,正是我们解锁这份生命力的一把新钥匙。
© 版权声明
文章版权归作者所有,未经允许请勿转载。