
Python+Agent入门实战:0基础搭建可复用AI智能体

🎁个人主页:User_芊芊君子
🎉欢迎大家点赞👍评论📝收藏⭐文章
🔍系列专栏:AI


文章目录:
- 【前言】
-
- 一、先理清:Python+Agent,到底强在哪里?
-
- 1.1 核心区别:Python脚本 vs Python+Agent
- 1.2 2026年Python+Agent的3个热门入门场景
- 1.3 新手入门核心技术栈
- 二、环境搭建:10分钟搞定Python+Agent开发环境
-
- 2.1 第一步:安装Python
- 2.2 第二步:创建虚拟环境
- 2.3 第三步:安装核心依赖包
- 2.4 第四步:配置OpenAI API Key
- 三、实战环节:Python+LangChain,搭建第一个AI智能体
-
- 3.1 实战架构设计
- 3.2 项目结构
- 3.3 分模块编写代码
-
- 3.3.1 工具模块:tools.py
- 3.3.2 Agent核心逻辑:agent_core.py(调度中心)
- 3.3.3 入口文件:main.py(运行Agent,新手直接运行)
- 3.4 运行测试(新手必看,验证成果)
- 3.5 成果验证(新手必做)
- 五、2026年Python+Agent新手进阶路线
- 结尾:Python+Agent,新手也能抓住的AI风口
【前言】
前言:2026年,AI Agent不再是大厂专属,借助Python生态和开源框架,普通开发者也能从0到1搭建属于自己的AI智能体。后台每天都有新手问:“Python零基础能学Agent吗?”“不用复杂框架,怎么快速搭建可运行的智能体?”“Agent和普通Python脚本有啥区别?” 今天这篇博客,彻底打破入门壁垒,全程以Python为核心,从概念拆解到代码实战,从工具选型到避坑指南,附带流程图、可直接复制的代码和高频问题表格,新手跟着敲代码就能上手,收藏这一篇,搞定Python+Agent入门!

一、先理清:Python+Agent,到底强在哪里?
很多新手混淆了“Python脚本”和“Python+Agent”的区别——普通Python脚本是“写死的指令执行”,而Python+Agent是“智能的任务闭环”,核心优势就是**“自主决策、自动执行、可复用、可扩展”**。
1.1 核心区别:Python脚本 vs Python+Agent
| 对比维度 | 普通Python脚本 | Python+Agent智能体 | 核心优势体现 |
|---|---|---|---|
| 执行逻辑 | 按固定步骤执行,一步错全流程崩 | 自主拆解任务、动态调整步骤,容错性强 | 无需手动修改代码,适配不同场景 |
| 交互方式 | 被动执行,需手动触发,无法多轮交互 | 主动理解需求,支持多轮对话,记住上下文 | 像“助手”一样沟通,无需懂代码也能使用 |
| 功能扩展 | 新增功能需修改全部代码,复用性差 | 通过工具注册、插件扩展,无需改动核心逻辑 | 一次搭建,多场景复用(如办公、数据分析) |
| 技术依赖 | 仅依赖Python基础语法,无AI能力 | 结合大模型+Python生态,具备智能决策能力 | 依托开源框架,零基础也能快速上手 |
1.2 2026年Python+Agent的3个热门入门场景
新手不用追求复杂场景,优先选择“代码量少、落地快、能直接用”的方向,这3个场景是目前最适合入门的,也是企业刚需:
自动化办公Agent:自动处理Excel、生成报表、批量发送消息(Python基础+简单Agent框架,1天就能落地);
本地知识库Agent:上传文档(PDF、Word),用自然语言查询内容,无需手动检索(结合RAG技术,新手易上手);
代码辅助Agent:自动检查Python代码错误、优化代码、生成注释(贴合开发者自身需求,边学边用)。
1.3 新手入门核心技术栈
不用堆砌复杂技术,这4个工具/框架就够了,全程Python编写,零基础也能快速掌握,按优先级排序:
-
核心语言:Python 3.10+(稳定、生态完善,新手优先选3.11版本);
-
大模型:OpenAI GPT-3.5/4(新手用GPT-3.5,免费额度足够,推理速度快);
-
Agent框架:LangChain(最主流、资料最多,新手友好,无需从零造轮子);
-
辅助工具:Chroma(轻量级向量数据库,用于存储Agent记忆,配置简单)。
新手避坑:不要一开始就学习多个框架(如AutoGen、CrewAI),先吃透LangChain+Python的组合,再逐步扩展。本文实战案例仅用这4个核心工具,代码简洁,可直接复制运行。
二、环境搭建:10分钟搞定Python+Agent开发环境
环境搭建是新手最容易卡壳的地方,这里一步一步拆解,全程截图级说明,确保每个人都能搞定,无需复杂操作。
2.1 第一步:安装Python
-
下载地址:Python官方下载页,选择Python 3.11.x版本(Windows选64-bit Installer,Mac选macOS 64-bit Installer);
-
安装时勾选“Add Python to PATH”(关键!避免后续配置环境变量),点击“Install Now”,全程下一步即可;
-
验证是否安装成功:打开终端(Windows按Win+R,输入cmd;Mac按Command+空格,输入terminal),输入以下命令:
python --version # 输出Python 3.11.x 即为成功 pip --version # 输出pip版本即可(一般会自动安装)
2.2 第二步:创建虚拟环境
虚拟环境能隔离不同项目的依赖,避免出现“安装A包导致B包报错”的问题,新手一定要养成这个习惯,步骤如下:
# 1. 创建虚拟环境(环境名建议叫agent-env,好记)
python -m venv agent-env
# 2. 激活虚拟环境(Windows系统)
agent-envScriptsactivate
# 2. 激活虚拟环境(Mac/Linux系统)
source agent-env/bin/activate
# 激活成功后,终端前面会出现(agent-env),如下所示:
(agent-env) C:UsersXXX>
2.3 第三步:安装核心依赖包
激活虚拟环境后,复制以下命令,一次性安装所有需要的依赖(LangChain、OpenAI、Chroma等),无需手动逐个安装:
pip install langchain openai chromadb python-dotenv pandas openpyxl
说明:pandas和openpyxl用于后续自动化办公Agent处理Excel,提前安装,避免后续报错。
2.4 第四步:配置OpenAI API Key
Agent需要调用大模型才能实现智能决策,这里用OpenAI的API,新手有免费额度,足够入门使用:
-
注册/登录OpenAI账号:前往 OpenAI官网,注册账号(需绑定手机号,国内可使用境外手机号接收验证码);
-
创建API Key:登录后,点击右上角头像→View API Keys→Create new secret key,复制生成的API Key(注意:只显示一次,复制后保存好,不要泄露);
-
配置API Key:在项目根目录下创建一个名为
.env的文件(无文件名,后缀为env),打开文件,写入以下内容(替换为你的API Key):
OPENAI_API_KEY=your_api_key_here # 替换成你复制的OpenAI API Key
三、实战环节:Python+LangChain,搭建第一个AI智能体
本次实战目标:搭建一个自动化Excel处理Agent,功能包括:读取Excel文件、分析数据、生成可视化报表、保存结果,全程无需手动操作,新手跟着敲代码就能实现,代码注释详细,每一步都有说明。
3.1 实战架构设计
在写代码前,先理清Agent的工作流程,避免盲目编码。本次搭建的Excel处理Agent,核心分为5个模块,形成“接收需求→规划任务→执行操作→记忆结果→反馈输出”的闭环,流程图如下:
读取Excel
分析数据
生成报表
保存结果
用户输入指令
Agent接收指令,解析意图
规划模块:拆解任务(读取Excel→分析数据→生成报表→保存结果)
工具模块:调用Python工具执行子任务
调用pandas工具,读取Excel文件内容
调用大模型,分析数据核心信息(均值、异常值等)
调用pandas工具,生成可视化报表
调用文件工具,保存分析结果和报表
记忆模块:存储数据信息、操作记录(Chroma)
反馈结果给用户,任务完成
核心说明:本次实战不涉及复杂的多Agent协作,聚焦“单Agent+Python工具”,重点让新手掌握“Agent如何调用Python工具”,为后续进阶打下基础。
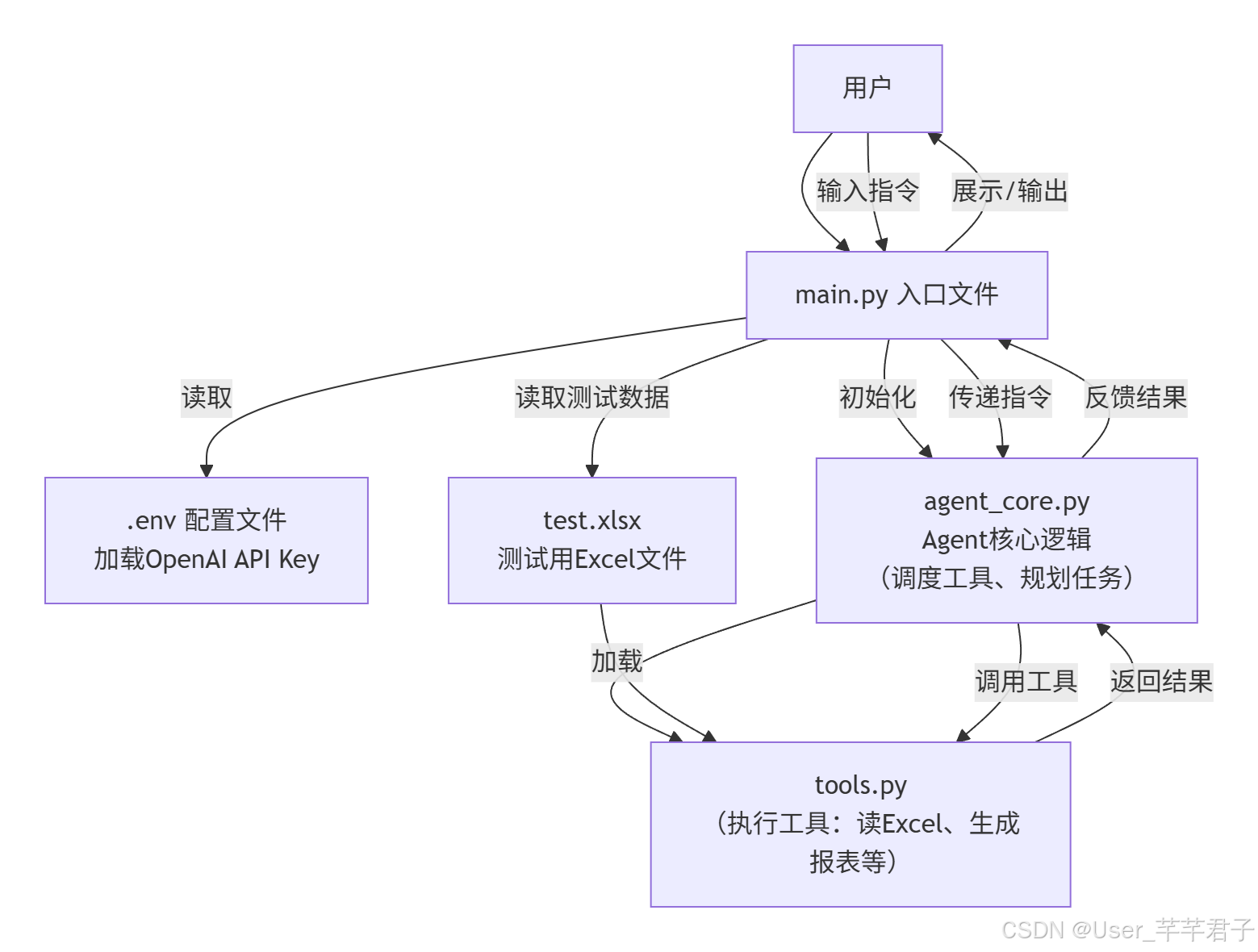
3.2 项目结构
项目结构简洁,共4个文件,新手可直接在桌面创建文件夹(命名为excel-agent),然后创建以下文件:
excel-agent/ # 项目根目录
├── .env # 配置OpenAI API Key
├── tools.py # 自定义Python工具(读取Excel、生成报表等)
├── agent_core.py # Agent核心逻辑(调度工具、规划任务)
└── main.py # 入口文件(运行Agent,输入指令)
└── test.xlsx # 测试用Excel文件(自己创建,随便填点数据)
测试用Excel文件:新手可创建一个test.xlsx,包含“姓名、年龄、成绩”三列,填入10-20条测试数据,用于后续Agent读取和分析。
3.3 分模块编写代码
3.3.1 工具模块:tools.py
定义4个核心Python工具,供Agent自主调用,代码注释详细,新手无需修改,直接复制即可:
from langchain.tools import tool
import pandas as pd
import matplotlib.pyplot as plt
import os
# 工具1:读取Excel文件(核心工具,调用pandas)
@tool
def read_excel(file_path: str) -> str:
"""
读取Excel文件内容,返回数据的基本信息(行数、列数、字段名、前5行数据)
Args:
file_path: Excel文件路径(如./test.xlsx)
Returns:
数据基本信息,便于Agent分析数据
"""
# 检查文件是否存在
if not os.path.exists(file_path):
return f"❌ 错误:文件{file_path}不存在,请检查路径是否正确"
# 读取Excel文件
df = pd.read_excel(file_path)
# 返回数据基本信息
info = f"""✅ 成功读取Excel文件:{file_path}
- 数据总行数:{len(df)}
- 数据总列数:{len(df.columns)}
- 字段名称:{list(df.columns)}
- 前5行数据:
{df.head().to_string()}"""
print(info)
return info
# 工具2:分析Excel数据(调用大模型辅助分析,结合pandas)
@tool
def analyze_excel_data(file_path: str) -> str:
"""
分析Excel数据的核心信息,包括均值、中位数、异常值等(针对数值型字段)
Args:
file_path: Excel文件路径(如./test.xlsx)
Returns:
数据详细分析结果
"""
if not os.path.exists(file_path):
return f"❌ 错误:文件{file_path}不存在,请检查路径是否正确"
df = pd.read_excel(file_path)
# 筛选数值型字段,进行分析
numeric_cols = df.select_dtypes(include=['int64', 'float64']).columns
if len(numeric_cols) == 0:
return "❌ 错误:Excel文件中无数值型字段,无法进行数据分析"
# 计算核心统计信息
analysis = f"📊 Excel数据详细分析结果(仅数值型字段):n"
for col in numeric_cols:
analysis += f"- {col}:n"
analysis += f" 均值:{df[col].mean():.2f}n"
analysis += f" 中位数:{df[col].median():.2f}n"
analysis += f" 最小值:{df[col].min()}n"
analysis += f" 最大值:{df[col].max()}n"
# 简单判断异常值(超出均值±2倍标准差)
mean = df[col].mean()
std = df[col].std()
outliers = df[(df[col] < mean - 2*std) | (df[col] > mean + 2*std)]
analysis += f" 异常值数量:{len(outliers)}nn"
print(analysis)
return analysis
# 工具3:生成数据可视化报表(调用matplotlib)
@tool
def generate_excel_report(file_path: str, save_path: str = "./report.png") -> str:
"""
生成Excel数据的可视化报表(柱状图),保存到指定路径
Args:
file_path: Excel文件路径(如./test.xlsx)
save_path: 报表保存路径(默认./report.png)
Returns:
报表生成结果
"""
if not os.path.exists(file_path):
return f"❌ 错误:文件{file_path}不存在,请检查路径是否正确"
df = pd.read_excel(file_path)
numeric_cols = df.select_dtypes(include=['int64', 'float64']).columns
if len(numeric_cols) == 0:
return "❌ 错误:Excel文件中无数值型字段,无法生成报表"
# 生成柱状图(取第一个数值型字段为例)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码
plt.figure(figsize=(10, 6))
plt.bar(df.index, df[numeric_cols[0]], color='#1f77b4', alpha=0.8)
plt.title(f'{numeric_cols[0]}数据分布', fontsize=14)
plt.xlabel('索引', fontsize=12)
plt.ylabel(numeric_cols[0], fontsize=12)
plt.grid(axis='y', alpha=0.3)
# 保存报表
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
result = f"✅ 可视化报表已生成,保存路径:{os.path.abspath(save_path)}"
print(result)
return result
# 工具4:保存分析结果到文件
@tool
def save_analysis_result(content: str, save_path: str = "./analysis_result.txt") -> str:
"""
将数据分析结果保存到文本文件中
Args:
content: 要保存的分析结果内容
save_path: 保存路径(默认./analysis_result.txt)
Returns:
保存结果
"""
with open(save_path, 'w', encoding='utf-8') as f:
f.write(content)
result = f"✅ 分析结果已保存,保存路径:{os.path.abspath(save_path)}"
print(result)
return result
# 工具列表:将所有工具整理成列表,供Agent调用
excel_tools = [read_excel, analyze_excel_data, generate_excel_report, save_analysis_result]
from langchain.tools import tool
import pandas as pd
import matplotlib.pyplot as plt
import os
# 工具1:读取Excel文件(核心工具)
@tool
def read_excel(file_path: str) -> str:
"""读取Excel文件,返回基本数据信息"""
if not os.path.exists(file_path):
return f"❌ 错误:文件{file_path}不存在"
df = pd.read_excel(file_path)
info = f"✅ 成功读取文件:{file_path}n- 行数:{len(df)} 列数:{len(df.columns)}n- 字段:{list(df.columns)}n- 前5行:n{df.head().to_string()}"
print(info)
return info
# 工具2:分析Excel数据(数值型字段)
@tool
def analyze_excel_data(file_path: str) -> str:
"""分析数值型字段的核心统计信息(均值、中位数等)"""
if not os.path.exists(file_path):
return f"❌ 错误:文件{file_path}不存在"
df = pd.read_excel(file_path)
numeric_cols = df.select_dtypes(include=['int64', 'float64']).columns
if not numeric_cols.empty:
analysis = "📊 数据分析结果:n"
for col in numeric_cols:
analysis += f"- {col}:均值{df[col].mean():.2f},中位数{df[col].median():.2f},最值[{df[col].min()}-{df[col].max()}]n"
print(analysis)
return analysis
return "❌ 无数值型字段,无法分析"
# 工具3:生成可视化报表
@tool
def generate_excel_report(file_path: str, save_path: str = "./report.png") -> str:
"""生成柱状图报表并保存"""
if not os.path.exists(file_path):
return f"❌ 错误:文件{file_path}不存在"
df = pd.read_excel(file_path)
numeric_cols = df.select_dtypes(include=['int64', 'float64']).columns
if not numeric_cols.empty:
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10, 6))
plt.bar(df.index, df[numeric_cols[0]], color='#1f77b4', alpha=0.8)
plt.title(f'{numeric_cols[0]}分布', fontsize=14)
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
return f"✅ 报表已保存:{os.path.abspath(save_path)}"
return "❌ 无数值型字段,无法生成报表"
# 工具4:保存分析结果
@tool
def save_analysis_result(content: str, save_path: str = "./analysis_result.txt") -> str:
"""将分析结果保存到文本文件"""
with open(save_path, 'w', encoding='utf-8') as f:
f.write(content)
return f"✅ 结果已保存:{os.path.abspath(save_path)}"
# 工具列表(供Agent调用)
excel_tools = [read_excel, analyze_excel_data, generate_excel_report, save_analysis_result]
3.3.2 Agent核心逻辑:agent_core.py(调度中心)
整合Python工具、大模型和记忆模块,创建Agent,实现自主规划任务、调用工具,代码如下:
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.memory import VectorStoreRetrieverMemory
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
from tools import excel_tools
from dotenv import load_dotenv
import os
# 加载.env文件中的API Key
load_dotenv()
# 1. 初始化大模型(新手用gpt-3.5-turbo,速度快、免费额度足)
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0.4, # 温度越低,决策越稳定,避免乱调用工具
api_key=os.getenv("OPENAI_API_KEY")
)
# 2. 初始化记忆模块(Chroma向量数据库,存储操作记录和数据信息)
embeddings = OpenAIEmbeddings()
vector_store = Chroma(
embedding_function=embeddings,
persist_directory="./agent_memory", # 记忆数据存储路径
collection_name="excel_agent_memory"
)
vector_store.persist()
# 记忆检索器,供Agent查询历史记录
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
memory = VectorStoreRetrieverMemory(
retriever=retriever,
memory_key="chat_history",
input_key="input",
output_key="output"
)
# 3. 定义Agent提示词(核心!告诉Agent它的角色和工作规则)
prompt = ChatPromptTemplate.from_messages([
(
"system",
"""你是一个专业的Excel处理AI智能体,基于Python实现,负责帮助用户自动处理Excel相关任务。
工作规则:
1. 你的核心工具是python的pandas、matplotlib库,所有Excel操作都通过调用提供的工具完成;
2. 接收用户指令后,先拆解任务步骤(例如:读取Excel→分析数据→生成报表→保存结果),再逐步调用工具;
3. 调用工具前,必须检查参数是否正确(如文件路径是否合理),若参数缺失,及时询问用户;
4. 每次执行完一个工具,查看返回结果,确认无错误后,再执行下一个步骤;
5. 利用记忆模块,记住之前处理过的文件路径、分析结果,避免重复操作;
6. 最终将所有结果整理成清晰的文字,反馈给用户,包括文件保存路径、核心分析结论。"""
),
MessagesPlaceholder(variable_name="chat_history"), # 记忆上下文
("user", "{input}"), # 用户输入指令
MessagesPlaceholder(variable_name="agent_scratchpad") # Agent思考过程
])
# 4. 创建Agent(基于OpenAI工具调用能力,结合Python工具)
agent = create_openai_tools_agent(
llm=llm,
tools=excel_tools,
prompt=prompt
)
# 5. 创建Agent执行器(调度Agent、工具、记忆)
agent_executor = AgentExecutor(
agent=agent,
tools=excel_tools,
memory=memory,
verbose=True, # 开启详细日志,便于新手调试
handle_parsing_errors=True # 自动处理解析错误
)
# 定义Agent运行函数(供入口文件调用)
def run_excel_agent(user_input: str):
try:
print(f"n📋 用户指令:{user_input}")
print("🚀 Agent开始执行任务...n")
result = agent_executor.invoke({"input": user_input})
print(f"n✅ 任务执行完成!")
print(f"📄 最终结果:{result['output']}")
return result
except Exception as e:
error_msg = f"❌ 任务执行失败:{str(e)}"
print(error_msg)
return {"output": error_msg}
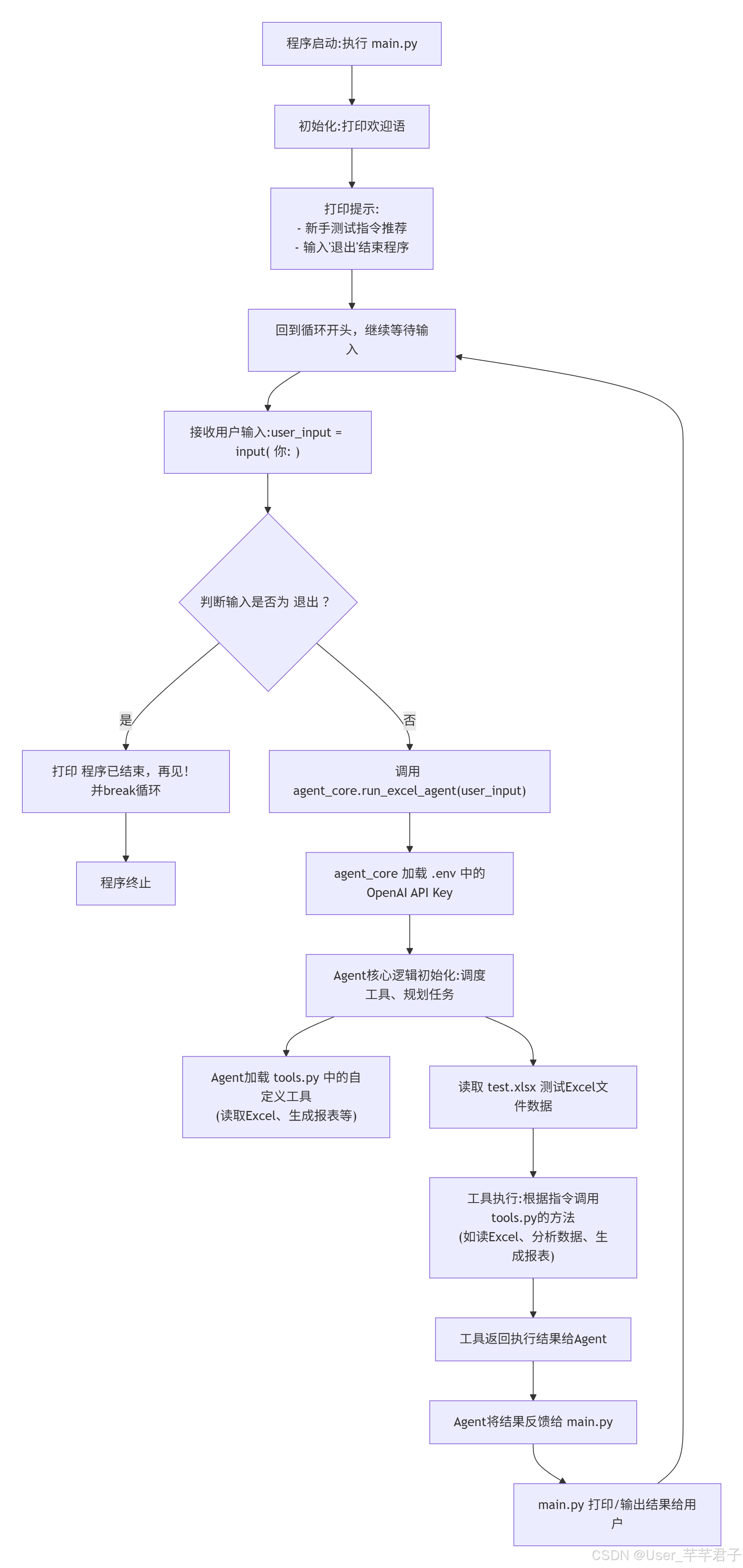
3.3.3 入口文件:main.py(运行Agent,新手直接运行)
简单的入口函数,运行后输入指令,即可让Agent自动处理Excel任务,代码如下:
from agent_core import run_excel_agent
if __name__ == "__main__":
print("🎉 Python+Excel处理Agent已启动!")
print("💡 新手测试指令推荐:读取当前目录下的test.xlsx文件,分析数据,生成报表,然后保存分析结果")
print("❌ 输入'退出'即可结束程序n")
while True:
user_input = input("你:")
if user_input == "退出":
print("👋 程序已结束,再见!")
break
# 运行Agent,执行用户指令
run_excel_agent(user_input)
from agent_core import run_excel_agent
if __name__ == "__main__":
print("🎉 Excel处理Agent已启动!")
print("💡 测试指令:读取test.xlsx,分析数据,生成报表并保存结果")
print("❌ 输入'退出'结束程序n")
while True:
user_input = input("你:")
if user_input == "退出":
print("👋 程序结束!")
break
run_excel_agent(user_input)
3.4 运行测试(新手必看,验证成果)
所有代码编写完成后,按以下步骤运行,验证Agent是否能正常工作,步骤如下:
-
在项目根目录(excel-agent)中,创建test.xlsx文件,填入测试数据(例如:姓名、年龄、成绩三列,10条数据);
-
打开终端,激活虚拟环境(参考2.2步骤,终端显示(agent-env));
-
进入项目根目录,输入命令:
python main.py; -
当出现“你:”时,输入测试指令:
读取当前目录下的test.xlsx文件,分析数据,生成报表,然后保存分析结果
3.5 成果验证(新手必做)
运行成功后,打开项目根目录,会看到3个新增文件:
-
agent_memory/:Chroma记忆模块存储的文件,记录Agent的操作历史;
-
report.png:生成的可视化报表(柱状图);
-
analysis_result.txt:保存的数据分析结果。
打开这3个文件,确认内容正确,就说明你的第一个Python+Agent智能体搭建成功了!
五、2026年Python+Agent新手进阶路线
搭建完第一个Agent后,可按以下路线进阶,逐步提升能力,贴合2026年技术趋势,避免盲目学习:
基础阶段(1-2周):熟练掌握本文的Excel处理Agent,能独立修改工具(如增加Excel筛选、排序功能),理解Agent的核心流程;
进阶阶段(2-4周):学习RAG检索增强技术,搭建本地知识库Agent(上传PDF、Word,实现智能查询),掌握多工具组合使用;
提升阶段(1-2个月):学习多Agent协作(用LangChain+AutoGen搭建多Agent团队),实现更复杂的任务(如办公自动化全流程);
实战阶段(长期):结合自身需求,开发实用Agent(如代码辅助Agent、客服Agent),尝试部署到服务器,实现24小时自动运行。
结尾:Python+Agent,新手也能抓住的AI风口
2026年,AI Agent的核心竞争力,不再是“会用框架”,而是“能用Python落地解决实际问题”。对于新手来说,无需畏惧复杂的技术概念,从一个简单的场景(如本文的Excel处理)入手,逐步积累经验,就能快速掌握Python+Agent的核心能力。
本文的代码可直接复制运行,新手可根据自身需求修改工具(如替换为处理Word、PDF的工具),实现个性化落地。如果在搭建过程中遇到问题,欢迎在评论区留言,我会逐一回复!
最后,整理了本文的核心代码、测试数据、进阶学习资料,关注我,后台回复“Python+Agent”,即可免费领取!
✨ 创作不易,收藏+点赞,后续持续更新2026年Python+Agent最新实战案例和进阶技巧!
© 版权声明
文章版权归作者所有,未经允许请勿转载。


