2026时序数据库选型全指南:大数据场景下的国产最优解,IoTDB实力领跑
在数字化转型全面深化的今天,工业物联网、智慧城市、智能电网、新能源监测等领域产生的时序数据呈现指数级爆发式增长。这类数据具备实时性强、产生频率高、数据量大、结构稳定且侧重时序查询的核心特征,传统关系型数据库早已无法承载其存储、查询与分析需求,时序数据库(Time-Series Database) 成为大数据架构中不可或缺的核心组件。
目录
一、时序数据库选型:企业必须关注的6大核心维度
二、国内外时序数据库市场格局:国产替代已成必然趋势
三、Apache IoTDB:专为时序数据打造的国产数据库王者
四、大数据场景下,IoTDB 为何是选型首选?
五、IoTDB 实战代码演示(SQL+Java)
六、Apache IoTDB 快速入门:下载与配置步骤
七、时序数据库选型,IoTDB 领跑国产,赋能大数据未来
对于企业而言,时序数据库的选型直接决定数据架构的稳定性、运维成本与业务拓展能力。面对市场上琳琅满目的时序数据库产品,如何结合自身业务场景、数据规模、技术栈完成精准选型?国产时序数据库能否替代国外产品?本文将从大数据选型核心维度出发,深度解析时序数据库选型逻辑,重点推荐国产顶尖时序数据库Apache IoTDB,为企业数字化选型提供权威参考。
一、时序数据库选型:企业必须关注的6大核心维度
时序数据的特殊性,决定时序数据库选型不能照搬传统数据库标准。结合大数据场景、工业物联网等高并发场景的实际需求,企业选型应重点聚焦以下6大核心维度:
1. 高吞吐写入能力
工业传感器、物联网设备每秒可产生数万甚至数百万条数据,时序数据库必须支持百万级TPS高并发写入,且写入延迟控制在毫秒级,避免数据堆积、丢失。这是时序数据库的核心基础能力,直接决定数据采集的完整性。
2. 海量数据存储与压缩效率
时序数据生命周期长、总量大,企业若采用低效存储方案,硬件成本将呈几何级增长。优秀的时序数据库需具备专属数据压缩算法,在不丢失数据精度的前提下,将压缩比提升至极致,同时支持PB级海量数据持久化存储,适配大数据长期存储需求。
3. 高效时序查询性能
时序数据的核心应用是按时间维度查询、聚合分析,如小时/天/月级数据统计、设备历史轨迹回溯、异常阈值监测等。数据库需针对时序查询做深度优化,支持毫秒级响应复杂聚合查询,支撑实时业务决策。
4. 轻量化与易扩展性
企业业务场景差异极大:小型场景仅需边缘端轻量化部署,大型集团需分布式集群横向扩展。优质时序数据库应兼顾边缘端轻量化与云端分布式扩展,支持单机、集群、边缘多部署模式,适配全场景业务。
5. 生态兼容与集成能力
大数据架构并非单一数据库支撑,需与Hadoop、Spark、Flink、Kafka等大数据组件无缝对接,同时支持工业协议、云平台集成。生态越完善,企业改造现有架构的成本越低,落地速度越快。
6. 开源安全与本土化服务
企业级应用对数据安全、技术支持要求极高。开源产品可降低 licensing 成本,本土化团队能提供快速响应的技术支持、定制化开发,避免国外产品“水土不服”、售后滞后的问题。
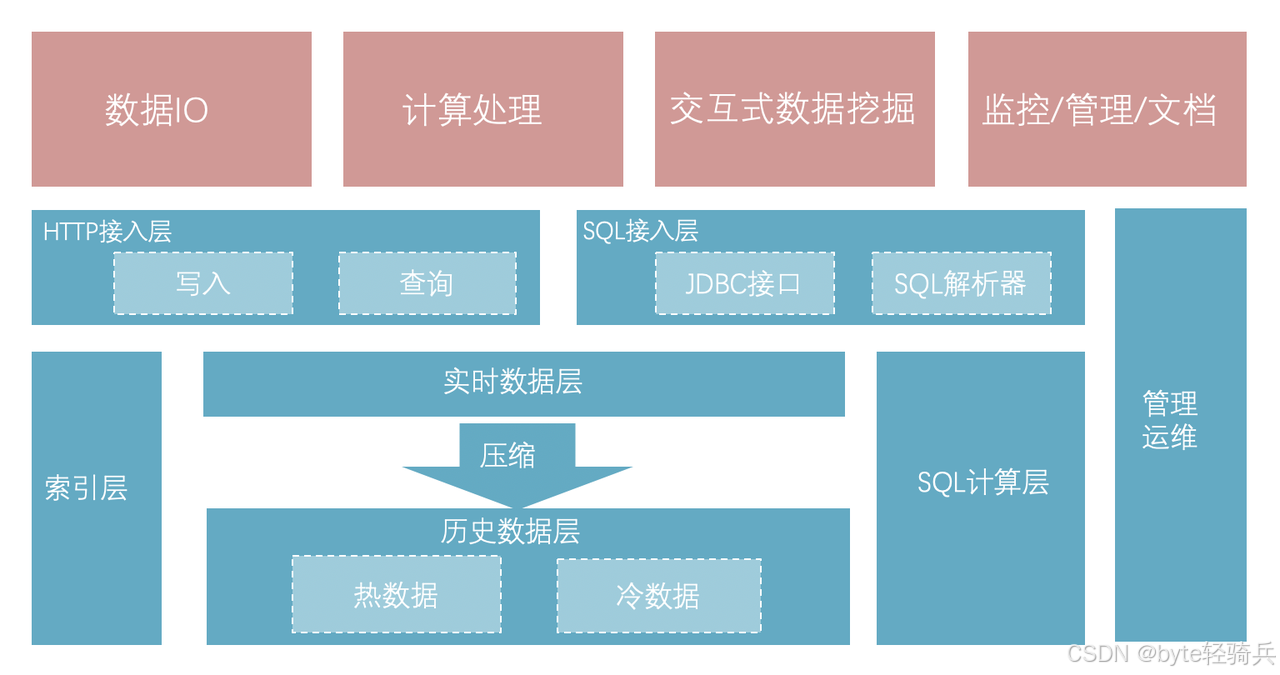
二、国内外时序数据库市场格局:国产替代已成必然趋势
早期时序数据库市场被国外产品垄断,凭借先发优势占据了部分市场份额。但随着国内大数据、物联网技术的飞速发展,国产时序数据库实现了技术弯道超车,在适配国内业务场景、本土化服务、成本控制等方面全面领先,国产替代成为企业选型的主流趋势。
国外时序数据库普遍存在三大痛点:一是部署复杂,对硬件、运维人员要求极高,中小企业难以落地;二是适配性差,针对欧美业务场景设计,无法满足国内工业物联网、智慧城市的定制化需求;三是服务滞后,远程技术支持响应慢,故障排查周期长,严重影响业务连续性。
而国产时序数据库扎根国内市场,深度贴合工业制造、能源电力、智慧城市等本土场景,从架构设计、功能开发到技术服务全链路适配企业需求,同时在性能上实现对标甚至超越国外产品,成为企业时序数据库选型的首选。
在众多国产时序数据库中,Apache IoTDB 凭借顶尖的技术实力、开源社区生态、全场景适配能力,成为行业公认的标杆产品,也是大数据场景下时序数据库选型的最优解。
三、Apache IoTDB:专为时序数据打造的国产数据库王者
Apache IoTDB 是由清华大学自主研发、捐赠给 Apache 软件基金会的顶级开源时序数据库,是国内首个物联网时序数据库 Apache 顶级项目,历经十余年技术沉淀,已广泛应用于工业物联网、能源、电力、轨道交通、智慧城市等数十个行业,服务上万企业级用户,成为国产时序数据库的领军者。

相较于市场上其他产品,Apache IoTDB 围绕时序数据核心需求,实现了写入、存储、查询、部署、生态五大维度的全面领先,完美匹配企业时序数据库选型的所有核心标准。
1. 极致写入性能:百万级并发无压力
针对物联网、大数据场景高并发写入需求,IoTDB 采用独创的时序数据写入引擎,支持每秒百万级数据点写入,写入延迟低至亚毫秒级。即使在工业传感器密集、数据爆发式产生的场景下,也能保证数据100%不丢失、不堆积,完美支撑实时数据采集需求。
同时,IoTDB 支持批量写入、异步写入、乱序数据处理,适配各类复杂写入场景,解决了传统数据库写入瓶颈的核心痛点。
2. 超高效存储:压缩比行业领先,成本直降90%
时序数据的存储成本是企业大数据架构的核心开支,IoTDB 针对时序数据特征研发了多层级自适应压缩算法,支持无损压缩与高精度有损压缩,平均压缩比可达10:1以上,部分场景最高可达50:1。
以工业企业为例,PB级时序数据采用 IoTDB 存储,硬件存储成本可直接降低90%,同时数据读写效率不受影响,真正实现“低成本、高容量”的存储需求。此外,数据库支持数据冷热分离存储,热数据存于内存快速访问,冷数据下沉至分布式文件系统,进一步优化存储成本。
3. 极速查询:毫秒级响应复杂分析
IoTDB 针对时序查询做了全链路优化,内置丰富的时序聚合函数(求和、平均值、最大值、最小值、方差等),支持按时间范围、设备ID、维度标签快速查询,单查询响应速度低至毫秒级。
即使是跨设备、跨时间段的大数据量聚合查询,也能快速返回结果,支撑企业实时数据监控、报表分析、异常预警等核心业务。同时,支持自定义查询函数,满足企业定制化分析需求。
4. 全场景部署:轻量化+分布式,适配所有业务
IoTDB 独创端边云一体化架构,是市面上极少数能同时满足边缘端轻量化部署与云端分布式集群扩展的时序数据库:
边缘端:安装包仅数十MB,占用内存低、资源消耗少,可部署在单片机、网关等边缘设备,实现边缘数据本地存储与预处理;
云端:支持分布式集群横向扩展,可无缝扩展至数百节点,承载PB级海量数据,满足大型集团、大数据平台的规模化需求。
这种全场景部署能力,让企业无需为不同场景采购多个数据库,一套 IoTDB 即可覆盖所有业务,大幅降低架构复杂度与运维成本。
5. 全生态兼容:无缝对接大数据组件,零成本集成
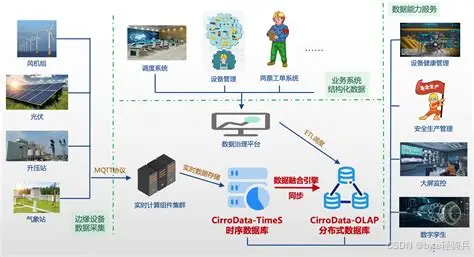
IoTDB 深度融入大数据生态,完美兼容 Hadoop、Spark、Flink、Kafka、Elasticsearch 等主流大数据组件,支持实时数据同步、离线计算、流式处理、数据可视化等全流程操作。
同时,支持 MQTT、Modbus 等工业物联网协议,支持对接各类云平台、可视化工具,企业现有大数据架构无需大规模改造,即可快速集成 IoTDB,实现业务快速落地。
6. 开源安全+本土化服务:企业级保障无后顾之忧
IoTDB 是完全开源的 Apache 顶级项目,无商业 licensing 费用,企业可自由使用、修改、分发,大幅降低技术成本。同时,由国内专业团队提供7×24小时本土化技术支持,提供定制化开发、故障排查、架构优化等服务,解决企业使用过程中的所有问题。
相较于国外产品,IoTDB 无数据安全隐患,符合国内数据合规要求,是企业级应用的安全首选。
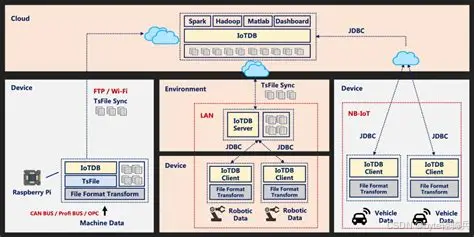
四、大数据场景下,IoTDB 为何是选型首选?
在大数据时代,时序数据的核心诉求是海量、实时、高效、低成本,IoTDB 从底层架构设计上就贴合大数据场景需求,成为大数据时序数据库选型的不二之选:
适配大数据海量存储:支持PB级数据存储,冷热分离架构,完美解决大数据长期存储成本问题;
支撑高并发实时处理:百万级写入、毫秒级查询,适配大数据实时采集、实时分析需求;
无缝融入大数据生态:与主流大数据组件无缝对接,无需额外开发,快速构建大数据时序数据平台;
分布式扩展能力:支持集群横向扩展,随业务数据增长灵活扩容,适配大数据业务规模化发展。
无论是中小企业的轻量化场景,还是大型企业的PB级大数据平台,IoTDB 都能提供最优的时序数据解决方案,真正做到“一套数据库,满足全场景”。
五、IoTDB 实战代码演示(SQL+Java)
IoTDB 最大的优势之一就是完全兼容类SQL语法,学习成本极低,同时提供Java、Python等多语言SDK,企业开发可快速接入。以下是生产环境常用实战代码:
1. 基础SQL操作(客户端直接执行)
-- 1. 创建存储组(对应数据库概念)
SET STORAGE GROUP TO root.light.device;
-- 2. 创建时序序列(设备+传感器+数据类型)
CREATE TIMESERIES root.light.device.temperature WITH DATATYPE=FLOAT, ENCODING=GORILLA;
CREATE TIMESERIES root.light.device.humidity WITH DATATYPE=INT32, ENCODING=TS_2DIFF;
CREATE TIMESERIES root.light.device.voltage WITH DATATYPE=FLOAT, ENCODING=GORILLA;
-- 3. 插入单条时序数据
INSERT INTO root.light.device(timestamp, temperature, humidity, voltage) VALUES (1741584000000, 25.6, 45, 220.5);
-- 4. 批量插入数据(高性能写入)
INSERT INTO root.light.device(timestamp, temperature, humidity, voltage)
VALUES
(1741584001000, 26.1, 44, 221.2),
(1741584002000, 25.9, 46, 220.8),
(1741584003000, 26.3, 43, 219.9);
-- 5. 全量查询数据
SELECT * FROM root.light.device;
-- 6. 按时间范围查询(核心时序查询)
SELECT temperature, humidity FROM root.light.device WHERE time >= 1741584000000 AND time <= 1741584003000;
-- 7. 时序聚合查询(小时级统计)
SELECT AVG(temperature), MAX(humidity), MIN(voltage) FROM root.light.device
GROUP BY time(1h);
-- 8. 数据删除(按时间范围)
DELETE FROM root.light.device WHERE time < 1741584000000;2. Java 代码集成(生产环境常用)
import org.apache.iotdb.session.pool.SessionPool;
import org.apache.iotdb.tsfile.read.common.RowRecord;
import java.util.Arrays;
public class IoTDBDemo {
public static void main(String[] args) {
// 1. 初始化连接池(高并发推荐)
SessionPool sessionPool = new SessionPool.Builder()
.host("127.0.0.1")
.port(6667)
.user("root")
.password("root")
.maxSize(10)
.build();
try {
// 2. 批量插入数据(高性能)
String deviceId = "root.light.device";
String[] measurements = {"temperature", "humidity", "voltage"};
long[] times = {1741584004000L, 1741584005000L, 1741584006000L};
Object[] values = {26.5f, 42, 220.0f};
sessionPool.insertRecord(deviceId, times[0], measurements, values);
System.out.println("数据插入成功!");
// 3. 执行查询
String sql = "SELECT temperature FROM root.light.device WHERE time >= 1741584000000";
sessionPool.executeQueryStatement(sql);
// 4. 解析结果
RowRecord record;
while ((record = sessionPool.getResultSet().next()) != null) {
System.out.println("时间:" + record.getTimestamp() + " 温度:" + record.getFields().get(0));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
sessionPool.close();
}
}
}3. 大数据Flink集成代码(核心场景)
// Flink-IoTDB 流式写入核心代码
DataStream<TimeseriesData> dataStream = ...; // 实时数据流
dataStream.addSink(
IoTDBSinkBuilder.builder()
.host("127.0.0.1")
.port(6667)
.user("root")
.password("root")
.batchSize(1000) // 批量写入优化
.build()
);六、Apache IoTDB 快速入门:下载与配置步骤
对于企业和开发者而言,IoTDB 部署简单、易上手,以下是详细的下载与基础配置步骤,零基础也能快速完成部署:
第一步:下载 Apache IoTDB
官方提供稳定版、开发版下载,企业生产环境推荐使用稳定版,直接访问官方下载地址即可获取:
✅ Apache IoTDB 官方下载链接:https://iotdb.apache.org/zh/Download/
下载页面支持 Windows、Linux、macOS 多系统版本,同时提供单机版、集群版,根据自身业务场景选择对应版本下载。
第二步:环境准备
IoTDB 基于 Java 开发,部署前需确保环境已安装 JDK 8 及以上版本:
-
检查 Java 环境:打开终端/命令提示符,输入
java -version,若显示版本信息则说明环境正常; -
若未安装,可前往 Oracle 或 OpenJDK 官网下载安装,配置环境变量即可。
第三步:单机版部署(新手首选)
-
解压下载的 IoTDB 压缩包,得到解压文件夹;
-
Windows 系统:双击
sbin/start-standalone.bat启动服务;
Linux/macOS 系统:终端进入解压目录,执行 ./sbin/start-standalone.sh 启动服务;
-
启动成功后,控制台显示「IoTDB is started successfully」即完成部署。
第四步:基础配置优化
-
配置文件路径:
conf/iotdb-engine.properties,可修改端口号、数据存储路径、内存占用等参数; -
数据存储配置:修改
data_dir参数,自定义数据存储目录,避免系统盘占用; -
写入优化:调整
write_memory_size参数,根据服务器内存配置写入缓存,提升写入性能。
第五步:连接与使用
-
使用官方客户端工具:执行
sbin/start-cli.bat(Windows)或./sbin/start-cli.sh(Linux)连接数据库; -
支持 SQL 语法操作,创建时间序列、插入数据、查询数据均与传统数据库操作一致,学习成本极低;
-
企业级可视化管理、集群部署、高级配置,可参考官方文档,或联系技术团队获取支持。
对于需要企业级功能、专属服务的用户,可访问 IoTDB 企业版官网,获取定制化解决方案、技术支持与运维服务:
✅ Apache IoTDB 企业版官网:https://timecho.com
七、时序数据库选型,IoTDB 领跑国产,赋能大数据未来
时序数据库是大数据、物联网时代的核心基础设施,选型的合理性直接决定企业数据架构的成败。从选型核心维度来看,高吞吐、高压缩、高效查询、全场景部署、全生态兼容、本土化服务是企业必须关注的重点。
Apache IoTDB 作为国产时序数据库的标杆产品,凭借顶尖的技术性能、全场景适配能力、完善的开源生态与本土化服务,完美解决了企业时序数据存储、查询、分析的核心痛点,不仅对标甚至超越国外同类产品,更贴合国内企业业务需求,是大数据场景下时序数据库选型的最优选择。
从工业制造到新能源,从智慧城市到智能电网,IoTDB 已凭借实力赢得上万企业的信赖。在国产替代的大趋势下,选择 Apache IoTDB,就是选择稳定、高效、低成本的时序数据解决方案,为企业数字化转型与大数据业务发展筑牢根基。
© 版权声明
文章版权归作者所有,未经允许请勿转载。