
从“吐槽”到“交付”——我是如何协同 AI 撸出一个 Spark 性能分析工具的(上)
写在前面: 这是一个后端开发者的真实实验。
在不到 3 周的碎片时间里,我协同 AI 撸出了一个完整的 Spark 性能分析工具,并实现了以下硬核突破:
- 跨越 10 年前端断层:从 jQuery 时代直接跨越到 Vue3 工程化。
- 24 倍性能救赎:通过架构重构,将 2GB 日志的处理时间从 2 小时缩减至 5 分钟。
- 输出专家级诊断:将“老司机”的调优直觉转化为稳定的规则评分体系。
于是,我把 Gemini CLI 变成了我的“全栈副驾”,带你看看这套“吐槽驱动开发”的真实过程。它既是我随时可以求助的专家,又是帮我不知疲倦干活的员工。
1. 契机:一个后端开发的“现代前端断层”
说来惭愧,我的前端认知几乎封存在了 10 年前。那时候,jQuery 还是王者,Bootstrap 和 EasyUI 意味着“高级感”。
作为一个常年深耕 Spark 后端的 Java 程序员,我习惯了类型安全和严谨的逻辑,但面对现代前端的“原始丛林”——那些层出不穷的 npm, vite, node_modules 以及让人眼花缭乱的响应式状态管理——我感到了深深的无力。
我有满脑子的调优经验,想做一个能一键生成诊断报告的工具。但每次想到要为了一个工具去研究如何配置 Vite 环境、如何处理组件间通信,那种**“为了喝口奶而去养头牛”**的疲惫感就会劝退我。直到我遇到了 AI,我想看看它能不能帮我接上这 10 年的技术断层,把那个躺在草稿纸上的想法变成现实。
2. 第一步:我出策略,AI 拉起防线
我的选型逻辑非常直接,甚至带着一点后端程序员的“傲慢”:
- 后端必须是 Spring Boot (Java 21):这是我的舒适区,也是我进行代码审计(Code Review)的主战场。
- 前端选 Vue3:虽然我不懂,但我信任它的生态和低维护成本。
我给 AI 下的第一道指令,更像是一场**“战略对齐”**:
“我要做一个 Spark 监控工具,定位是单机运行的分析助手。请帮我拉起一个工程骨架。记住,我不想在环境配置上浪费一秒钟,我需要你屏蔽掉那些杂音,让我直接开始业务逻辑。”
惊艳的瞬间发生了: AI 并没有抛给我一堆文档,它像一个高效的架构组,直接吐出了完整的工程目录。看着那个通过 Vite 秒级启动的页面,我意识到:AI 帮我完成了一次技术跨越,它把复杂的工程黑盒变成了一个透明的业务画布。
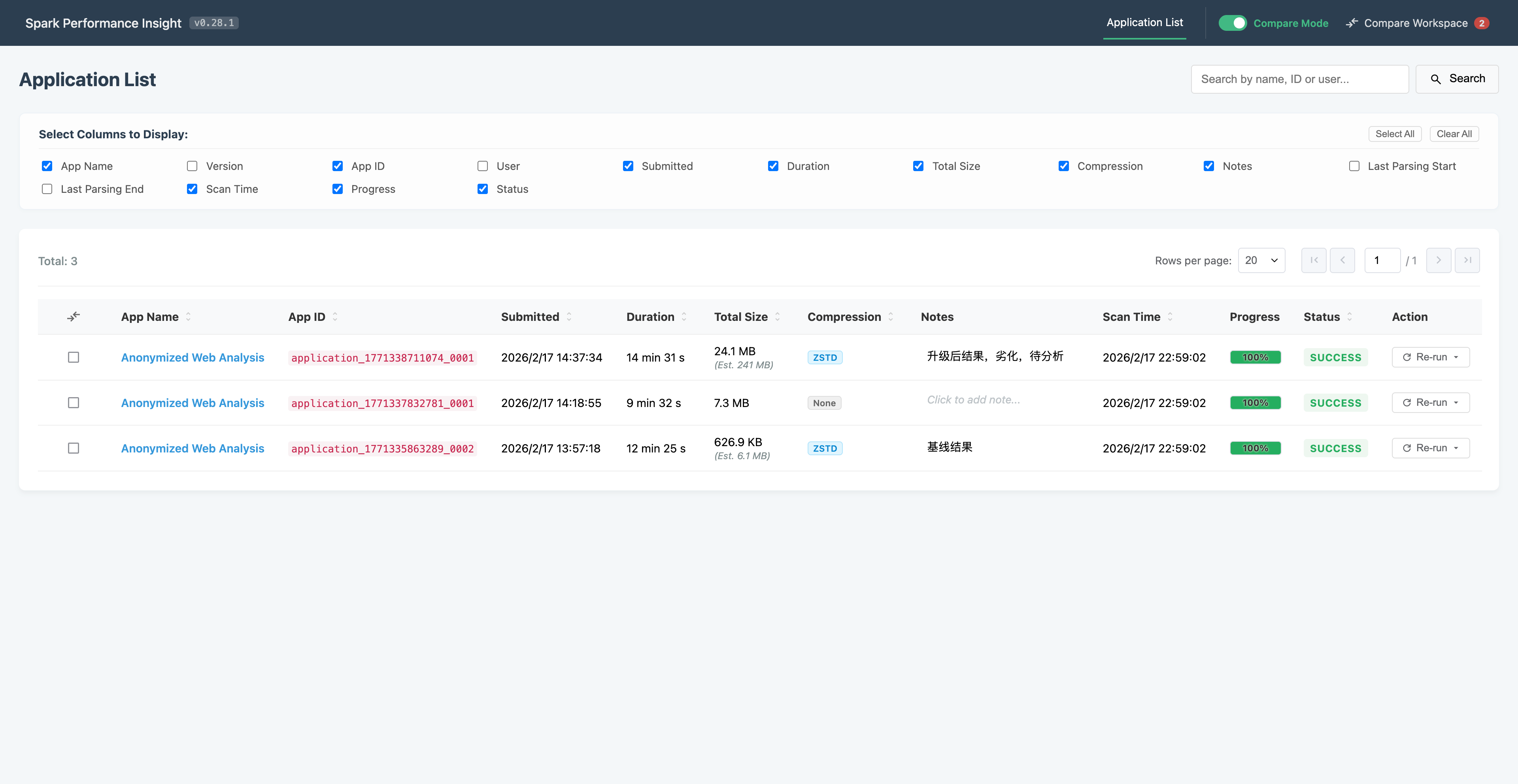
3. 协作博弈:在“惊艳”与“智障”的边缘横跳
协作进入深水区后,我与 AI 的关系开始变得“微妙”。
惊喜:Gemini Pro 简直是“表格收割机”
处理常见的 UI 元素时,它表现得异常老练。我只需描述:“我想要个能多列排序、支持前端分页和动态筛选的表格”,通常 2-3 轮对话,它就能交出几乎完美的 Vue3 组件。
注:这里一定要用高阶模型(如 Pro),低阶模型(如 Flash)在处理复杂逻辑时极易产生理解代差,导致无休止的返工。
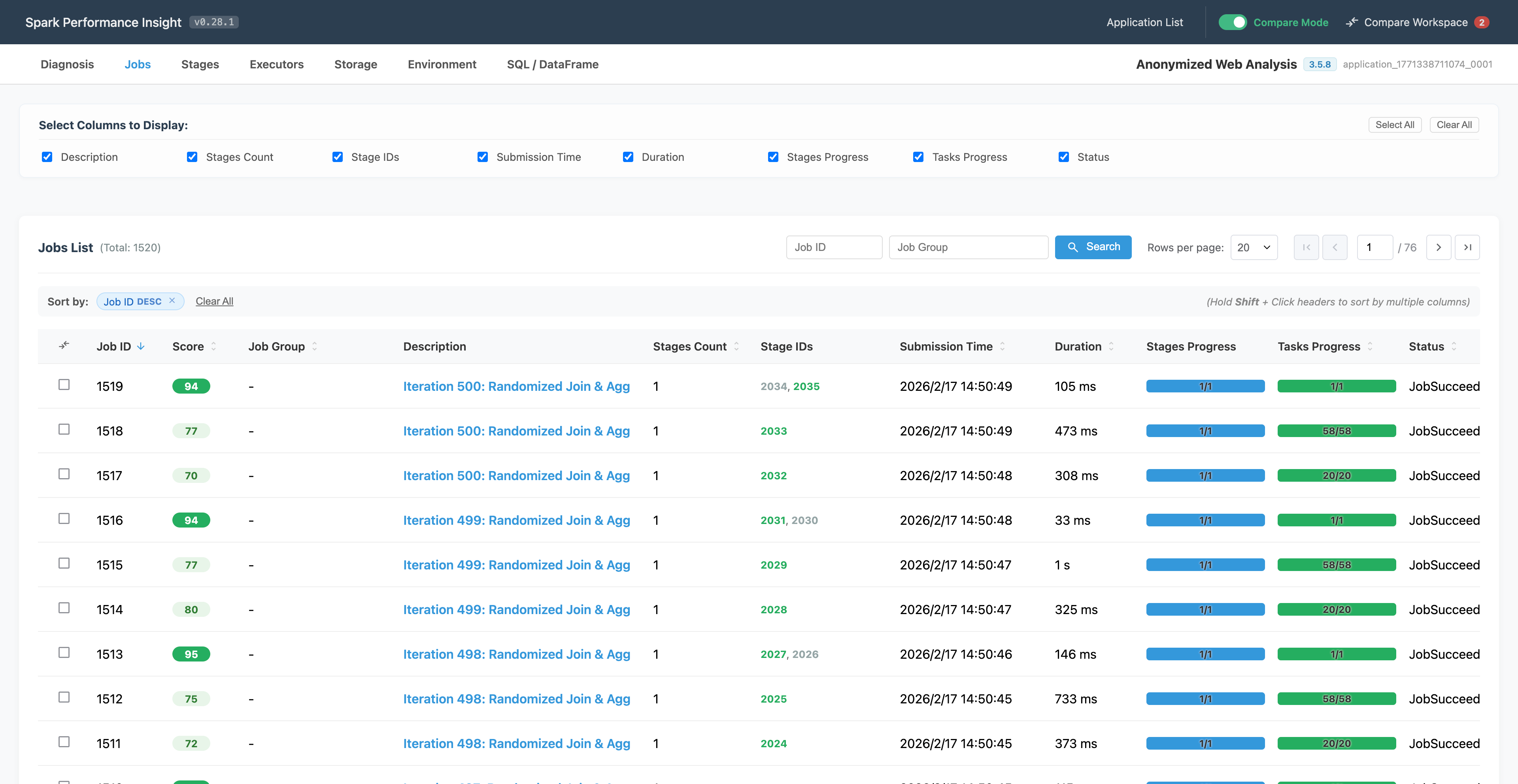
挫折:AI 的“温床”与“死角”
然而,当我试图复刻 Spark UI 经典的 Event Graph(事件图) 时,AI 彻底翻车了。无论我如何细腻地描述 DAG 逻辑,它始终无法还原那种复杂的交互感。这让我意识到:AI 目前只能替代重复性的“砌砖”,对于高度自定义的精细交互,高级前端的直觉依然是不可替代的。
立规矩:建立“生存契约” GEMINI.md
为了防止 AI 在建模上“能跑就行”的惰性,我专门建立了 GEMINI.md。这里记录了我的技术底线:不准在指标表里塞原始信息、代码风格必须符合 Java 21 规范、甚至激进到“不考虑历史兼容,改 Schema 就重写”。
AI 负责效率,你负责底线。如果不坚持架构审计,它会带你走向代码腐烂的深渊。
4. 进化:从“输出智慧”到“双轨诊断”
搭好 UI 只是第一步,我的终极目标是:让 AI 像顶级专家一样,直接告诉我调优答案。
为了达成这个目标,我与 AI 进行了一次深度的**“逆向工程”**。我们没有直接从解析日志开始写代码,而是从最终的“诊断报告”倒推数据库建模:
-
终极目标:系统需要给出一行具体的参数建议(例如:将
spark.sql.shuffle.partitions设为 2000)。 - 支撑逻辑:为了给出这个结论,AI 必须有理有据地识别出“数据倾斜”或“Shuffle 瓶颈”。
- 底层食材:要支撑 AI 的判断,我们的数据库中就必须有一张高度提炼的宽表,存储着每个 Stage 的 P95 耗时、Shuffle 读写分布、GC 时间占比等硬核指标。
一鱼两吃:指标的“分层收割”
在这个从结果倒推的逻辑下,我与 AI 共同建模了一套**“九宫格指标体系”**。在构建这套指标的过程中我突然想到,这些数据其实可以“一鱼两吃”,完美兼顾不同段位的受众:
-
喂养 AI(给初学者的保姆级药方):
我们将这 9 个精炼后的结构化指标作为 Prompt 的上下文喂给大模型。因为输入的数据极其精准,AI 终于告别了“建议检查网络”之类的正确废话,开始输出带有明确参数调整的深度诊断。对于初学者来说,这就是一份可以直接照着操作的“武功秘籍”。

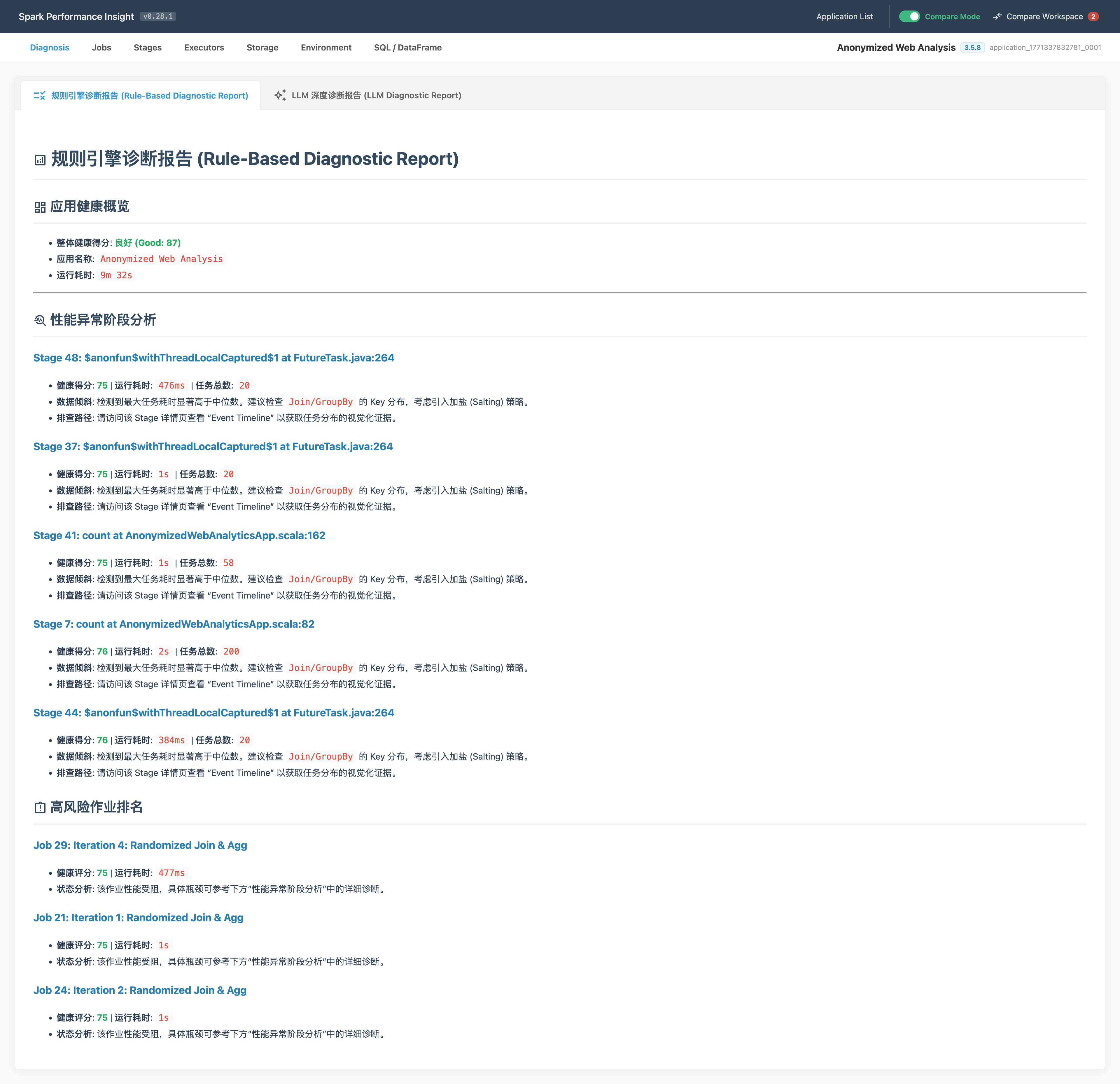
2. “红绿灯”系统(给专家的提效礼物):
但我系统的受众不能只有初学者,我还想吸纳资深专家。我深知,专家往往有自己的骄傲,他们可能不完全迷信 AI 的文字总结,但他们极度渴求**“分析的加速度”。于是,我让 AI 在前端将这 9 个指标转化为直观的红、黄、绿三色灯**,并支持全列表的多维排序。对于专家而言,这就是一张排雷地图:他们不再需要在数千个 Stage 的原生 UI 里盲目翻找,红灯一闪,直接切入核心战场。

稳定的规则引擎是基石,灵动的 AI 诊断是天花板。 这种“双轨制”不仅规避了 AI 可能产生的幻觉,更让这个工具同时成为了初学者的“导师”和专家的“雷达”。
5. 性能地狱:从 2 小时到 5 分钟的自我救赎
所有的美好幻想,在我第一次导入公司生产环境的 2GB 真实日志时,碎了一地。在原有的 Jackson 解析逻辑下,处理完这个大家伙竟然要 2 个小时。这哪是监控工具?这简直是“考古工具”。
第一回合:典型的多线程思维误区
我第一反应是让 AI 写一个经典的生产者-消费者模式:单线程读文件,利用阻塞队列实现多线程解析并分发入库。AI 执行力极强,代码写得很漂亮,但实测效果微乎其微。瓶颈根本不在解析逻辑,而在数据库写入的 IO 吞吐量。
第二回合:AI 的“专家人设”带我破局
在几轮激烈的“吐槽”后,我决定发挥 AI 的“专家”能力,而不是把它当“打字员”。基于对 DuckDB 底层特性和 Java 交互的深刻理解,AI 给了我一个极具震撼力的建议:彻底抛弃 Jackson 逐行解析,拥抱 DuckDB 极其硬核的原生 JSON 扫描与导入能力。
这几乎意味着要推翻我之前所有的解析逻辑。但我决定赌一把:
-
架构重构:干掉原有的 MyBatis + Jackson 解析流,拥抱 DuckDB 的原生
read_json_auto进行暴力入库。 - 奖章架构(Medallion Architecture):引入 Bronze(原始 JSON 导入)、Silver(预计算指标)、Gold(面向 UI 展示)的三层数仓体系。
结果:处理时间从 2 小时直接快进到了 5 分钟。
这不只是代码的修补,而是架构级的降维打击。这就是 AI 的魅力——它既是帮你干活的员工,又是能根据你描述的瓶颈,随时切换到顶级专家视角帮你破局的副驾。
6. 深度复盘:AI 到底是开发者的什么?
在这 3 周的“混合双打”中,我最深刻的感悟是:使用 AI 的人,必须是一个“挑剔”且“有品位”的人。
普通人以为自己知道想要什么,程序员以为自己知道用户想要什么。但事实上,如果开发者缺乏产品经理的嗅觉,他根本无法捕捉到那些让系统“难用”的微小槽点;如果没有项目经理的全局观,他极易陷入某个局部细节的死磕,而导致整个项目难产。
在 AI 协作模式下,我的角色发生了剧烈的位移:
- 作为产品经理:我必须保持极高的“审美门槛”,敏锐地定义出什么是“平庸的方案”,什么是“惊艳的洞察”。
- 作为项目经理:我得学会“抓大放小”,清晰地知道什么时候该死磕 DuckDB 性能,什么时候该接受一个不那么完美的 UI 细节,以确保里程碑目标的达成。
- 作为架构师/Commiter:我负责守住最后一道防线,不让 AI 的“能跑就行”演变成代码的灾难。
AI 并不是在替代我,它更像是我的多重身份在数字世界的延伸。 它补齐了我的手(代码实现),而我必须赋予它灵魂(品位与决策)。
逻辑思维比语法记忆更重要,需求定义比代码编写更关键。
7. 收官:磨刀不误砍柴工
在发布前,我还顺手和 AI 磨出了两个专属“武器”:
- Release Skill:自动写 Changelog、更新版本号,给每个里程碑“打结”。
- Commit Skill:让代码提交变得优雅。
这种“边开发、边磨合、边造工具”的过程,让我感觉自己是在运营一个自动化的软件工厂。最后,我们将 Spark-Performance-Insight 正式发布到了 GitHub。
结语:别再让你的好想法吃灰
不要焦虑被 AI 替代,要焦虑你是否还有“吐槽”的能力。如果你也有一个尘封已久的想法,请现在就开始。
我只用了不到 3 周的碎片时间,就完成了这个从 0 到 1、从后端到前端、从解析到诊断的完整项目。找一个好用的 AI 工具,从“吐槽”你的需求开始,你会发现,那个困扰你多年的技术断层,其实只需几轮高质量对话就能接上。
下一个项目,我已经准备好了。你呢?
写在最后
如果你也对 Spark 性能调优感兴趣,或者想看看我和 AI 共同完成的成果,欢迎访问我的 GitHub 项目:
👉 Spark-Performance-Insight (中文 README)
如果这个项目对你有启发,欢迎点个不要钱的 Star ⭐。也欢迎在 Issue 中提出你的想法,我们一起交流探讨!
© 版权声明
文章版权归作者所有,未经允许请勿转载。


