给 AI 装上长期记忆:Zep Cloud 初探与上手教程
在构建智能对话系统时,记忆 是一个至关重要的能力。一个 AI 助手如果每次都从零开始对话,而无法记住用户的历史偏好、兴趣和上下文,就很难被认为是「智能」的。
Zep 正是为了解决这一问题的工具,它提供了长期记忆(long-term memory) 的能力,让 AI 可以像人类一样,在多轮交互中逐渐形成对用户的理解。
这篇文章会结合一些示例代码,带大家对 Zep 的长期记忆 有一个初步的认识。
1. 环境准备
使用 Zep 之前,需要先获取 API Key,Zep – AI Memory for Applications
并通过环境变量配置:
from dotenv import load_dotenv
import os
# 加载 .env 文件
load_dotenv(override=True)
# 获取 ZEP API Key
ZEP_API_KEY = os.getenv("ZEP_API_KEY")
安装依赖:
pip install python-dotenv zep-cloud
然后通过 Zep 客户端与 Zep 服务交互:
from zep_cloud.client import Zep
client = Zep(api_key=ZEP_API_KEY)
2. 用户的管理
在长期记忆中,用户(User) 是最核心的对象。Zep 提供了用户的增删改查功能,比如:
-
添加用户:
def add_user(user_id, email, first_name, last_name):
"""添加一个新用户"""
user = client.user.add(
user_id=user_id,
email=email,
first_name=first_name,
last_name=last_name,
)
print(f"✅ 用户 {user_id} 已创建:", user)
return user-
获取用户信息:
def get_user(user_id):
"""获取用户信息"""
user = client.user.get(user_id)
print("ℹ️ 用户信息:", user)
return user
通过这些接口,Zep 可以为每个用户维护独立的记忆空间,避免不同用户之间的干扰。
3. 会话与线程(Thread)
Thread 可以理解为某个用户与 AI 的对话会话,它是记忆的载体。
我们可以为用户创建一个新的对话线程:
import uuid
def create_thread(user_id):
"""为用户创建新的对话线程"""
thread_id = uuid.uuid4().hex
client.thread.create(thread_id=thread_id, user_id=user_id)
print("🆕 新建线程:", thread_id)
return thread_id在这个会话中,用户和 AI 的消息都会被存储,逐渐形成长期记忆。
4. 向 Zep 添加记忆
当用户和 AI 进行对话时,我们可以把消息存储到 Zep 中。例如:
def add_memory(user_id, bot_id, thread_id, user_message, bot_message):
"""将用户和 AI 的对话存入记忆"""
messages = [
Message(name=user_id, role="user", content=user_message),
Message(name=bot_id, role="assistant", content=bot_message),
]
client.thread.add_messages(thread_id, messages=messages)
print(f"💾 已存入记忆: {user_message} -> {bot_message}")比如,用户说「我想学习 Python」,AI 回复「好的,我来教你一些基础代码」,这段信息就会被 Zep 存储起来。
5. 从 Zep 中检索记忆
Zep 的强大之处在于,它不只是单纯的对话存档,而是提供了结构化的长期记忆检索能力。
例如,我们可以通过以下方式获取某个对话线程的上下文摘要:
def get_user_context(thread_id, mode="summary"):
"""获取用户上下文(支持 summary/basic 两种模式)"""
memory = client.thread.get_user_context(thread_id=thread_id, mode=mode)
print(f"📌 用户上下文({mode}):n", memory.context)
return memory.contextZep 会自动对历史对话进行摘要,提取用户的偏好和事实,从而在后续对话中帮助 AI 更好地理解用户。
同时,Zep 还支持基于 知识图谱(graph) 的检索,可以通过 search_in_graph 或 get_relevant_fact 找到和用户相关的事实和关系。这使得 AI 不仅能记住对话,还能推理出用户的兴趣、习惯和事实网络。
6. 一个简单的完整的例子
import os
import uuid
from dotenv import load_dotenv
from zep_cloud.client import Zep
from zep_cloud import Message
# ======================
# 1. 初始化 Zep 客户端
# ======================
load_dotenv(override=True)
ZEP_API_KEY = os.getenv("ZEP_API_KEY")
client = Zep(api_key=ZEP_API_KEY)
# ======================
# 2. 用户管理
# ======================
def add_user(user_id, email, first_name, last_name):
"""添加一个新用户"""
user = client.user.add(
user_id=user_id,
email=email,
first_name=first_name,
last_name=last_name,
)
print(f"✅ 用户 {user_id} 已创建:", user)
return user
def get_user(user_id):
"""获取用户信息"""
user = client.user.get(user_id)
print("ℹ️ 用户信息:", user)
return user
# ======================
# 3. 会话管理(Thread)
# ======================
def create_thread(user_id):
"""为用户创建新的对话线程"""
thread_id = uuid.uuid4().hex
client.thread.create(thread_id=thread_id, user_id=user_id)
print("🆕 新建线程:", thread_id)
return thread_id
# ======================
# 4. 添加记忆
# ======================
def add_memory(user_id, bot_id, thread_id, user_message, bot_message):
"""将用户和 AI 的对话存入记忆"""
messages = [
Message(name=user_id, role="user", content=user_message),
Message(name=bot_id, role="assistant", content=bot_message),
]
client.thread.add_messages(thread_id, messages=messages)
print(f"💾 已存入记忆: {user_message} -> {bot_message}")
# ======================
# 5. 获取长期记忆摘要
# ======================
def get_user_context(thread_id, mode="summary"):
"""获取用户上下文(支持 summary/basic 两种模式)"""
memory = client.thread.get_user_context(thread_id=thread_id, mode=mode)
print(f"📌 用户上下文({mode}):n", memory.context)
return memory.context
# ======================
# 6. 演示流程
# ======================
if __name__ == "__main__":
# 定义两个用户:human user 和 bot
user_id = "harry_user"
bot_id = "ai_bot"
# 创建用户
add_user(user_id, "harry@example.com", "Harry", "Liu")
add_user(bot_id, "bot@example.com", "AI", "Assistant")
get_user(user_id)
get_user(bot_id)
# 创建对话线程(以 human user 为主)
thread_id = create_thread(user_id)
# 模拟一次对话
user_msg = "Hi, my name is Harry. I love watching movies and learning Python."
bot_msg = "Nice to meet you Harry! 🎬🐍 Movies and Python are both great choices!"
add_memory(user_id, bot_id, thread_id, user_msg, bot_msg)
# 再来一次对话
user_msg2 = "I want to learn Python basics, please teach me."
bot_msg2 = "Sure! Let's start with printing text:n```pythonnprint('Hello, Harry!')n```"
add_memory(user_id, bot_id, thread_id, user_msg2, bot_msg2)
# 获取用户记忆摘要
get_user_context(thread_id, "summary")
get_user_context(thread_id, "basic")
执行结果
✅ 用户 harry_user 已创建: created_at='2025-08-23T03:25:14.843616Z' deleted_at=None email='harry@example.com' fact_rating_instruction=None first_name='Harry' id=35 last_name='Liu' metadata=None project_uuid='ff41087d-e0f6-496d-8cea-e2e05be96d20' session_count=None updated_at='2025-08-23T03:25:14.843616Z' user_id='harry_user' uuid_='19a1bc52-102c-4610-8941-63bda6979204'
✅ 用户 ai_bot 已创建: created_at='2025-08-23T03:25:15.208405Z' deleted_at=None email='bot@example.com' fact_rating_instruction=None first_name='AI' id=36 last_name='Assistant' metadata=None project_uuid='ff41087d-e0f6-496d-8cea-e2e05be96d20' session_count=None updated_at='2025-08-23T03:25:15.208405Z' user_id='ai_bot' uuid_='9d915a28-0b54-4b09-b6f6-eebd1c5fc3d7'
ℹ️ 用户信息: created_at='2025-08-23T03:25:14.843616Z' deleted_at=None email='harry@example.com' fact_rating_instruction=None first_name='Harry' id=35 last_name='Liu' metadata=None project_uuid='ff41087d-e0f6-496d-8cea-e2e05be96d20' session_count=None updated_at='2025-08-23T03:25:14.843616Z' user_id='harry_user' uuid_='19a1bc52-102c-4610-8941-63bda6979204'
ℹ️ 用户信息: created_at='2025-08-23T03:25:15.208405Z' deleted_at=None email='bot@example.com' fact_rating_instruction=None first_name='AI' id=36 last_name='Assistant' metadata=None project_uuid='ff41087d-e0f6-496d-8cea-e2e05be96d20' session_count=None updated_at='2025-08-23T03:25:15.208405Z' user_id='ai_bot' uuid_='9d915a28-0b54-4b09-b6f6-eebd1c5fc3d7'
🆕 新建线程: b4cfdfa942f34c768e2b4348c31d32d9
💾 已存入记忆: Hi, my name is Harry. I love watching movies and learning Python. -> Nice to meet you Harry! 🎬🐍 Movies and Python are both great choices!
💾 已存入记忆: I want to learn Python basics, please teach me. -> Sure! Let's start with printing text:
```python
print('Hello, Harry!')
```
📌 用户上下文(summary):
• Harry Liu introduced himself as someone who loves watching movies and learning Python (2024-12-19 - 2024-12-19)
• Harry Liu requested to learn Python basics (2024-12-19 - 2024-12-19)
• AI bot provided first Python instruction: print('Hello, Harry!') (2024-12-19 - 2024-12-19)
• Harry Liu's user profile includes email harry@example.com and user_id harry_user (2024-12-19 - 2024-12-19)
📌 用户上下文(basic):
FACTS and ENTITIES represent relevant context to the current conversation.
# These are the most relevant facts and their valid date ranges
# format: FACT (Date range: from - to)
<FACTS>
- ai_bot is teaching Harry Python basics. (2025-08-23 03:25:17 - present)
- Harry wants to learn Python basics. (2025-08-23 03:25:17 - present)
- Harry Liu loves learning Python (2025-08-23 03:25:17 - present)
- ai_bot thinks Python are great choices (2025-08-23 03:25:17 - present)
- Harry Liu loves watching movies (2025-08-23 03:25:17 - present)
</FACTS>
# These are the most relevant entities
# Name: ENTITY_NAME
# Label: entity_label (if present)
# Attributes: (if present)
# attr_name: attr_value
# Summary: entity summary
<ENTITIES>
- Name: Python basics
Label: Topic
Attributes:
domain: Python
expertise_level: basics
Summary: Harry wants to learn Python basics.
</ENTITIES>7. 知识图谱搜索(Graph Search)
在前面的例子里,我们通过 user_context 可以快速拿到用户的摘要信息。但在更复杂的 RAG 问答 场景下,仅靠摘要可能不够精确。这时候,Zep 提供的 知识图谱搜索(Graph Search)就派上用场了。
为什么需要知识图谱?
-
精确检索用户事实:比如用户喜欢的编程语言、职业、同事关系等。
-
关系推理:例如“Harry 和谁是同事?”、“他在哪家公司工作?”。
-
复杂问题处理:多个实体、多关系组合的问题。
图搜索代码示例
def search_in_graph(user_id, query_text, center_node_uuid=None):
"""
在 Zep 知识图谱中搜索与 query_text 相关的节点或事实
"""
client = Zep(api_key=ZEP_API_KEY)
if center_node_uuid:
results = client.graph.search(
user_id=user_id,
query=query_text,
reranker="node_distance",
center_node_uuid=center_node_uuid # 可选,指定搜索中心
)
else:
results = client.graph.search(
user_id=user_id,
query=query_text
)
relevant_nodes = results.nodes
relevant_edges = results.edges
print("=== 节点 ===")
if relevant_nodes:
for node in relevant_nodes:
print(node)
print("=== 相关事实 ===")
if relevant_edges:
for edge in relevant_edges:
print(edge.fact)
if __name__ == "__main__":
search_in_graph(user_id, "what does harry like?")执行结果
=== 节点 ===
=== 相关事实 ===
Harry Liu loves watching movies
Harry Liu loves learning Python
Harry wants to learn Python basics.
ai_bot is teaching Harry Python basics.
Harry Liu wants to learn Python basics.
ai_bot thinks movies are great choices
ai_bot thinks Python are great choices随机问题时怎么办?
在实际 RAG 场景里,用户的问题往往是随机的,我们并不能提前知道要以哪个节点作为中心。这里有两种策略:
1. 全局搜索(不指定中心节点)
search_in_graph(user_id, query_text)
Zep 会在整个知识图谱里检索与问题相关的节点和事实。
适合范围比较宽泛、问题不确定的场景。
2. 自动推断中心节点
我们可以先对用户问题做 关键词/实体抽取,再去匹配知识图谱节点。如果找到对应节点,就用它作为搜索中心;找不到,则 fallback 到全局搜索。
示例代码:
def auto_graph_search(user_id, query_text):
client = Zep(api_key=ZEP_API_KEY)
# 先尝试列出用户所有节点
nodes = client.graph.node.get_by_user_id(user_id=user_id)
# 简单关键词匹配(可以换成更智能的 NER 模型)
center_node_uuid = None
for node in nodes:
if node.label.lower() in query_text.lower():
center_node_uuid = node.uuid
break
# 如果找到中心节点,就指定搜索,否则全局搜索
return search_in_graph(user_id, query_text, center_node_uuid)
3. 搜索图的范围有三种 (edges, nodes , episodes)
query = "What projects is Jane working on?"
# Search for edges in a graph
edge_results = client.graph.search(
graph_id=graph_id,
query=query,
scope="edges", # Default is "edges"
limit=5
)
# Search for nodes in a graph
node_results = client.graph.search(
graph_id=graph_id,
query=query,
scope="nodes",
limit=5
)
# Search for episodes in a graph
episode_results = client.graph.search(
graph_id=graph_id,
query=query,
scope="episodes",
limit=5
)
# search for perferences
search_results = client.graph.search(
user_id=user_id,
query="the user's music preferences",
scope="nodes",
search_filters={
"node_labels": ["Preference"]
}
)
for i, node in enumerate(search_results.nodes):
preference = node.attributes
print(f"Preference {i+1}:{preference}")8. 初步认识与思考
从上面的例子可以看到,Zep 提供了以下几个层次的记忆能力:
-
对话存储:保留用户与 AI 的消息。
-
上下文总结:自动生成用户画像和对话摘要。
-
图谱搜索:以结构化的方式组织知识,方便 AI 检索和推理。
这让 AI 不仅能「记住你说过的话」,还可以「理解你是谁」、「你关心什么」、「你曾经提过的事实」——这就是长期记忆的价值。
总结
传统的聊天机器人往往是「短期记忆」:只记住本轮对话内容。而 Zep 则进一步赋予 AI 「长期记忆」:它能管理用户信息、保存对话线程、抽取知识图谱,并支持高效的检索和推理。
对于想要打造真正个性化 AI 助手的开发者来说,Zep 提供了一套非常实用的工具。未来我们还可以基于这些记忆能力,构建更加智能、持久且个性化的 AI 应用。
参考资料
https://github.com/getzep/zep
https://github.com/getzep/graphiti
Context Engineering Platform for AI Agents – Zep
其它
Zep 知识图谱结构
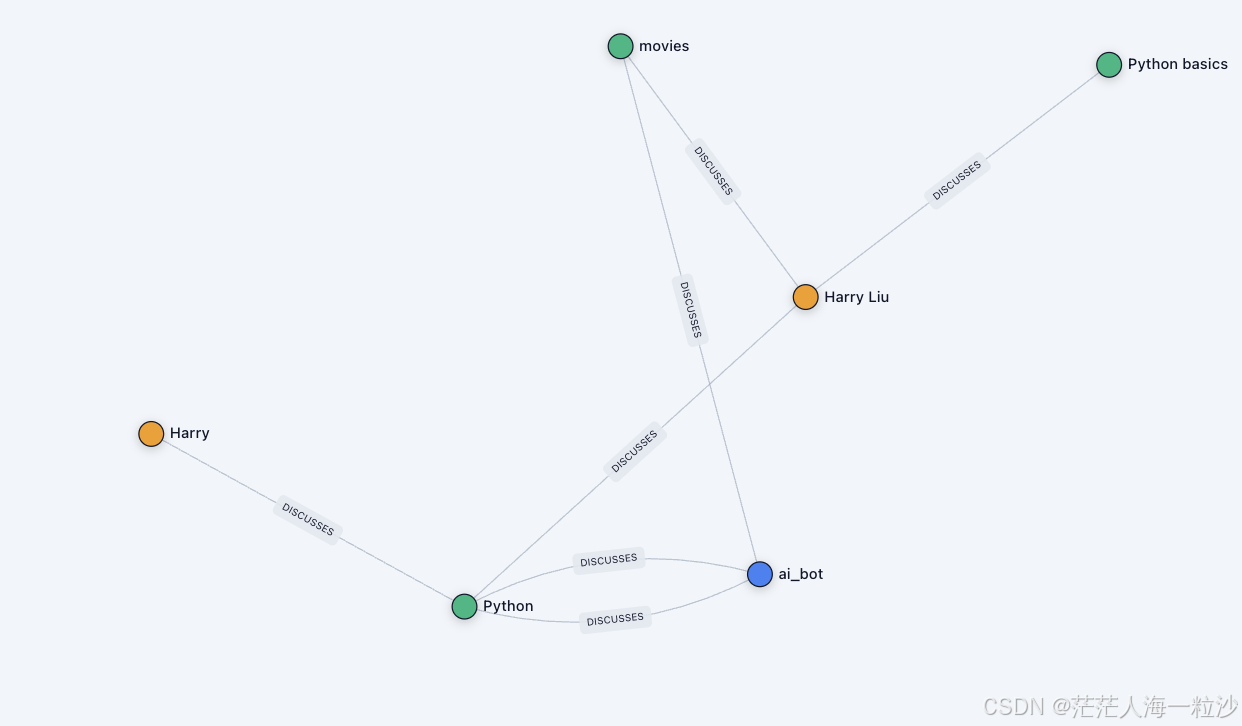
Zep 的知识图谱是围绕 用户个性化事实 自动构建的。
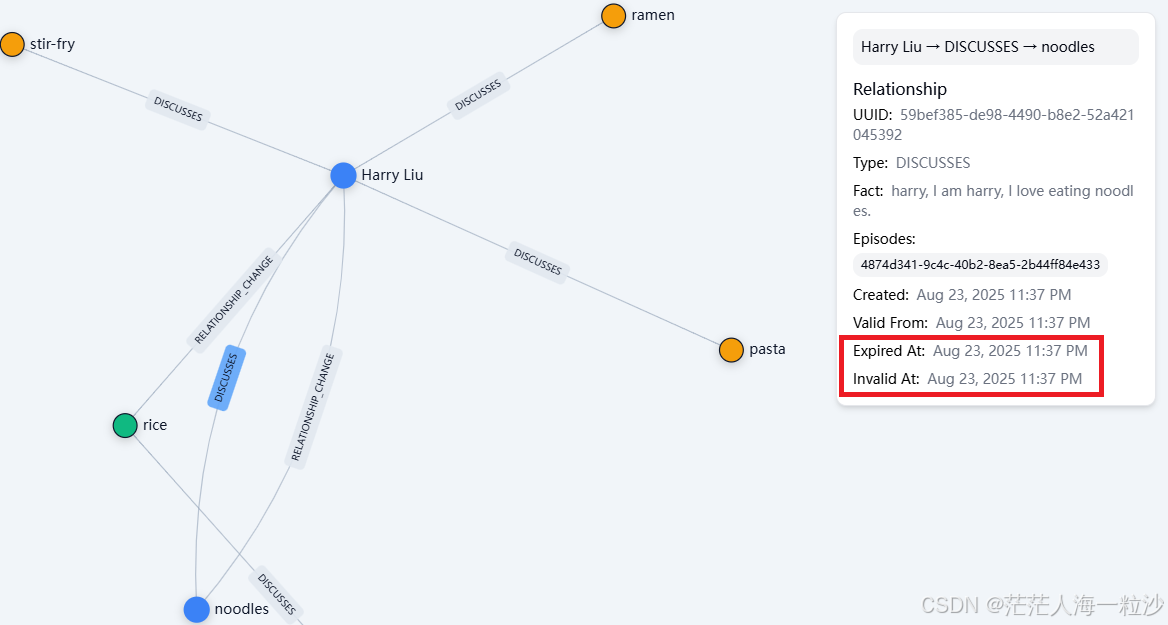
当用户和 bot 的对话中出现了新的事实(比如职业、爱好、关系等),Zep 会把这些事实提取出来,构造成 节点(Node) 和 边(Edge),存放到图数据库里。
1. 节点(Node)
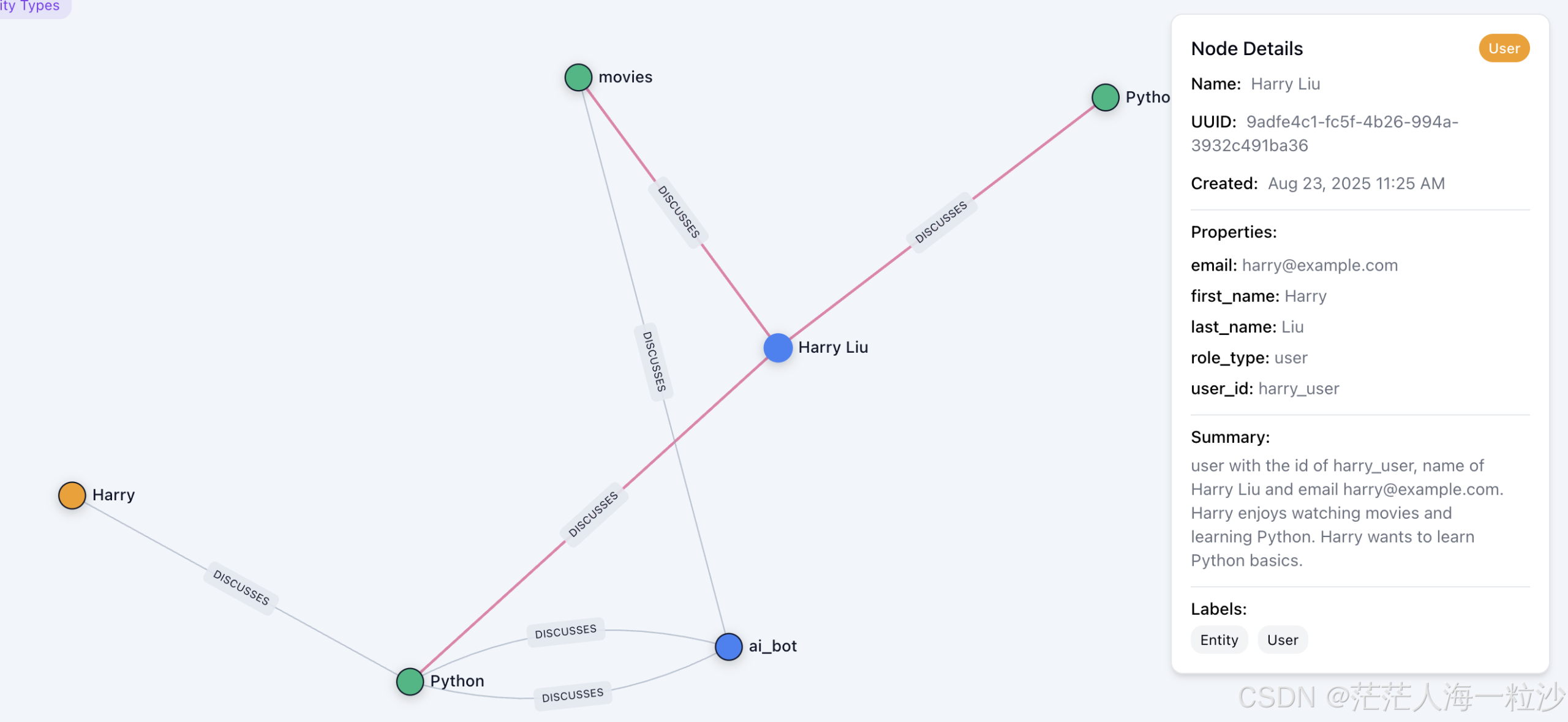
节点通常表示 实体,比如:
-
人物:
Harry、小明、AI bot -
组织:
百度、OpenAI -
事物:
Python、篮球、纽约 -
概念:
爱好、职业
每个节点包含信息:
-
uuid:节点唯一 ID
-
labels:标签名称,比如
"User", "Entity" -
summary:关于这个实体的总结描述(可能是从多条对话中生成的)
2. 边(Edge)

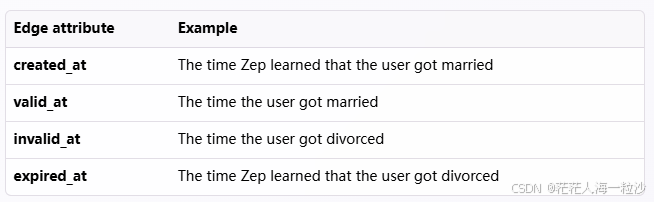
边表示 事实或关系,连接两个节点。
-
uuid:节点唯一 ID
-
fact:这条边表达的事实,例如:
-
"Harry 在百度工作" -
"Harry 的同事是小明" -
"Harry 喜欢 Python"
-
边不仅仅是“连接”,它们包含了 关系语义,是知识图谱的核心价值。
3. 图的构建方式
Zep 会自动从对话中抽取事实,比如:
用户说:
我在百度工作,我的同事是小明。我喜欢 Python。
知识图谱中会自动生成:
-
节点:
-
Harry
-
百度
-
小明
-
Python
-
-
边:
-
(Harry) —— [职业] ——> (百度)
-
(Harry) —— [同事] ——> (小明)
-
(Harry) —— [爱好] ——> (Python)
-
4. 知识图谱与 user_context 的区别
-
user_context:是 Zep 给出的一个 文本总结/提取块,方便直接放进 prompt,让 LLM 拿到用户背景。
-
比如
Harry 是 25 岁的程序员,在百度工作,喜欢 Python 和篮球。
-
-
knowledge graph:是一个结构化的 实体-关系图,方便做事实检索和推理。
-
比如能回答:
-
Harry 的同事是谁?
-
Harry 的爱好和职业之间有没有联系?
-
和 Harry 相关的所有实体节点有哪些?
-
-
小结:
-
节点(Node) 存放用户相关的实体。
-
边(Edge) 存放事实和关系,带有自然语言描述。
-
知识图谱 适合做结构化检索和推理(特别是关系类问题)。
-
user_context 更适合当作 RAG 的输入上下文,直接提供背景信息给 LLM。
© 版权声明
文章版权归作者所有,未经允许请勿转载。