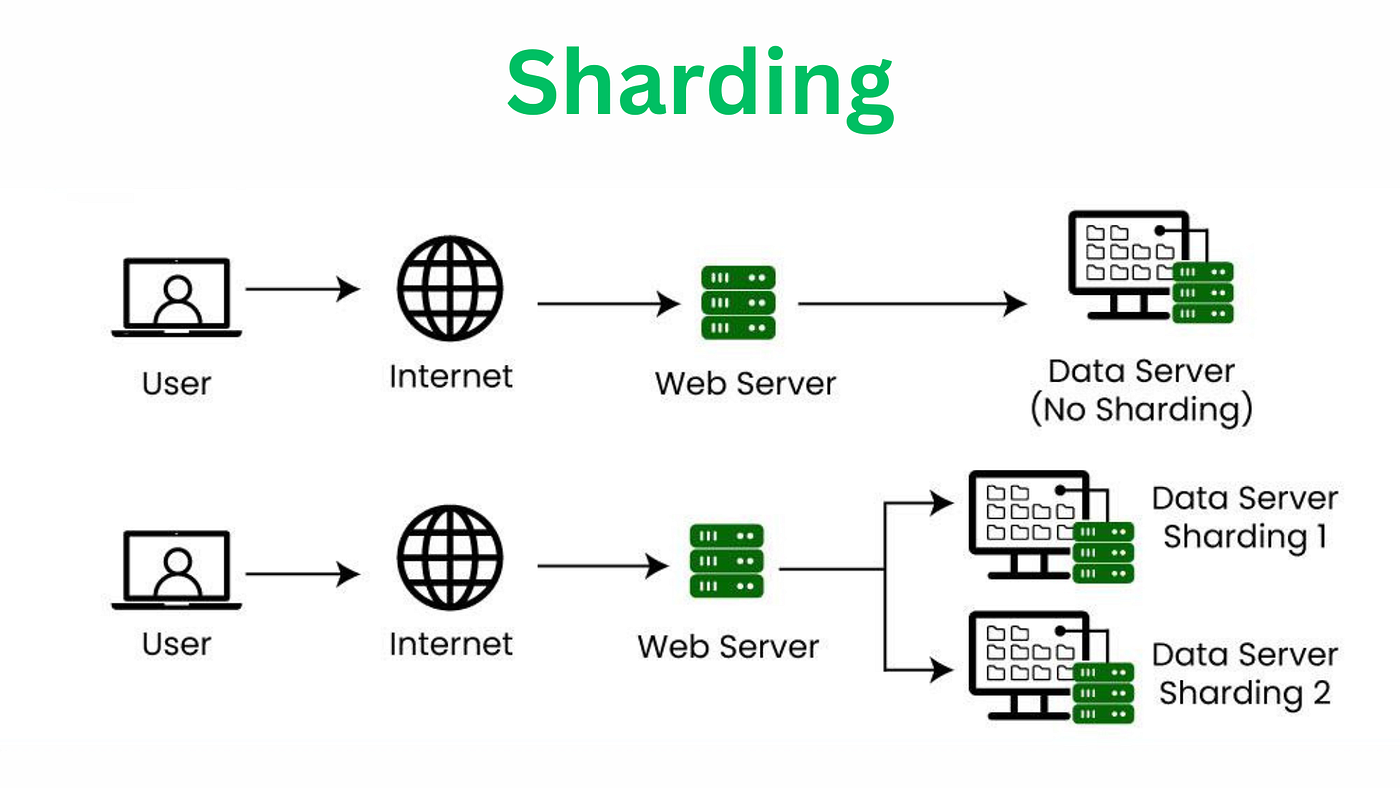
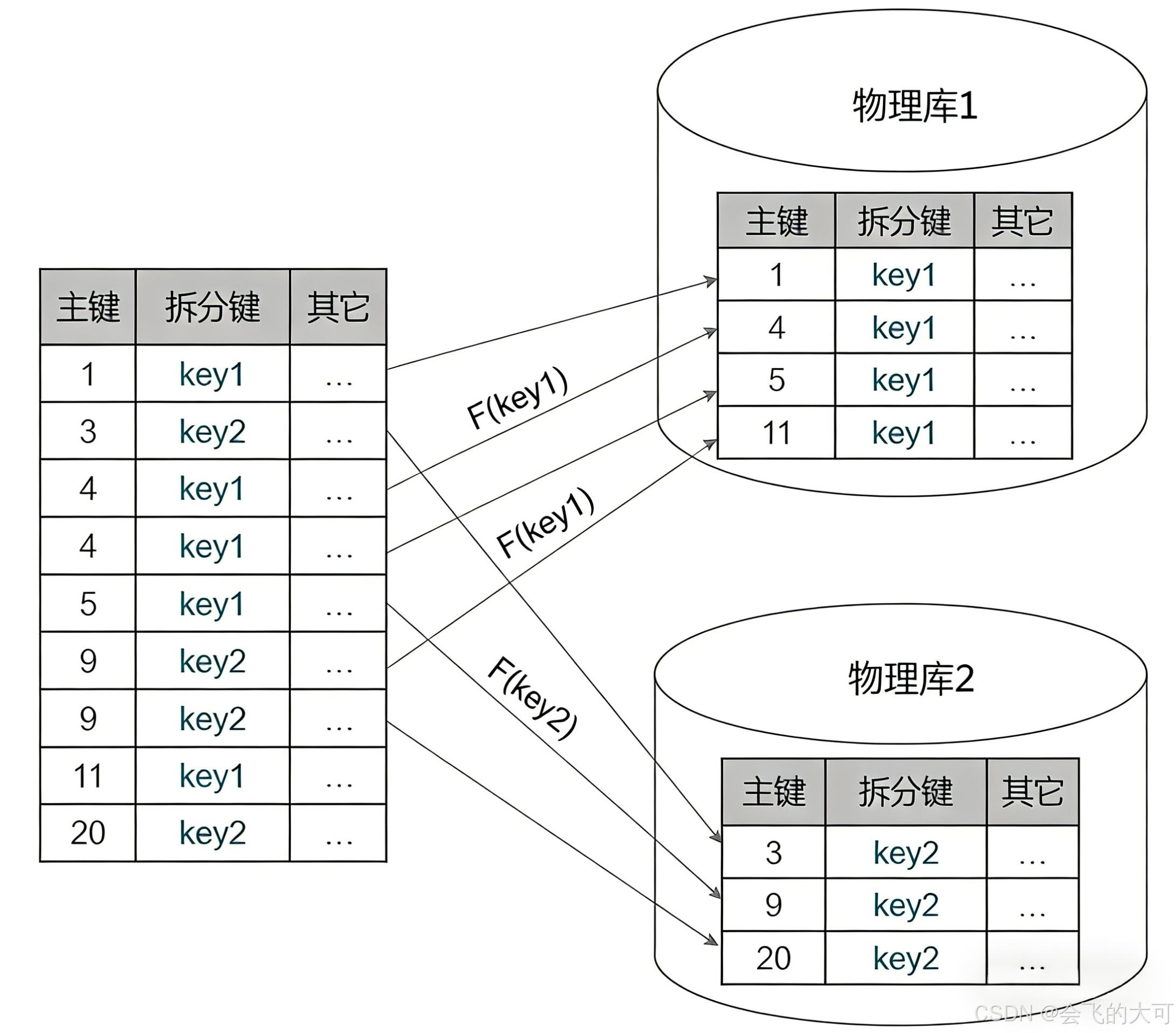

分库分表方法论:什么时候该拆?怎么拆?
分库分表方法论:什么时候该拆?怎么拆?
本文将系统性地讲解数据库分库分表的核心方法论,从"何时拆"到"怎么拆",配合实战代码和架构图,帮助你建立完整的分库分表知识体系。
一、为什么需要分库分表?
随着业务的高速发展,单数据库往往会率先遭遇性能瓶颈。当单表数据量突破千万级、并发请求飙升至万级时,查询延迟、写入阻塞等问题会接踵而至。
单库瓶颈的典型症状
| 症状 | 说明 | 阈值参考 |
|---|---|---|
| 查询变慢 | 简单查询响应时间 > 100ms | 单表数据 > 500万行 |
| 写入阻塞 | 插入/更新出现明显延迟 | 并发写入 > 1000 QPS |
| 磁盘告警 | 磁盘使用率持续增长 | 单库容量 > 500GB |
| 连接打满 | 数据库连接池频繁耗尽 | 并发连接 > 1000 |
二、分库分表决策流程:什么时候该拆?
分库分表是"不得已而为之"的优化手段,在架构设计初期应尽量保持简单。以下是科学的决策流程:
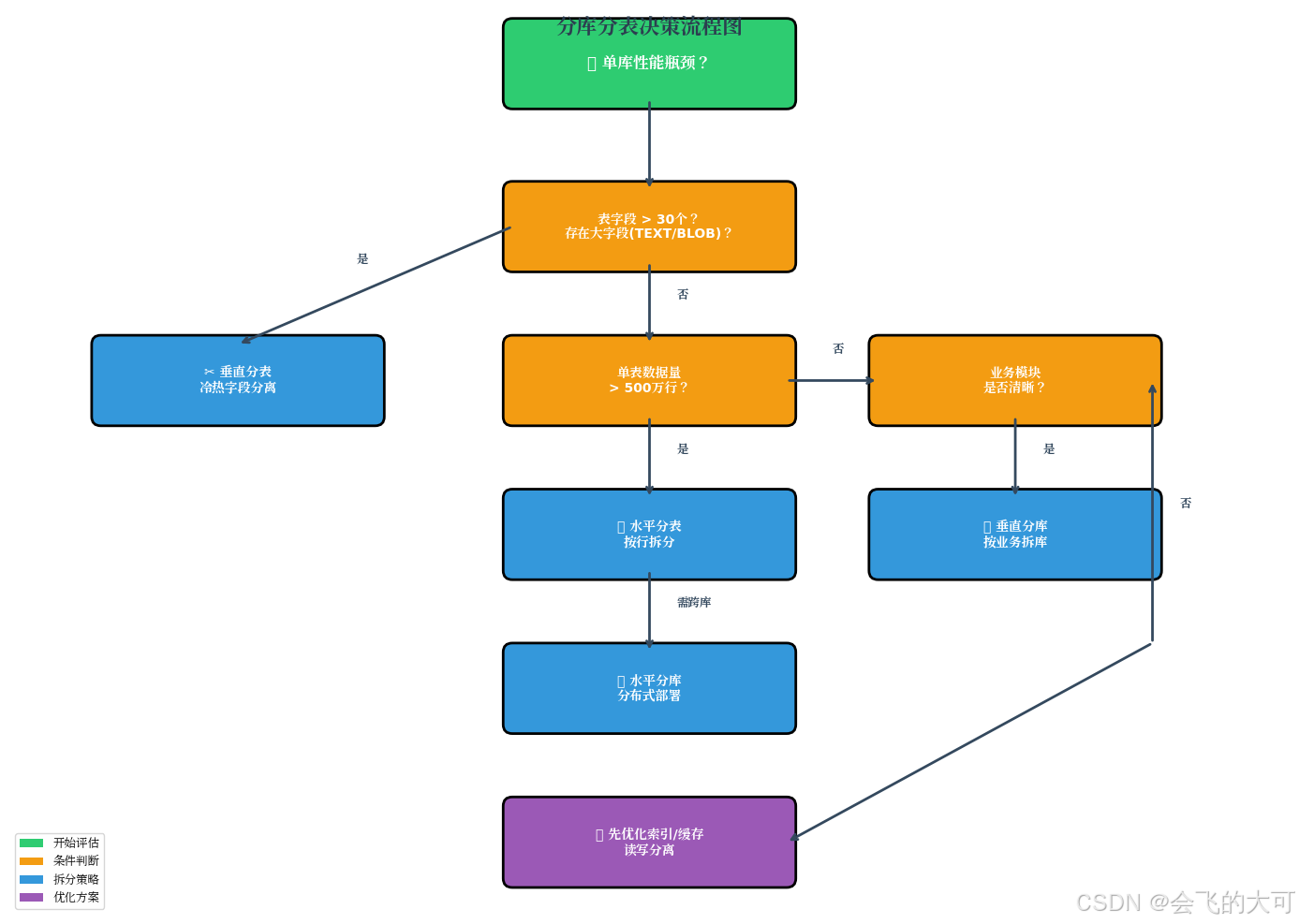
决策要点
- 先评估:是否真的需要分库分表?能否先通过优化索引、缓存、读写分离、归档历史数据来解决?
- 先垂直,后水平:通常先进行垂直拆分,使业务清晰。若单表数据量仍过大,再对该表进行水平拆分
- 避免过度拆分:拆分数量并非越多越好,分表过多会增加运维成本和跨分片查询开销
三、拆分策略详解:怎么拆?
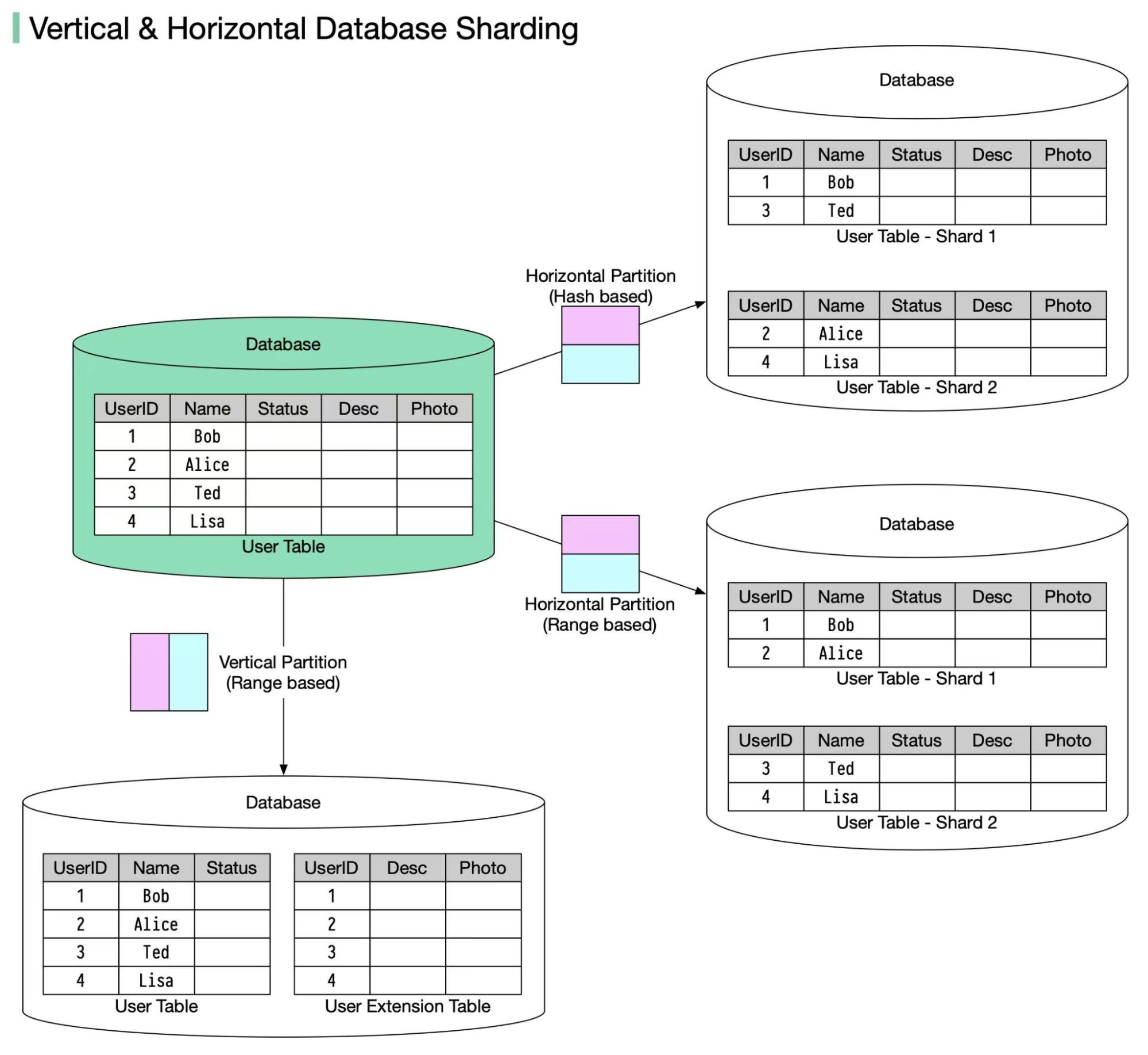
分库分表的核心策略分为两大类:垂直拆分和水平拆分。
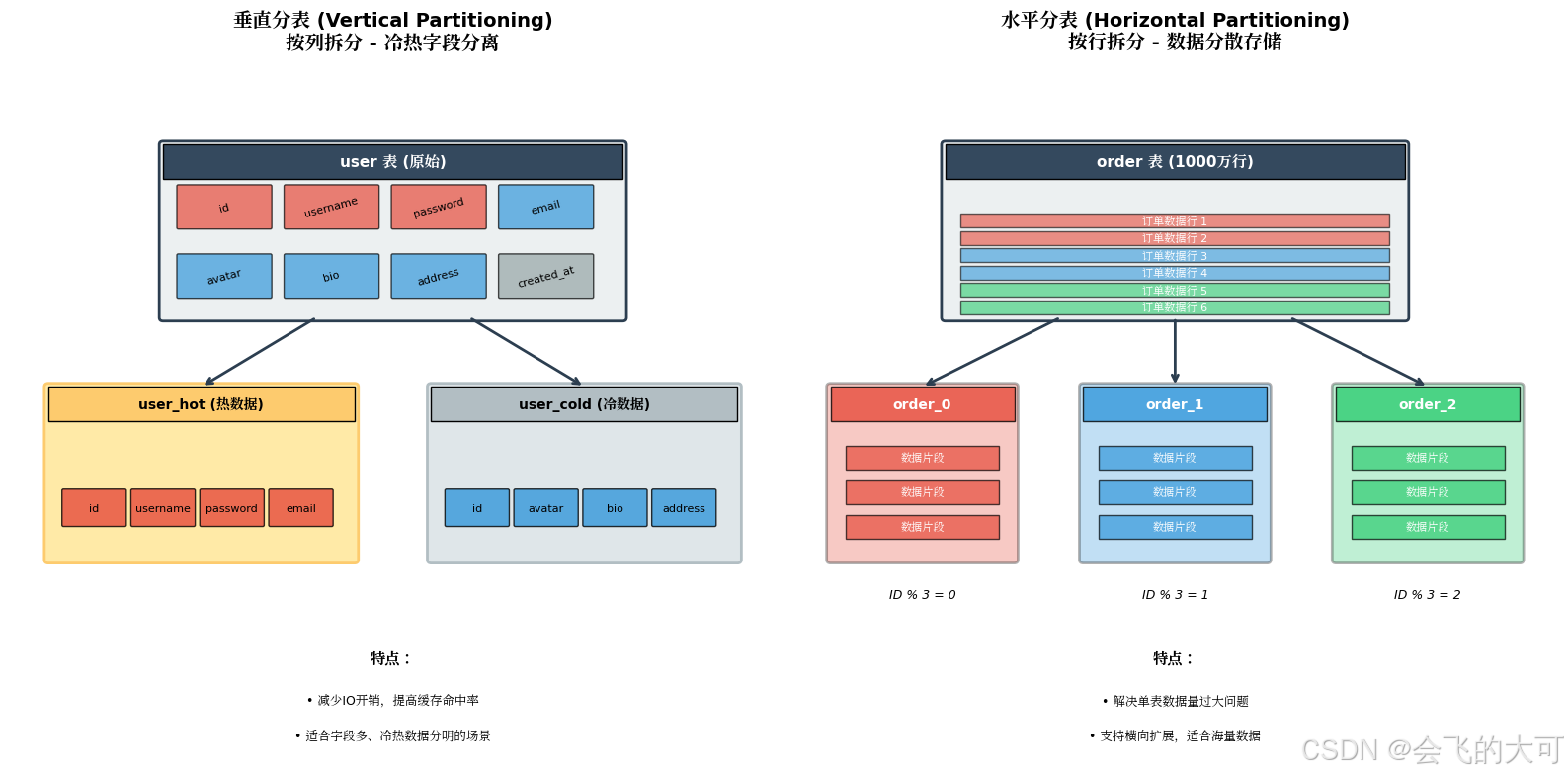
3.1 垂直拆分(Vertical Sharding)
垂直拆分是按照数据表的列(字段)维度进行拆分,将一个包含多个字段的宽表拆分为多个包含较少字段的窄表。
适用场景
- 表字段过多(>30个),存在大量低频访问的"大字段"(如TEXT、BLOB)
- 业务模块清晰,字段的业务归属明确
- 高频查询只依赖少量核心字段
实战示例:用户表垂直拆分
原始表结构:
CREATE TABLE user (
id BIGINT PRIMARY KEY,
username VARCHAR(50),
password VARCHAR(100),
email VARCHAR(100),
avatar_url VARCHAR(500), -- 大字段,访问频率低
bio TEXT, -- 大字段
address VARCHAR(200), -- 访问频率低
created_at TIMESTAMP
);
拆分后:
-- 热数据表:高频访问的核心字段
CREATE TABLE user_hot (
id BIGINT PRIMARY KEY,
username VARCHAR(50),
password VARCHAR(100),
email VARCHAR(100),
created_at TIMESTAMP
);
-- 冷数据表:低频访问的大字段
CREATE TABLE user_cold (
id BIGINT PRIMARY KEY,
avatar_url VARCHAR(500),
bio TEXT,
address VARCHAR(200),
FOREIGN KEY (id) REFERENCES user_hot(id)
);
垂直分库
按业务模块将数据库拆分成不同的数据库实例:
user_db: user_hot, user_cold, user_auth
order_db: order, order_item, order_logistics
product_db: product, product_category, inventory
3.2 水平拆分(Horizontal Sharding)
水平拆分是按照数据表的行(记录)维度进行拆分,将一个包含大量行数据的表拆分为多个结构完全相同的表。
核心分片策略
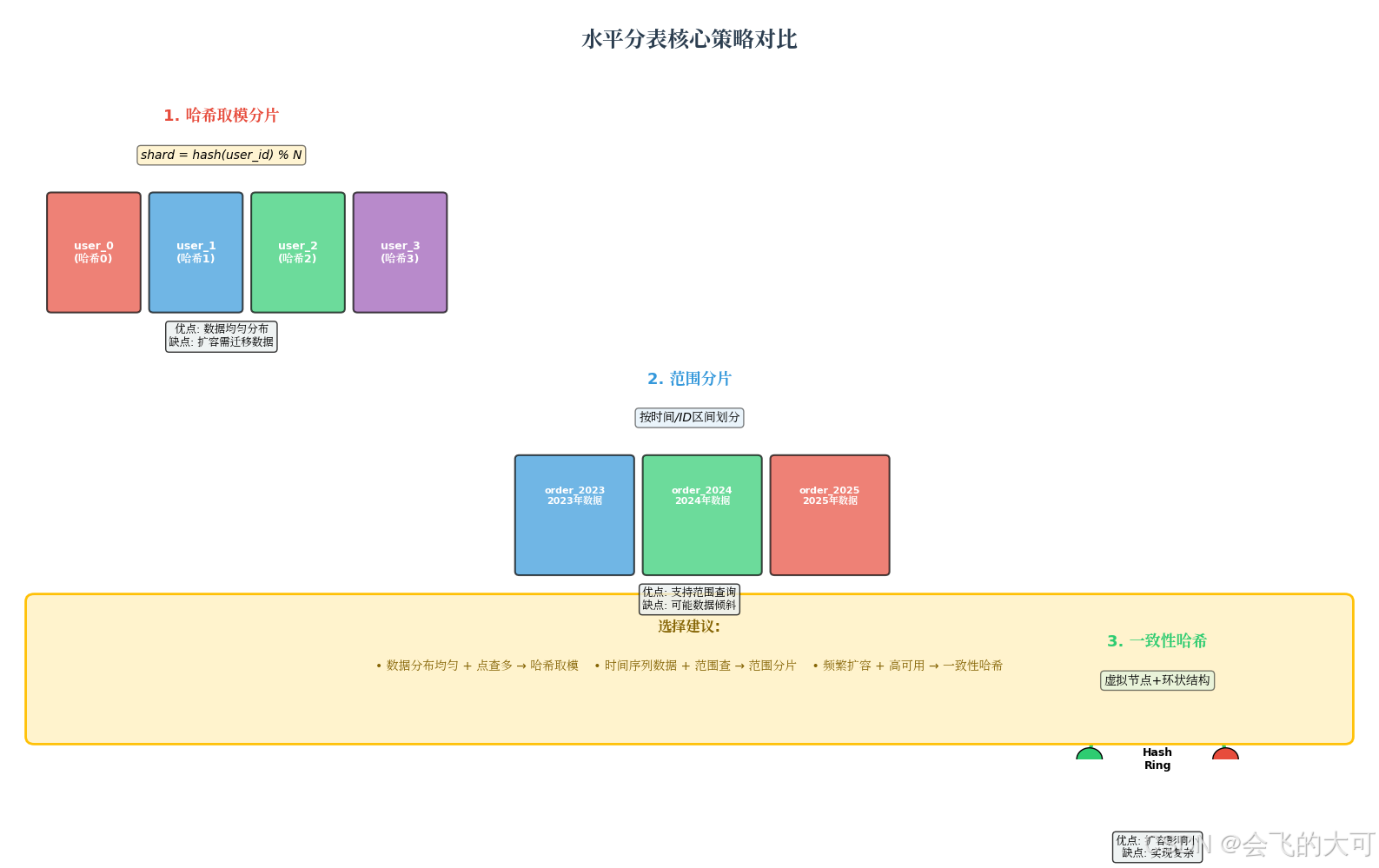
1. 哈希取模分片
// 分片算法:shard = hash(user_id) % N
public class HashShardingStrategy {
public static int getShardId(long userId, int shardCount) {
return (int) (Math.abs(userId) % shardCount);
}
}
- 优点:数据均匀分布,负载均衡
- 缺点:扩容时需迁移数据(可通过一致性哈希缓解)
2. 范围分片
-- 按时间范围分表
CREATE TABLE order_202401 (LIKE order_template);
CREATE TABLE order_202402 (LIKE order_template);
CREATE TABLE order_202403 (LIKE order_template);
- 优点:支持范围查询,易于归档历史数据
- 缺点:可能出现数据倾斜(如近期数据集中)
3. 一致性哈希
适合频繁扩容的场景,通过虚拟节点减少数据迁移量。
四、实战:基于ShardingSphere的分库分表实现
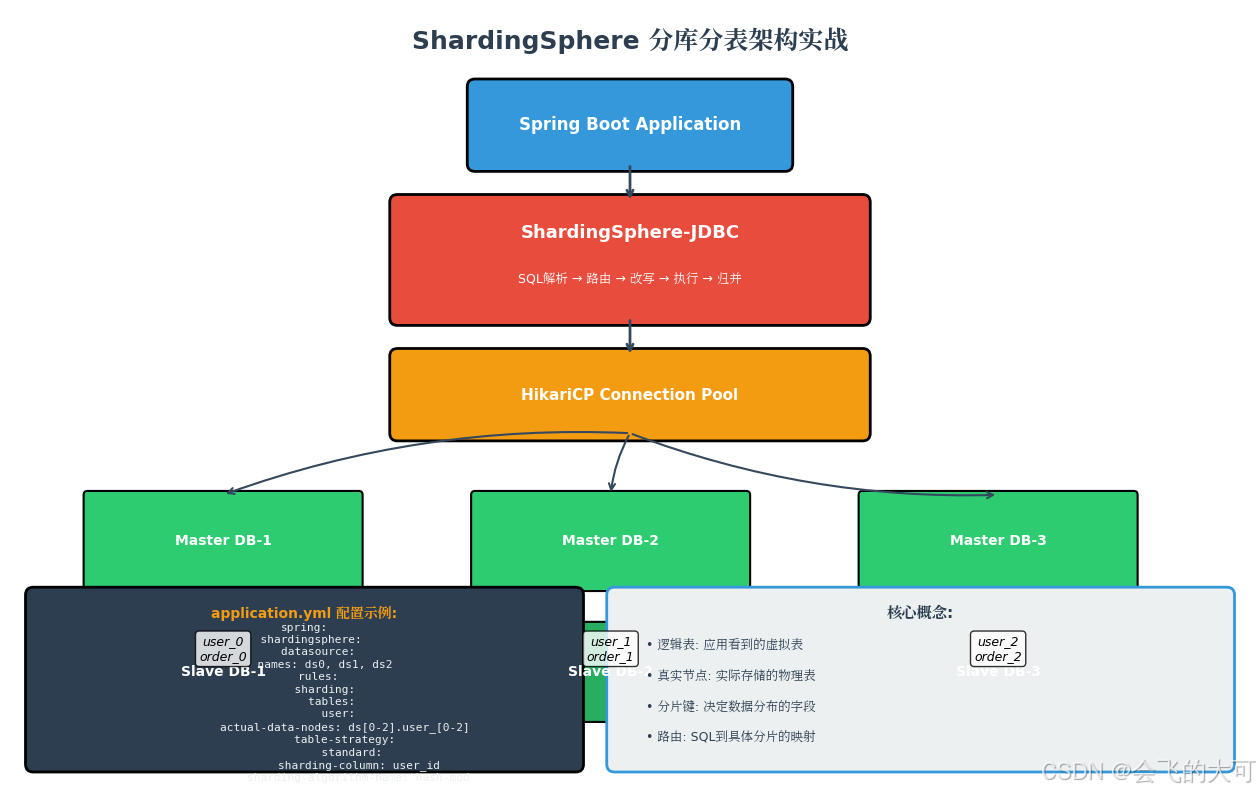
4.1 Maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.4.0</version>
</dependency>
4.2 配置文件
spring:
shardingsphere:
# 数据源配置
datasource:
names: ds0, ds1, ds2
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db0
username: root
password: password
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db1
username: root
password: password
ds2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db2
username: root
password: password
# 分片规则
rules:
sharding:
tables:
# 用户表分片配置
user:
# 真实数据节点:ds0.user_0, ds0.user_1, ds1.user_0...
actual-data-nodes: ds$->{0..2}.user_$->{0..2}
# 分表策略
table-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: user-table-hash
# 分库策略
database-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: user-db-hash
# 分片算法定义
sharding-algorithms:
user-table-hash:
type: INLINE
props:
algorithm-expression: user_$->{user_id % 3}
user-db-hash:
type: INLINE
props:
algorithm-expression: ds$->{user_id % 3}
# 分布式ID生成
key-generators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 0
props:
sql-show: true # 开启SQL日志,方便调试
4.3 实体类与Mapper
@Data
@TableName("user") // 逻辑表名
public class User {
@TableId(type = IdType.ASSIGN_ID) // 使用ShardingSphere生成的ID
private Long userId;
private String username;
private String email;
private LocalDateTime createdAt;
}
@Mapper
public interface UserMapper extends BaseMapper<User> {
// 根据user_id查询会自动路由到对应分片
@Select("SELECT * FROM user WHERE user_id = #{userId}")
User selectByUserId(@Param("userId") Long userId);
}
4.4 分片路由测试
@SpringBootTest
public class ShardingTest {
@Autowired
private UserMapper userMapper;
@Test
public void testInsert() {
// 插入数据会自动路由到对应分片
for (int i = 0; i < 10; i++) {
User user = new User();
user.setUsername("user_" + i);
user.setEmail("user" + i + "@example.com");
userMapper.insert(user);
System.out.println("用户ID: " + user.getUserId() +
", 路由: ds" + (user.getUserId() % 3) +
".user_" + (user.getUserId() % 3));
}
}
}
五、分库分表的核心挑战与解决方案
5.1 分布式ID生成
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 雪花算法 | 性能高,趋势递增 | 依赖时钟 | 大多数场景 |
| 数据库号段 | 简单可靠 | 需要额外表 | 中小型应用 |
| Redis自增 | 性能高 | 依赖Redis | 高并发场景 |
5.2 跨分片查询
问题:查询条件不包含分片键时,需要扫描所有分片。
解决方案:
- 绑定表:将关联表使用相同分片键,确保相关数据在同一分片
- 异构索引表:建立分片键与其他查询条件的映射关系
- 搜索引擎:将数据同步到Elasticsearch进行复杂查询
5.3 分布式事务
// 使用ShardingSphere的分布式事务
@ShardingSphereTransactionType(TransactionType.XA) // 或 BASE (Seata)
@Transactional
public void createOrder(Order order, OrderItem item) {
orderMapper.insert(order);
orderItemMapper.insert(item);
// 跨分片事务自动处理
}
六、总结与建议
核心原则
- 先垂直后水平:优先通过垂直拆分实现业务解耦,再进行水平拆分
- 拆分键选择:分片键应选择查询最频繁、最能均匀分布数据的字段(如用户ID)
- 预留扩展:设计之初就要为未来预留,例如一致性哈希策略
- 权衡复杂度:拆分越细,系统复杂度(开发、运维、监控)越高
演进路线建议
单库单表
↓ (数据量<100万)
索引优化 + 缓存
↓ (数据量>500万)
垂直分表(冷热分离)
↓ (数据量>1000万)
水平分表(同库)
↓ (并发>5000)
水平分库(分布式)
↓ (业务复杂)
垂直分库(微服务化)
分库分表并非技术炫技,而是基于业务发展的"顺势而为"。在实际落地中,需避免脱离业务场景的"技术先行",通过合理的拆分设计,让数据库既能支撑当前业务,又能兼容未来的增长需求。
参考图片:
- 分库分表架构示意图:

- 分片路由示意图:
© 版权声明
文章版权归作者所有,未经允许请勿转载。

