
Flink监控体系实战:从零构建企业级运维平台
____simple_html_dom__voku__html_wrapper____>
Flink监控体系实战:从零构建企业级运维平台
【免费下载链接】flink  项目地址: https://gitcode.com/gh_mirrors/fli/flink
项目地址: https://gitcode.com/gh_mirrors/fli/flink
Apache Flink作为流处理领域的领军框架,其强大的实时数据处理能力已被广泛应用于各类企业级场景。然而,随着集群规模扩大和作业复杂度提升,构建一套完善的监控体系成为保障系统稳定运行的关键。本文将带你从零开始搭建Flink企业级监控平台,通过实战案例掌握核心监控指标、告警配置和性能优化技巧,让你的流处理平台始终保持最佳状态。
核心监控指标解析:掌握Flink健康状态的关键
Flink监控体系的核心在于对关键指标的实时追踪。在flink-metrics模块中,系统提供了丰富的指标采集器,涵盖从JVM性能到作业执行状态的全方位监控。主要指标可分为三大类:
1. 集群资源监控
-
TaskManager资源使用率:包括CPU、内存、网络I/O等基础指标,通过
flink-metrics-core模块中的OperatingSystemGauge实现采集 -
Slot分配与使用情况:反映集群资源的分配效率,相关实现位于
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager目录
2. 作业执行监控
-
Checkpoint成功率:通过
CheckpointStatsTracker实时监控检查点状态,关键实现位于flink-runtime/src/main/java/org/apache/flink/runtime/checkpoint -
背压状态:通过
BackPressureStatsTracker检测数据处理瓶颈,帮助定位慢节点
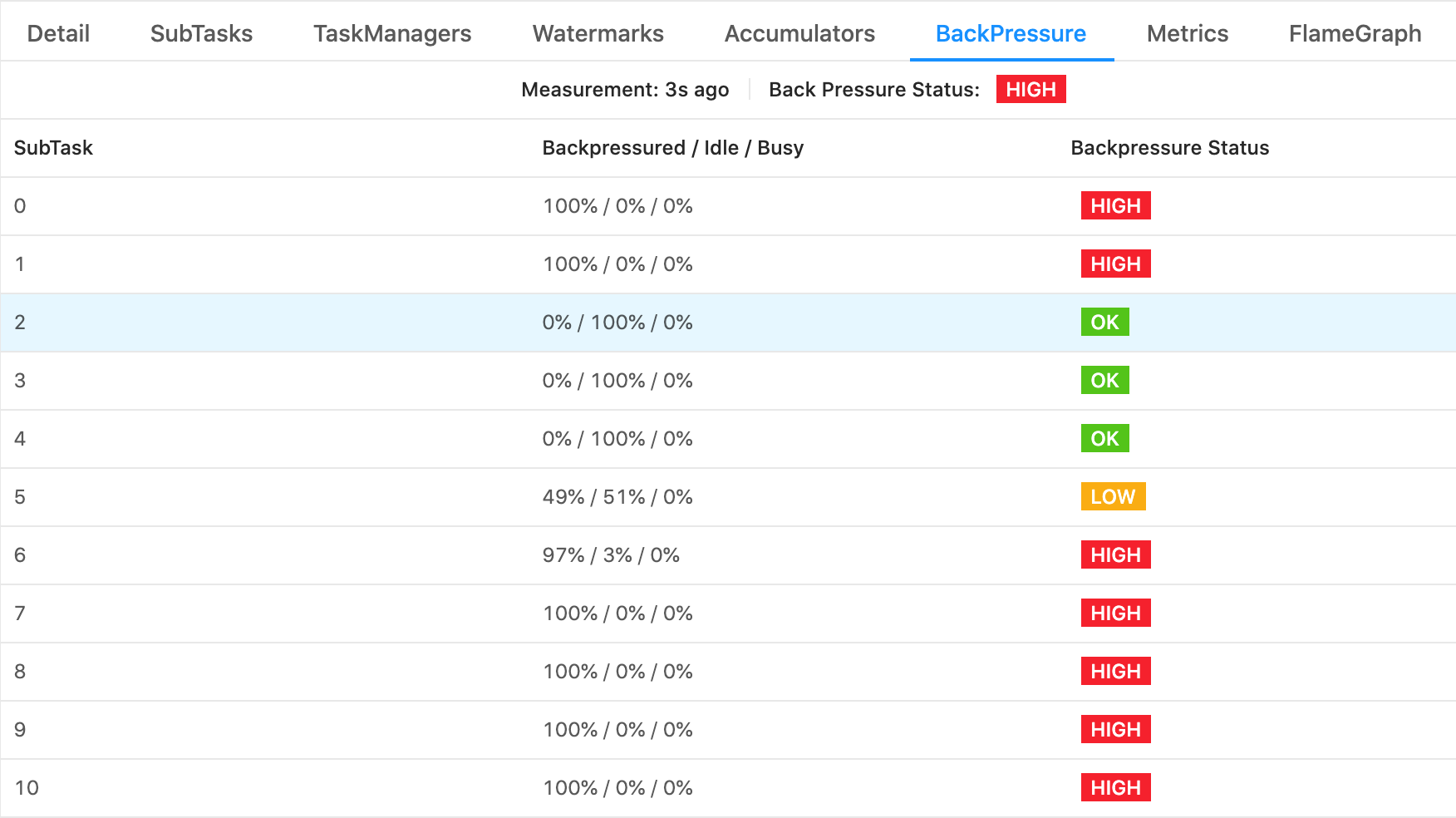 图1:Flink Web UI中的背压监控界面,可直观显示各子任务的处理压力状态
图1:Flink Web UI中的背压监控界面,可直观显示各子任务的处理压力状态
3. 指标采集框架
Flink提供了多种指标Reporter,可将数据发送到不同监控系统:
- JMXReporter:
flink-metrics-jmx模块,适合本地调试 - InfluxdbReporter:
flink-metrics-influxdb模块,支持时序数据存储 - PrometheusReporter:适合与Grafana结合构建可视化仪表盘
监控平台搭建:从基础配置到高级集成
1. 基础监控配置
Flink内置的Web监控界面是监控体系的起点。通过修改flink-conf.yaml启用基础监控:
metrics.reporters: jmx, prom
metrics.reporter.jmx.class: org.apache.flink.metrics.jmx.JMXReporter
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
metrics.reporter.prom.port: 9249
配置文件位于flink-dist/src/main/flink/conf/flink-conf.yaml,修改后重启集群即可生效。
2. 高级可视化平台构建
将Flink指标接入Grafana可实现更强大的可视化能力。关键步骤包括:
- 部署Prometheus:收集Flink暴露的指标数据
- 配置Grafana数据源:连接Prometheus
- 导入Flink监控仪表盘:可使用社区提供的模板或自定义面板
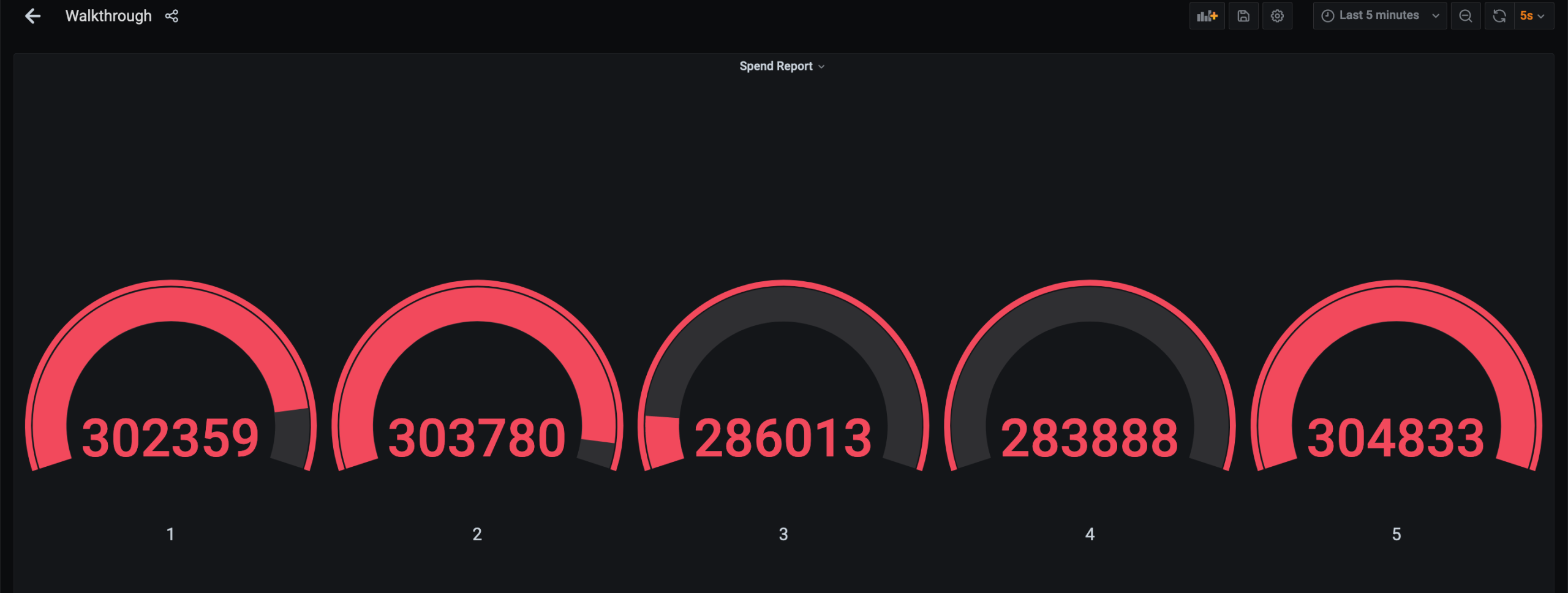 图2:基于Grafana构建的Flink监控仪表盘,展示关键性能指标和趋势
图2:基于Grafana构建的Flink监控仪表盘,展示关键性能指标和趋势
3. 告警系统配置
通过Prometheus AlertManager配置关键指标告警:
- Checkpoint失败率超过阈值
- TaskManager内存使用率过高
- 作业延迟超过设定阈值
告警规则配置示例位于flink-metrics-prometheus模块的文档中,可根据实际需求调整阈值和通知方式。
实战案例:解决生产环境中的监控难题
案例1:Checkpoint优化
某电商平台实时数据处理作业频繁出现Checkpoint超时,通过监控发现:
- 查看Checkpoint详情页面:
docs/static/fig/checkpoint_monitoring-details.png - 发现State大小异常增长,定位到窗口状态未正确清理
- 通过优化状态TTL配置解决问题,相关代码位于
flink-core/src/main/java/org/apache/flink/api/common/state/StateTtlConfig.java
案例2:背压问题诊断
某实时推荐系统出现数据处理延迟,通过以下步骤解决:
- 在Flink Web UI查看背压状态:
docs/static/fig/back_pressure_job_graph.png - 发现Filter算子处理瓶颈
- 优化算子并行度和资源配置,相关配置位于
flink-runtime/src/main/java/org/apache/flink/runtime/jobgraph/JobGraph.java
监控最佳实践与性能优化
1. 监控指标采集策略
- 关键指标优先:优先监控Checkpoint成功率、背压状态、资源使用率等核心指标
- 采样频率调整:非关键指标可降低采样频率,减少性能开销
- 指标聚合:对大规模集群采用指标聚合,避免监控系统过载
2. 性能优化技巧
-
异步快照:启用Checkpoint异步快照,配置项
execution.checkpointing.async-snapshot -
增量Checkpoint:对大状态作业启用增量Checkpoint,相关实现位于
flink-statebackend-rocksdb模块 -
资源隔离:通过
flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionGraph.java实现作业资源隔离
3. 监控系统扩展
对于超大规模集群,可考虑:
- 部署多级监控架构
- 实现监控数据的分层存储
- 开发自定义指标和告警规则,扩展点位于
flink-metrics-core/src/main/java/org/apache/flink/metrics
总结:构建可持续的Flink监控体系
搭建企业级Flink监控平台是一个持续迭代的过程,需要结合业务需求不断优化。通过本文介绍的方法,你可以:
- 全面掌握Flink核心监控指标
- 搭建从基础到高级的监控可视化平台
- 快速诊断和解决生产环境中的性能问题
- 建立可持续的监控优化机制
随着Flink版本的不断更新,监控功能也在持续增强。建议定期关注docs/content/docs/ops/monitoring.md官方文档,了解最新的监控特性和最佳实践,让你的Flink监控体系始终保持领先。
通过这套监控体系,企业可以显著提升流处理平台的稳定性和可靠性,为业务决策提供实时、准确的数据支持,在激烈的市场竞争中获得数据驱动的优势。
【免费下载链接】flink 项目地址: https://gitcode.com/gh_mirrors/fli/flink
© 版权声明
文章版权归作者所有,未经允许请勿转载。


