SCM-HBT诞生记:我给叠合一致法装上了分层贝叶斯+Transformer双引擎
SCM-HBT诞生记:我给叠合一致法装上了分层贝叶斯+Transformer双引擎
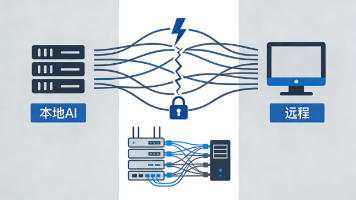
引言:从“理论对接”到“工程落地”上一篇文章《当SCM遇上do-演算》里,我详细拆解了如何把Judea Pearl的因果推断框架与SCM(叠合一致法)的闭合验证进行形式化对接。结论是:SCM的“反向复现验证”本质上就是do-演算中干预层思想的工程化实现。但那篇文章留了一个悬念:理论对接完了,代码怎么写?这篇文章就是答案。我将过去两周的工程实践完整复盘——如何把分层贝叶斯和Transformer这两套技术,装进SCM的方法论骨架里,最终打造出一个全新的SCM-HBT引擎。H代表Hierarchical Bayesian(分层贝叶斯),T代表Transformer。一个负责精确量化,一个负责零样本发现。这就是SCM-HBT的双引擎架构。一、为什么需要双引擎?在动手之前,我先把SCM引擎的需求拆成了两个正交的维度:需求 传统做法 痛点因果效应估计 线性回归,输出一个点估计 无法量化不确定性,“并发效应到底有多可靠?”答不上来因果结构发现 逐数据集运行PC算法 每次新数据都要重跑,分钟级延迟,无法规模化这两个痛点分别对应了SCM方法论的两个核心环节:· 系数标定:需要知道“并发数每增加1单位,TPS到底增加多少,这个结论有多可靠”· 变量拆解:需要知道“哪些变量之间有因果边,哪些只是噪声相关”传统方法用一个线性回归同时解决这两个问题,结果两个都解决不好。分层贝叶斯擅长第一个,Transformer擅长第二个。双引擎的思路由此而来。二、引擎一:分层贝叶斯——给因果效应加上“误差条”2.1 为什么是分层?在做大模型TPS分析时,我有一个天然的分组结构:三个不同的模型(Qwen、DeepSeek、InternLM)。传统做法是三个模型分别建模,或者全部混在一起统一建模。两种做法都有问题:· 分别建模:DeepSeek数据量少,单独估计不稳定· 统一建模:抹杀了模型间的差异,InternLM的高效应会被Qwen拉低分层贝叶斯的“部分池化”恰好解决了这个矛盾:它假设三个模型的因果效应服从一个共同的高层分布,估计时既利用各自的数据,又向全局均值“借力”。数据量少的模型(DeepSeek)会自动向全局均值收缩,估计更稳健;数据量多的模型(InternLM)则保持自己的特性。2.2 用PyMC
© 版权声明
文章版权归作者所有,未经允许请勿转载。