【4】为什么模型总喜欢先把维度拉高,再压回来?从一个小例子走到 Transformer、LLaMA 与 LoRA
写在前面
很多人可能都会好奇:为什么模型里的维度总是被先拉高,再降回来?
我们从一个例子来切入
假设你手里有一批高考生,你要帮他们做志愿填报。
- 可你一开始只知道一个信息:他们大多都是 171717 到 191919 岁。
- 这个显然是真的,但区分度几乎为零!
只看年龄,你根本没法判断谁更适合冲理工,谁更适合读医学,谁应该优先考虑城市,谁其实更在意专业方向。
于是你开始不断补充特征:数学成绩、语文成绩、选科组合、是否愿意离家、对城市层级的偏好、家庭预算、职业兴趣。
再往前走一步,你会发现真正有用的甚至不只是这些单独特征,而是它们的组合关系。比如“数学强 + 物理强 + 愿意去外地”和“语文强 + 表达好 + 更看重城市资源”,即使这两个学生高考总分、年龄一模一样,也会得到完全不同的志愿建议。
这个瞬间,其实已经把本文最重要的问题说出来了:
为什么有时候非得先把维度升上去?
因为这样,会让很多原本分不开、讲不清、组合不出来的结构,瞬间变得容易处理;
那为何做完这步,又必须再把维度降回来?
本文将会沿着这条主线展开:模型为什么要不断地重新组织表示空间?
- 先用直觉和小例子把问题讲清楚
- 再补线性代数工具
- 最后自然过渡到
Transformer的注意力与FFN - 并延伸到
LoRA与LLaMA的相关结构
阅读路线
- 第 1 章先用例子把问题立住:为什么有时必须先升维,才能把东西分开。
- 第 2 章补最少够用的线性代数:空间、秩、投影、SVD。
- 第 3-5 章再进入神经网络主线:表示、注意力、
FFN到底在怎样重排空间。 - 第 6-7 章作为延伸:为什么
LoRA是低秩这条线的自然结果,为什么LLaMA会把升降维结构写得更显眼。 - 第 8 章最后回到工程配置:以后看到
q_proj、up_proj、lora_rank时,应该脑子里先冒出什么图景。
第 1 章 先从一个问题开始:为什么有时非得先升维,再降维?
1.1 先别急着看模型,先看一个生活场景
假设你在做高考志愿填报,手里有同一批学生。你想给他们做更合理的志愿建议:谁更适合偏工科路线,谁更适合偏医学路线,谁应该优先考虑城市平台,谁应该优先考虑专业确定性。
一开始你可能只看两个特征:
- x1x_1x1:数学/理科能力强不强
- x2x_2x2:语言表达/文科能力强不强
你很快发现一个尴尬问题:只在这两个维度里画一条线,怎么都切不漂亮。 有的学生是“理科强但表达弱”,有的是“表达强但理科弱”,他们未必一个就一定适合文科、另一个就一定适合理工。真正影响建议结果的,往往不是单个特征本身,而是特征之间的组合关系。
这时一个非常自然的想法就出现了:既然二维里不好分,那我能不能先把表示换一下?比如除了看 x1x_1x1 和 x2x_2x2,再额外看一个组合特征 x1x2x_1x_2x1x2,或者更一般地,看一组新的组合坐标。
一旦你这么想,其实就已经站在神经网络设计的门口了。很多模型层本质上都在重复三步:
- 先把原表示送到一个更容易展开组合关系的空间里
- 在那个空间里做匹配、筛选、非线性组合
- 再把结果压回主干空间,继续往下传
从“同一批学生如何被分开”的角度看,这些层都在回答同一个问题:
当原来的表示不够好用时,我们该怎样换一个空间,让结构更容易被分开、被组合、被更新?
你甚至可以先把这件事概括成一行:
训练里的很多“投影”≈换一个更合适的表示空间
text{训练里的很多“投影”} approx text{换一个更合适的表示空间}
训练里的很多“投影”≈换一个更合适的表示空间
差别只在于,这个“更合适”到底是:
- 让表示更好分开
- 让计算更便宜
- 让更新更克制
- 还是让结构更容易模块化复用
1.2 一个直觉版本的统一理解
可以先把“升维”和“降维”想象成在做两种不同的资源分配。
- 升维:给表示更多活动空间,让模型有能力表达更细的结构差异。
- 降维:把表示或更新压回一个更小的子空间,让模型只保留最关键的方向。
这就像你在整理资料。
- 当你只是把一堆便签随手堆在一起时,信息很挤,也容易混。
- 当你给它们分门别类、开更多抽屉时,本质上是在“升维”,让不同因素能被分开表达。
- 但抽屉太多也会混乱、占空间,所以你又会把重复内容归档、压缩成几条主线,这又是在“降维”。
模型也是这样:
- 如果表示一直挤在一个狭窄空间里,很多因素会纠缠在一起,难以分开处理。
- 如果表示无限膨胀而不回收,参数量、显存和计算都会迅速失控。
所以很多经典结构都长成了一个重复模式:
升维 → 非线性或结构化处理 → 降维
text{升维} ;rightarrow; text{非线性或结构化处理} ;rightarrow; text{降维}
升维→非线性或结构化处理→降维
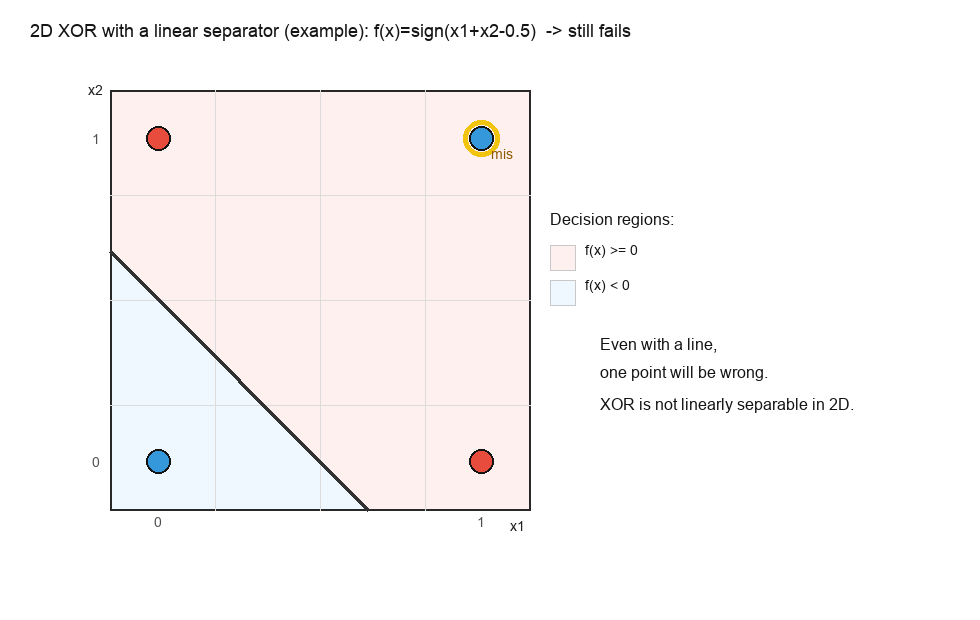
1.2.1 一个具体数值小例子:二维 XOR 不可分,但升到三维就可分
为了把“升维到底在帮什么忙”讲得更落地,我们用一个最经典、最干净的小数据集:XOR。
我们有四个二维点(可以想象成“同一批人”的两个二值特征):
(0,0),(0,1),(1,0),(1,1)
(0,0),(0,1),(1,0),(1,1)
(0,0),(0,1),(1,0),(1,1)
定义 XOR 标签(只要两个特征恰好有一个为 1,则为正类):
y=x1⊕x2
y = x_1 oplus x_2
y=x1⊕x2
也就是:
- 正类(y=1y=1y=1):(0,1)(0,1)(0,1)、(1,0)(1,0)(1,0)
- 负类(y=0y=0y=0):(0,0)(0,0)(0,0)、(1,1)(1,1)(1,1)
第一步:说明二维里用一条直线分不开(线性不可分)。
假设存在二维线性分类器:
f(x)=sign(ax1+bx2+c)
f(x)=mathrm{sign}(a x_1 + b x_2 + c)
f(x)=sign(ax1+bx2+c)
要把 XOR 分开,就必须同时满足下面四个不等式(把正类判为正、负类判为负):
f(0,1)>0⇒b+c>0f(1,0)>0⇒a+c>0f(0,0)<0⇒c<0f(1,1)<0⇒a+b+c<0
begin{aligned}
f(0,1)>0 &Rightarrow b + c > 0 \
f(1,0)>0 &Rightarrow a + c > 0 \
f(0,0)<0 &Rightarrow c < 0 \
f(1,1)<0 &Rightarrow a + b + c < 0
end{aligned}
f(0,1)>0f(1,0)>0f(0,0)<0f(1,1)<0⇒b+c>0⇒a+c>0⇒c<0⇒a+b+c<0
把前两条加起来得到:
a+b+2c>0
a + b + 2c > 0
a+b+2c>0
再结合 a+b+c<0a+b+c<0a+b+c<0,两式相减得到 c>0c>0c>0,这与 c<0c<0c<0 矛盾。
所以 XOR 在二维里没有任何一条直线能把正负类分开。
下面这张图把 XOR 的四个点画在二维平面里(红色是正类,蓝色是负类)。你会直观看到:它们呈现“对角交叉”的结构,因此想用一条直线干净切开几乎是不可能的。
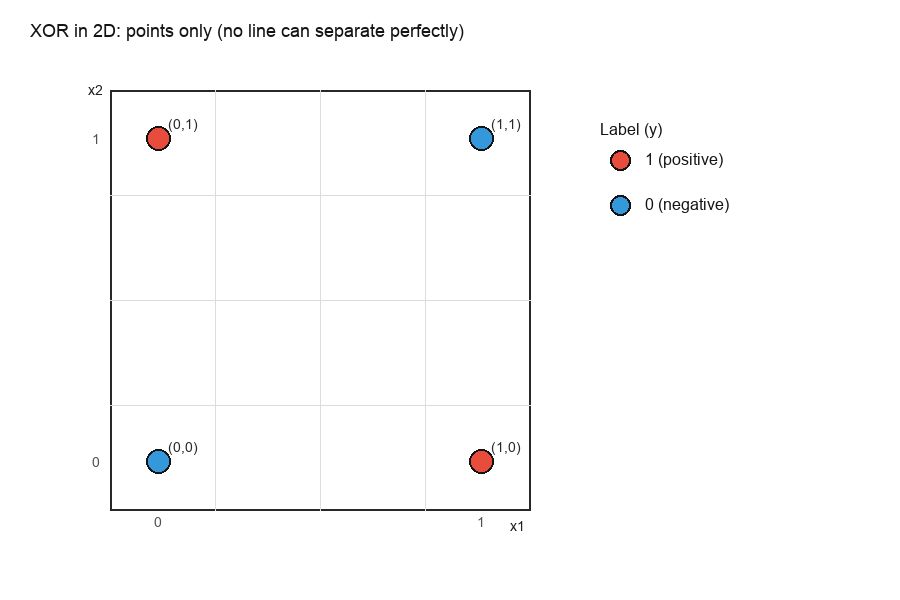
如果你还想更具体一点,这里给一个“随便选一条直线”的失败示意:我们画出一个线性分类器的分割线与它的决策区域,你会看到总会有点被分错(图中用黄色圈出了误分点)。这不是这条线选得不好,而是 XOR 在二维里本来就线性不可分。
第二步:升到三维,用一个简单的特征变换就能线性可分。
我们做一个非常简单的升维映射:加一个“交叉特征”:
ϕ(x)=[x1x2x1x2]∈R3
phi(x)=
begin{bmatrix}
x_1\
x_2\
x_1x_2
end{bmatrix}
inmathbb{R}^3
ϕ(x)=x1x2x1x2∈R3
把四个点映射到三维后分别是:
ϕ(0,0)=(0,0,0)ϕ(0,1)=(0,1,0)ϕ(1,0)=(1,0,0)ϕ(1,1)=(1,1,1)
begin{aligned}
phi(0,0)&=(0,0,0) \
phi(0,1)&=(0,1,0) \
phi(1,0)&=(1,0,0) \
phi(1,1)&=(1,1,1)
end{aligned}
ϕ(0,0)ϕ(0,1)ϕ(1,0)ϕ(1,1)=(0,0,0)=(0,1,0)=(1,0,0)=(1,1,1)
现在我们给出一个具体的三维超平面(线性分类器):
g(x)=w⊤ϕ(x)+b,w=[11−2],b=−12
g(x)=w^top phi(x) + b,quad
w=
begin{bmatrix}
1\
1\
-2
end{bmatrix},
quad b=-frac{1}{2}
g(x)=w⊤ϕ(x)+b,w=11−2,b=−21
逐点代入计算:
g(0,0)=(1,1,−2)⋅(0,0,0)−12=−12<0g(0,1)=(1,1,−2)⋅(0,1,0)−12=1−12=12>0g(1,0)=(1,1,−2)⋅(1,0,0)−12=1−12=12>0g(1,1)=(1,1,−2)⋅(1,1,1)−12=(1+1−2)−12=−12<0
begin{aligned}
g(0,0) &= (1,1,-2)cdot(0,0,0) – tfrac{1}{2} = -tfrac{1}{2} < 0 \
g(0,1) &= (1,1,-2)cdot(0,1,0) – tfrac{1}{2} = 1 – tfrac{1}{2} = tfrac{1}{2} > 0 \
g(1,0) &= (1,1,-2)cdot(1,0,0) – tfrac{1}{2} = 1 – tfrac{1}{2} = tfrac{1}{2} > 0 \
g(1,1) &= (1,1,-2)cdot(1,1,1) – tfrac{1}{2} = (1+1-2) – tfrac{1}{2} = -tfrac{1}{2} < 0
end{aligned}
g(0,0)g(0,1)g(1,0)g(1,1)=(1,1,−2)⋅(0,0,0)−21=−21<0=(1,1,−2)⋅(0,1,0)−21=1−21=21>0=(1,1,−2)⋅(1,0,0)−21=1−21=21>0=(1,1,−2)⋅(1,1,1)−21=(1+1−2)−21=−21<0
你会发现:在三维空间里,我们用一个超平面就把 XOR 的正负类分开了。
这张图展示了升维后的 3D 空间(ϕ(x)=(x1,x2,x1x2)phi(x)=(x_1,x_2,x_1x_2)ϕ(x)=(x1,x2,x1x2))里,超平面 g(x)=w⊤ϕ(x)+b=0g(x)=w^topphi(x)+b=0g(x)=w⊤ϕ(x)+b=0(半透明灰色)是如何把四个点分开的。
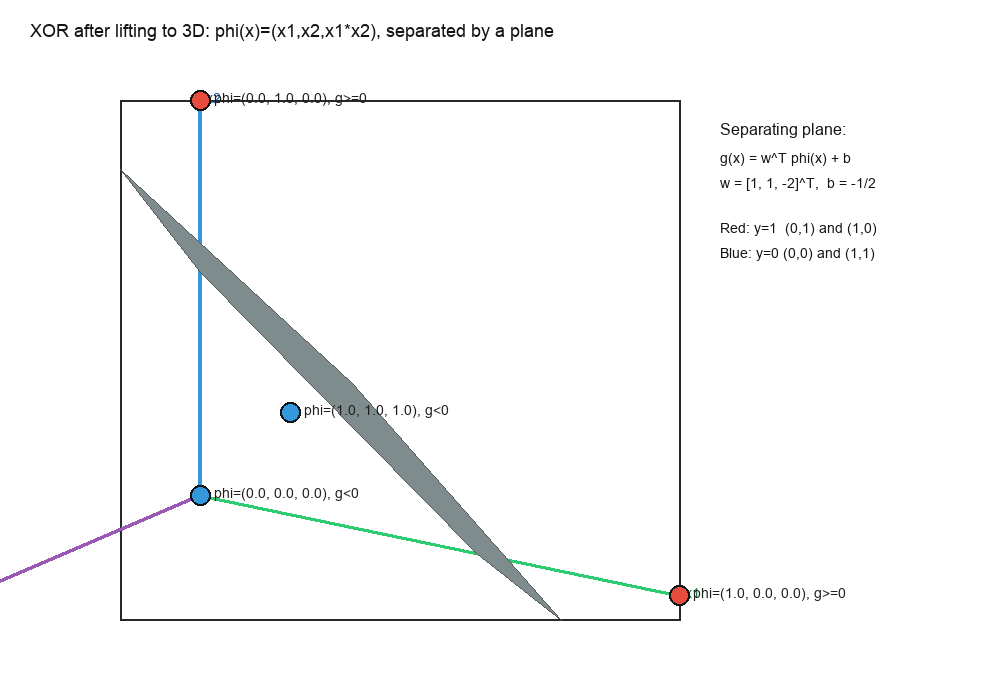
这就是“升维”的一个最本质价值:原空间里需要弯弯绕绕的决策边界,可能在高维里变成一刀切的线性边界。后面你看到 FFN 的升维、门控非线性、再降维,本质上就是在自动学习大量类似 x1x2x_1x_2x1x2 这样的交叉特征,只不过规模大得多、而且是端到端学出来的。
1.2.2 贯穿例子:一个学生的志愿问题,如何“检索”出更合适的建议
上面的 XOR 是一个“极简二维玩具”。现在我们用一个更贴近现实、也更适合贯穿全文的例子:对某一个具体学生,给出更合理的志愿建议。
这一章里你只需要抓住一个直觉:你在做志愿咨询时,往往不是“凭空算出来”的,而是会在脑子里(或案例库里)快速检索:
- 和他成绩结构相近的人当年怎么选
- 这条路线常见的坑是什么
- 这个偏好组合通常会把人引向哪几类学校/专业
这件事非常像注意力:给定一个“当前学生的志愿问题”,去匹配一堆“候选信息片段”,再把最相关的内容加权汇总。
我们把符号一次性定下来(后面第 3-6 章会反复复用同一套符号):
- 当前学生:sss,其向量表示为 x∈Rdmodelx in mathbb{R}^{d_{model}}x∈Rdmodel
- 当前问题(例如“理科强、想留省内、预算一般,志愿怎么填”):q∈Rdmodelq in mathbb{R}^{d_{model}}q∈Rdmodel
- 一个案例库/知识库,包含 NNN 条候选条目 {ci}i=1N{c_i}_{i=1}^{N}{ci}i=1N
- 每条条目可以是“历史学生画像 + 结果”、也可以是“专家规则片段”、也可以是“学校/专业信息块”
- 每条条目的向量表示为 zi∈Rdmodelz_i in mathbb{R}^{d_{model}}zi∈Rdmodel
然后我们用 Q/K/V 的方式把“当前问题”变成查询,把“候选条目”变成可匹配的键和值:
q′=qWQ,ki=ziWK,vi=ziWV
q' = qW_Q,qquad k_i = z_i W_K,qquad v_i = z_i W_V
q′=qWQ,ki=ziWK,vi=ziWV
注意力权重与汇总就是:
αi=softmax(q′ki⊤dk),out=∑i=1Nαivi
alpha_i = mathrm{softmax}left(frac{q' k_i^top}{sqrt{d_k}}right),qquad
mathrm{out} = sum_{i=1}^{N} alpha_i v_i
αi=softmax(dkq′ki⊤),out=i=1∑Nαivi
这段看起来像公式,但直觉上非常像“资深老师的思考过程”:
- qqq 是你当前正在回答的志愿问题
- kik_iki 是案例库里每条信息的“索引卡片”(方便匹配)
- viv_ivi 是这条信息真正能贡献的“内容”(能用于生成建议)
- αialpha_iαi 是“这条信息在当前问题下有多相关”
这个例子之所以适合贯穿全文,是因为它能把后面几章自然串成一条线:
- 第 3 章
Embedding:xxx、qqq、ziz_izi 从哪来?离散特征、文本描述、偏好约束如何变成可训练向量 - 第 4 章
Q/K/V:为什么要把同一个语义对象拆成 q′/ki/viq'/k_i/v_iq′/ki/vi 三种角色(用不同投影承担不同职责) - 第 5 章
FFN:为什么要把表示先升维到 dffd_{ff}dff 再降回 dmodeld_{model}dmodel?可以理解成“自动造交叉特征”,让匹配更容易发生 - 第 6 章
LoRA:当策略口径变了(比如更看重就业、城市或专业稳定性)怎么办?不重建整个空间,只用低秩更新 ΔWDelta WΔW 快速挪动关键方向
为了先看一下这个贯穿例子的整体效果,这里给一个自上而下的示意图(重点是“当前问题检索案例库”,而不是“学生之间互相加权”):
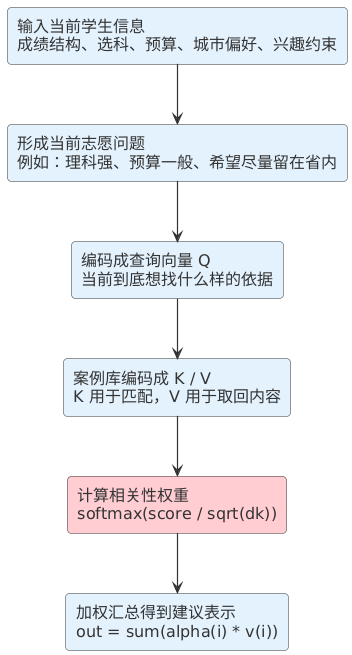
神经网络里的很多设计,本质上就在做这种事情。它不是真的执着于维度数字本身,而是在调节:
- 表征容量
- 参数预算
- 计算成本
- 优化稳定性
- 泛化与遗忘之间的平衡
如果只用一句话概括,可以是:
升维往往不是为了“信息更多”,而是为了“把可分的因素分开”;降维往往不是为了“信息更少”,而是为了“把自由度收拢到最值钱的方向上”。
这句话听起来抽象,但对应到 Transformer 的几个经典部件会非常具体:
-
Embedding的升维:把离散 token 变成稠密向量,允许“相似词”在空间里靠近 -
Q/K/V的投影:把同一个隐藏状态拆成不同用途的表示(检索键、检索请求、内容载体) -
FFN的升维再降维:给非线性组合留空间,然后把结果压回主干维度 -
LoRA的低秩:不是让激活先降维再升维,而是让“可训练更新的自由度”先被压到一个秩为 rrr 的瓶颈里
为了帮助你后面快速对号入座,这里给一个“训练里常见 projection”的总览图(自上而下布局,后面章节会逐个展开):

字体的环境依赖缘故,图中汉字为『门』控
1.3 这篇文章里“projection”有三层含义(以及一个命名陷阱)
后面我们会频繁用到 projection,但必须先把语义拆开,不然后面一定会混:
-
普通线性映射
- 例如 Q=XWQQ = XW_QQ=XWQ。
- 它不一定是严格意义上的正交投影,只是工程里习惯叫
proj。
-
维度变化意义上的升维/降维
- 例如
up_proj把维度从 dmodeld_{model}dmodel 提到 dffd_{ff}dff,down_proj再降回去。
- 例如
-
低秩约束
- 例如
LoRA用秩为 rrr 的分解限制更新矩阵的自由度。
- 例如
-
命名陷阱(最容易误会的一点)
- 很多实现里把“线性层”统一叫
*_proj,它可能只是在做y = Wx,并不代表数学上严格的“投影算子”。
- 很多实现里把“线性层”统一叫
从名字上看都叫 projection,但它们在数学对象、作用时机和工程目的上都不同。一个简单的判断法是:遇到 proj,先问自己三件事。
- 这个
proj在前向里出现吗?如果是,大概率就是线性映射(注意力/FFN/embedding 的某一段) - 这个
proj改变维度了吗?如果是,通常就是升维/降维结构(比如up_proj/down_proj) - 这个
proj的参数量是不是刻意受限(比如 rank 很小)?如果是,通常是在做低秩约束(比如LoRA)
这三问不需要你懂任何高深数学,但能让你读代码时不至于把“线性映射”和“正交投影”混为一谈。
如果要再口语化一点,可以这么分:
-
Q/K/V/O:像同一个人换了四种工牌,身份没变,但职责不同 -
up_proj/down_proj:像先把桌子铺大再摆菜,摆完还得收回主桌面 -
LoRA:像不给整栋楼重装,只在关键几根水管上加一个小旁路
1.4 先给出全文结论
提前说结论,这样你后面看公式时会更有方向感:
-
Embedding与特征扩张,解决的是如何把离散或纠缠的信息放进可学习的连续空间。 - 注意力投影,解决的是如何把同一个表示拆成“检索视角”“被检索视角”“内容视角”。
-
FFN的先升后降,解决的是如何在 token 内部构造更强的非线性特征组合能力。 -
LoRA的低秩分解,解决的是如何用极少的参数更新逼近有用的更新方向。 -
LLaMA的结构变体(例如门控FFN、GQA),解决的是在几乎不改变总框架的前提下,重新分配维度与计算预算。
换句话说,升维/降维并不是一条孤立技巧,而是一整套关于表达与约束如何分配的设计哲学。
1.5 本章小结
这一章先把问题立住:训练中反复出现的升维、降维、projection,并不是重复造轮子,而是在不同层面处理同一个核心矛盾。从第 2 章起,补最少够用的线性代数工具,再逐步进入 Transformer、LoRA 和 LLaMA。
第 2 章 线性代数底座:升维、降维、秩与投影
本章给后文打数学地基:当你看到一个
W、一个proj、一个rank时,能迅速判断它在“限制/扩展什么自由度”。本章会稍微偏数学,但只保留支撑后文所需的部分。
2.1 为什么神经网络几乎处处都是矩阵乘法
先从最小单元开始。把一层线性层写出来:
y=Wx+b
y = Wx + b
y=Wx+b
其中 x∈Rdinx in mathbb{R}^{d_{in}}x∈Rdin,y∈Rdouty in mathbb{R}^{d_{out}}y∈Rdout,W∈Rdout×dinW in mathbb{R}^{d_{out} times d_{in}}W∈Rdout×din,b∈Rdoutb in mathbb{R}^{d_{out}}b∈Rdout。
如果你更喜欢“看形状”而不是“看抽象定义”,那这一层其实就只在回答一个问题:
Rdin⟶Rdout
mathbb{R}^{d_{in}} longrightarrow mathbb{R}^{d_{out}}
Rdin⟶Rdout
也就是说,输入原来活在一个 dind_{in}din 维空间里,经过 WWW 之后,被送进了另一个 doutd_{out}dout 维空间。
这件事有两个关键含义:
-
“升维/降维”首先是形状变化。
- 如果 dout>dind_{out} > d_{in}dout>din,你可以把它叫升维(更宽的输出空间)。
- 如果 dout<dind_{out} < d_{in}dout<din,你可以把它叫降维(更窄的输出空间)。
-
线性层是在“换坐标系 + 重新组合”。
- WWW 的每一行都是一个“从输入里抽取特征”的方向。
- yiy_iyi 可以理解为把 xxx 投到第 iii 个方向上(严格说这是内积),再加偏置。
把它放回生活里,其实很像你拿一份简历去做不同维度的打分。
- 一个面试官更看重项目经验
- 一个面试官更看重数学基础
- 一个面试官更看重表达能力
同一份输入材料,经过不同“打分方向”之后,就会得到一组新的数值。矩阵 WWW 做的,本质上就是这种“按不同角度重新看一遍输入”的事。
你可能会问:既然线性层这么基础,为什么还要在模型里反复堆叠很多线性层?
因为单个线性层无论多宽,本质上还是线性变换。真正让模型变强的是“线性层 + 非线性 + 结构化组合”的反复堆叠:
-
Transformer的注意力:用 Q/K/VQ/K/VQ/K/V 的线性映射,把“相似度计算”和“内容聚合”组织成一个可微的全局信息路由 -
FFN:用升维后的非线性,把 token 内部的特征组合能力推到更强
在工程上,你会看到我们很少显式写出 bbb。原因是:
- 在许多 Transformer 实现里,某些 projection 层会省略 bias(或把 bias 吸收到其他层里),这不会改变我们在本文里讨论的“维度与自由度”逻辑。
2.2 线性映射不等于正交投影
这是第一个必须澄清的概念:工程里叫 proj,通常只是“线性层”;数学里叫“投影”,有更强的约束。
数学上,一个投影算子(projection operator) PPP 通常满足:
P2=P
P^2 = P
P2=P
这句话的意思是:投一次和投两次效果一样(已经落到子空间里了,再投也不会变)。
而正交投影(orthogonal projection) 还额外满足对称性:
P⊤=P
P^top = P
P⊤=P
对应的几何直觉是:xxx 被投影到某个子空间 Smathcal{S}S 上得到 PxPxPx,并且误差 x−Pxx – Pxx−Px 与子空间正交。
如果你学过最小二乘,其实这里有一个非常经典的公式。假设子空间 Smathcal{S}S 由矩阵 AAA 的列向量张成,那么投影到这个子空间的正交投影矩阵可以写成:
P=A(A⊤A)−1A⊤
P = A(A^top A)^{-1}A^top
P=A(A⊤A)−1A⊤
于是任意向量 xxx 在这个子空间上的正交投影就是:
x^=Px=A(A⊤A)−1A⊤x
hat x = Px = A(A^top A)^{-1}A^top x
x=Px=A(A⊤A)−1A⊤x
这个公式背后的直觉非常生活化:像手电筒打影子。
- 原始物体是 xxx
- 墙面就是你允许保留的子空间 Smathcal{S}S
- 投影后的影子是 x^hat xx
影子肯定丢失了一些三维信息,但在“墙面这个约束”下,它已经是距离原物体最近的表示了。
反过来,一般线性层 WWW:
- 既不要求 W2=WW^2 = WW2=W
- 也不要求 W⊤=WW^top = WW⊤=W
所以绝大多数 q_proj/k_proj/v_proj 在数学上不是“投影算子”,只是线性映射。
那为什么工程上还爱叫 proj?
因为在模型结构里,它们经常承担“把一个表示映射到另一个用途/子空间”的角色,比如从 dmodeld_{model}dmodel 映射到每个 head 的 dkd_kdk 或 dvd_vdv。这里的“子空间”更多是语义上的子空间(不同 head、不同角色),而不是线性代数里严格定义的一个固定子空间。
结论:看到
*_proj时,不要自动脑补“正交投影”,先把它当作“线性层”,需要严格投影时我们会明确写出 P2=PP^2=PP2=P 这种性质。
2.3 秩是什么,为什么低秩代表受限自由度
矩阵的秩(rank)是理解 LoRA 的关键钥匙。
给定 W∈Rdout×dinW in mathbb{R}^{d_{out} times d_{in}}W∈Rdout×din,它的秩 rank(W)mathrm{rank}(W)rank(W) 可以理解为:
- WWW 的列向量中最多有多少个线性无关方向
- 等价地:WWW 的行向量中最多有多少个线性无关方向
- 更本质地:线性变换 x↦Wxx mapsto Wxx↦Wx 的像空间(输出可达子空间)的维度
把这个定义翻译成“升降维语境”的直觉就是:
就算 doutd_{out}dout 很大,如果 rank(W)=rmathrm{rank}(W)=rrank(W)=r 很小,那么所有输出 WxWxWx 都只能落在 Rdoutmathbb{R}^{d_{out}}Rdout 里的一个 rrr 维子空间里。
所以“输出空间大”不代表“有效自由度大”。参数矩阵看起来很大,也不代表它能沿很多独立方向变化。
当我们说“低秩约束”,本质上是在说:我们愿意把可训练自由度限制在 rrr 个主方向上,因为很多时候这已经足够拟合任务差异,同时还能显著节省参数与带来更稳定的训练。
如果你更习惯从分解角度理解,也可以把秩 rrr 的矩阵看成:
W=∑i=1raibi⊤
W = sum_{i=1}^{r} a_i b_i^top
W=i=1∑raibi⊤
它最多只由 rrr 个“方向对”叠加而成。这意味着它不是不能表达变化,而是只能沿着少数几个主通道表达变化。
下一章我们会看到 LoRA 把更新写成 ΔW=BADelta W = BAΔW=BA,其中 A∈Rr×dinA in mathbb{R}^{r times d_{in}}A∈Rr×din,B∈Rdout×rB in mathbb{R}^{d_{out} times r}B∈Rdout×r,这直接保证了:
rank(ΔW)≤r
mathrm{rank}(Delta W) le r
rank(ΔW)≤r
这就是“用结构强行限制自由度”的典型例子。
2.4 奇异值分解与最优低秩近似
核心公式:
W=UΣV⊤
W = U Sigma V^top
W=UΣV⊤
W≈UrΣrVr⊤
W approx U_r Sigma_r V_r^top
W≈UrΣrVr⊤
这两行公式背后,是一个非常强的结论:SVD 不只是分解,它还给出了“什么是最重要方向”的排序方式。
2.4.1 SVD 的可读形式
把 W=UΣV⊤W = USigma V^topW=UΣV⊤ 写得更“可解释”一点:
- U=[u1,…,udout]U = [u_1,dots,u_{d_{out}}]U=[u1,…,udout] 是输出空间的一组正交基
- V=[v1,…,vdin]V = [v_1,dots,v_{d_{in}}]V=[v1,…,vdin] 是输入空间的一组正交基
- Σ=diag(σ1,σ2,… )Sigma = mathrm{diag}(sigma_1,sigma_2,dots)Σ=diag(σ1,σ2,…),其中 σ1≥σ2≥⋯≥0sigma_1 ge sigma_2 ge cdots ge 0σ1≥σ2≥⋯≥0
于是:
W=∑i=1min(dout,din)σi uivi⊤
W = sum_{i=1}^{min(d_{out},d_{in})} sigma_i , u_i v_i^top
W=i=1∑min(dout,din)σiuivi⊤
每一项 σiuivi⊤sigma_i u_i v_i^topσiuivi⊤ 都是一个秩为 1 的矩阵:它把输入沿 viv_ivi 的分量抽出来,映射到输出方向 uiu_iui 上,并用 σisigma_iσi 控制强度。
所以奇异值大小 σisigma_iσi 可以被看成“第 iii 个通道的重要程度”。
这时你可以把 SVD 想成把一大堆混杂的信息,拆成一层层“主成分包裹”。
- 最大的 σ1sigma_1σ1 对应最粗、最显眼的主方向
- 后面的 σ2,σ3,…sigma_2,sigma_3,dotsσ2,σ3,… 依次描述更细、更次要的变化
这很像你在收拾房间时先收“大件”,再收“小件”。先把最占空间、最影响视觉的东西归位,房间很快就“像样了”;后面那些零碎杂物当然也重要,但对整体轮廓的影响没那么大。
2.4.2 为什么截断 SVD 是“最优低秩近似”
如果我们只保留前 rrr 项:
Wr=∑i=1rσi uivi⊤
W_r = sum_{i=1}^{r} sigma_i , u_i v_i^top
Wr=i=1∑rσiuivi⊤
那么 WrW_rWr 的秩不超过 rrr,并且它在一个很强的意义下是最好的:在所有秩不超过 rrr 的矩阵中,WrW_rWr 使得 WWW 的重构误差最小(Eckart-Young-Mirsky 定理)。
用 Frobenius 范数(也就是把所有元素平方加和开根)来写,就是:
Wr=argminrank(X)≤r∥W−X∥F
W_r = argmin_{mathrm{rank}(X)le r} |W – X|_F
Wr=argrank(X)≤rmin∥W−X∥F
并且最小误差有闭式表达:
∥W−Wr∥F2=∑i=r+1min(dout,din)σi2
|W – W_r|_F^2 = sum_{i=r+1}^{min(d_{out},d_{in})} sigma_i^2
∥W−Wr∥F2=i=r+1∑min(dout,din)σi2
这条公式给了你一个非常“工程友好”的直觉:
当 σisigma_iσi 衰减很快时,用很小的 rrr 就能保留大部分能量;这正是低秩方法在大模型里经常有效的原因之一。
你也可以把它理解成一种“先抓大头”的压缩逻辑:
- 如果前几个奇异值已经占了绝大多数能量
- 那么后面很长一串小奇异值虽然存在,但对整体结构的贡献有限
这正是很多压缩、降维、参数高效微调方法能成立的心理基础:不是所有方向都同样重要。
(严格证明通常利用范数的酉不变性与对角矩阵的最佳截断性质;此处直接使用结论,把它作为理解 LoRA rank 的核心数学支撑。)
2.4.3 这和 LoRA 有什么关系
LoRA 并不是直接对 WWW 做 SVD 截断,而是把“更新量”写成低秩形式:
W′=W+ΔW,ΔW=BA
W' = W + Delta W,quad Delta W = BA
W′=W+ΔW,ΔW=BA
如果你把训练过程中真实需要的更新量(假想的全量微调更新)记为 ΔW⋆Delta W^starΔW⋆,经验上它常常具有“能量集中在少数方向”的结构倾向。于是我们希望用一个 rank 很小的 ΔWDelta WΔW 去逼近它。
从生活里打个比方,这有点像你给老房子做翻修:
- 全量微调像把整栋楼全部拆掉重装
-
LoRA更像先判断“真正需要动的大改动其实集中在几条主干管线” - 于是你只在这些主干方向上加一个小型旁路系统
这就是为什么 LoRA 给人的感觉不是“我把模型能力砍掉了”,而更像“我假设真正有价值的改动集中在少数几个方向上”。
这就是为什么在很多任务上,rrr 取 8、16、32 这样的很小数值,也能达到很好的效果:你不是在把模型压成低秩,你是在把“允许更新的方向”压成低秩。
后面第 6 章会把这个想法用更工程化的语言解释清楚,并讨论 rrr 和效果/开销的关系。
2.5 本章小结
这一章我们建立了三个“后面会反复用到”的数学基石:
- 线性层 y=Wx+by=Wx+by=Wx+b 是所有升维/降维讨论的最小单元,升降维首先是矩阵形状变化
- 工程里叫
proj的东西,大部分只是线性映射;数学上“投影算子”需要满足 P2=PP^2=PP2=P(正交投影还要 P⊤=PP^top=PP⊤=P) - 秩 rank(W)mathrm{rank}(W)rank(W) 描述的是有效自由度;SVD 告诉我们“重要方向”如何排序,并给出最优低秩近似的严格结论
带着这三点进入后文,你会更容易把 FFN 的升维、Q/K/V 的投影、以及 LoRA rank 的低秩约束放到同一套语言里理解。
第 3 章 把学生信息变成向量:从离散特征到可训练 Embedding
回到高考志愿分流的例子:你之所以能“越看越清楚”,本质上是把离散信息(选科、标签、文本)变成了一个可学习的稠密空间表示 xxx。
3.1 One-hot 为什么几乎不可训练地低效
先从最朴素的表示方式说起。假设我们要表示一个离散类别,比如学生的选科组合、意向专业类别、城市偏好标签,最直接的方法是 one-hot。
如果一共有 VVV 个离散类别,那么第 iii 个类别可以写成:
ei=[0⋮1⋮0]∈RV
e_i =
begin{bmatrix}
0 \
vdots \
1 \
vdots \
end{bmatrix}
in mathbb{R}^{V}
ei=0⋮1⋮0∈RV
其中只有第 iii 维是 111,其他维度全是 000。
这个表示有一个明显优点:干净、明确、不歧义。 第 iii 类就是第 iii 类,谁也不会和谁混在一起。
但它的问题也一样明显:
-
维度很高,但信息非常稀。
- 如果类别数 VVV 很大,向量长度就会非常长。
- 但每次真正有用的只有一个位置。
-
类别之间没有“相似性结构”。
- 在
one-hot里,“人工智能”和“计算机科学”一样远,“人工智能”和“临床医学”也一样远。 - 这显然不符合真实世界的语义关系。
- 在
-
它几乎没法表达组合与迁移。
- 一个模型如果只看
one-hot,就很难天然学到“物化生”和“物化地”在某些维度上更接近,而“物化生”和“史政地”更远。
- 一个模型如果只看
这就是为什么 one-hot 虽然适合做“编号”,却不适合做“语义空间”。
one-hot最大的问题不是“太简单”,而是只会区分类别,不会表达类别之间的关系。
回到高考志愿分流的例子,这一点尤其明显。假设你只把“选科组合”“城市偏好”“预算区间”“职业兴趣”都当成 one-hot 标签扔进去,模型当然知道每个标签是谁,但它并不知道:
- “更看重城市平台”和“愿意接受跨省”通常更接近
- “物理强、数学强”和“适合理工”之间关系更近
- “预算敏感”和“志愿风险偏好低”在很多场景下会一起出现
也就是说,one-hot 能告诉模型“这是什么”,却很难直接告诉模型“它和别的东西像不像、近不近、能不能迁移地组合起来”。
3.2 Embedding 本质上是在学一个可微的语义坐标系
要解决上面的问题,最自然的办法就是:不要让离散类别直接活在 VVV 维稀疏空间里,而是把它们映射到一个更紧凑、可学习的稠密空间中。
如果词表/类别表大小是 VVV,目标 embedding 维度是 dmodeld_{model}dmodel,那么 embedding 矩阵可以写成:
E∈RV×dmodel
E in mathbb{R}^{V times d_{model}}
E∈RV×dmodel
第 iii 个离散符号对应的向量就是矩阵的第 iii 行:
xi=Ei∈Rdmodel
x_i = E_i in mathbb{R}^{d_{model}}
xi=Ei∈Rdmodel
如果你坚持从矩阵乘法的角度看,它也可以写成:
xi=ei⊤E
x_i = e_i^top E
xi=ei⊤E
其中 eie_iei 就是刚才那个 one-hot 向量。这个式子很值得停一下,因为它揭示了一个常被忽略的事实:
Embedding并不神秘,它本质上就是“用 one-hot 去乘一个可训练矩阵,然后把对应行取出来”。
也就是说,Embedding 可以被看成一种查表版线性层:
-
one-hot负责告诉你“该查哪一行” - 矩阵 EEE 负责存储每个离散类别对应的稠密表示
真正重要的地方在于:矩阵 EEE 不是手工写死的,而是在训练过程中被不断更新的。也正因为如此,模型会逐渐把“经常在类似上下文里出现、承担类似功能、或在任务上有相似作用”的符号,推到更接近的位置上。
如果把这件事翻成更生活化的话,Embedding 就是在学一个可微的语义坐标系。
- 不是简单地给每个标签发一个编号
- 而是给每个标签分配一组“连续坐标”
- 这些坐标会随着任务目标不断被调整
在高考志愿场景里,这就意味着模型可以逐渐学到:
- “偏理工”“数学强”“能接受跨省”在某些维度上更相关
- “重视城市平台”“更看重资源”在另一些维度上会靠得更近
- “预算受限”“风险偏好低”也可能形成另一组稳定的结构
你不需要显式告诉模型“这些特征彼此相似”,它会通过训练把这些关系编码进向量空间里。
3.3 高维稠密表示为什么比低维离散表示更有表达力
很多人第一次看到 Embedding 会有一个很自然的疑问:为什么非得映射到更高维、更稠密的空间里?低维一点不是更省吗?
答案不只是“空间更大”,更重要的是:高维空间允许不同属性被部分解耦。
举个非常贴近本文主线的理解方式。假设一个学生的向量表示是:
x∈Rdmodel
x in mathbb{R}^{d_{model}}
x∈Rdmodel
如果 dmodeld_{model}dmodel 太小,模型就必须把很多信息硬挤在少数几个维度里:
- 理科能力
- 语言表达
- 城市偏好
- 预算敏感度
- 风险偏好
- 专业兴趣
这些因素会彼此缠在一起,后面的模型层很难把它们重新拆开。
但如果 dmodeld_{model}dmodel 足够大,模型就可以把这些属性分散到不同方向上,哪怕不是“一维对应一个概念”那么干净,至少也能做到部分解耦。一旦属性开始被分开,后面的层就更容易做三件事:
- 选择性关注某些因素
- 组合多个因素形成更复杂的判断
- 在不破坏整体结构的前提下调整局部方向
这也是为什么高维表示往往更适合做下游的注意力和 FFN 加工。你可以把它理解成:先把学生档案整理进一个更有层次的抽屉柜里,下游检索和组合才不会乱。
不过这里也要补一句:高维不等于万能。
- 如果只是盲目把维度做大,而没有学到好的结构,那只是更贵的存储
- 真正有价值的是“高维 + 稠密 + 可训练 + 能被任务目标不断调整”
所以第 3 章和第 1 章其实是连在一起的:第 1 章回答“为什么有时必须先升维”,第 3 章回答“升上去之后,模型到底把这些维度拿来干什么”。
3.4 用高考志愿分流的例子,把 Embedding 再落地一次
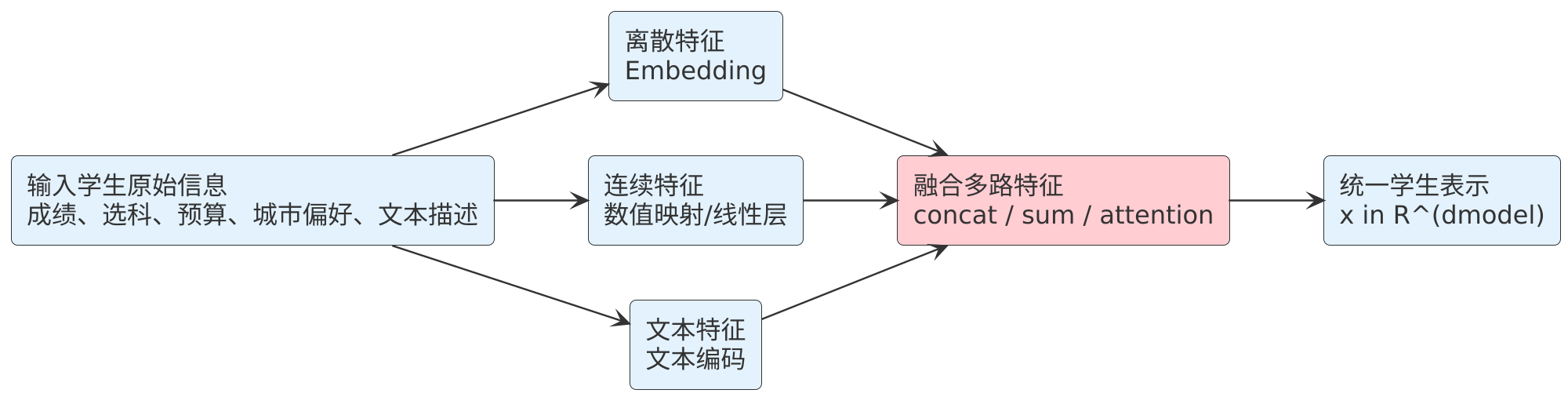
现在把上面的概念完整落回高考志愿场景。
一个学生的原始信息可能同时包含:
- 离散标签:选科组合、省份、城市偏好、预算区间
- 数值特征:数学成绩、语文成绩、总分、排名
- 文本信息:自述兴趣、倾向专业、限制条件
在进入模型之前,这些信息不会直接拿原始格式硬拼。更常见的做法是:
- 离散字段先映射成 embedding 向量
- 连续字段先做数值变换或小线性层映射
- 文本字段用词向量/子词向量/编码器表示
- 再把这些部分合成为统一的学生表示 xxx
如果写得抽象一点,可以记成:
x=f(score,subjects,budget,city_pref,text)
x = f(text{score}, text{subjects}, text{budget}, text{city_pref}, text{text})
x=f(score,subjects,budget,city_pref,text)
这里的 f(⋅)f(cdot)f(⋅) 不一定是单一线性层,它可以是一串编码与融合操作。但无论实现细节怎样,目标都一样:
把原本异构、离散、难以直接比较的学生信息,映射到一个下游模型可以继续加工的统一向量空间里。
一旦有了这个统一表示 xxx,后面的注意力层才有东西可检索,FFN 才有东西可组合,LoRA 也才有可以被低秩调整的方向。
3.5 学生信息如何进入统一表示空间
3.6 本章小结
这一章回答的是一个很基础但很关键的问题:后面所有“升维、降维、投影、注意力”,到底是建立在什么表示之上的?
结论可以压缩成三句:
-
one-hot适合做编号,但不适合承载语义结构 -
Embedding本质上是查表版线性层,用来学习一个可微的语义坐标系 - 高维稠密表示的真正价值,不只是空间更大,而是它让不同属性更容易被部分解耦、被检索、被重新组合
有了这一层统一表示 xxx,我们下一章才能自然进入 Q/K/V:既然已经把学生信息和问题都放进了向量空间,接下来模型是怎样从案例库里“找依据”的?
第 4 章 提问-检索-汇总:用 Q/K/V 从案例库里“找依据”
回到高考志愿分流的例子:你在回答一个具体学生的问题时,更像是在检索一堆历史案例/知识条目并加权汇总,而不是凭空拍脑袋。
4.1 同一个向量为什么不能既当问题又当答案
先从直觉说起。假设你现在面前有一个具体问题:
这个学生理科强,预算一般,希望尽量留在省内,那他的志愿应该怎么填?
如果你真的是一位经验丰富的老师,你脑子里通常会同时做三件事:
- 把这个问题整理成“我要找什么”的样子
- 在历史案例、规则经验、学校信息里搜索“谁和它最像”
- 把搜到的相关信息汇总起来,形成建议
问题在于,这三件事虽然围绕同一个语义对象展开,但它们扮演的角色并不一样。
- “我要找什么”是查询视角
- “谁能和它匹配”是索引视角
- “匹配到之后真正要拿来用的内容”是内容视角
这就是为什么同一个表示不能简单地“一把梭”。
如果你把同一个向量同时拿来做“提问”和“答案”,模型就很难学到一种稳定的分工:哪些维度更适合做相似度比较,哪些维度更适合承载被聚合的内容。于是 Transformer 做了一个很关键的设计:同一个输入表示,先经过不同的线性映射,再分别承担不同角色。
用高考志愿场景来翻译:
-
Q:当前这个问题,到底想找什么样的依据 -
K:案例库里每条信息,如何把自己变成“方便被匹配”的索引卡片 -
V:案例库里每条信息,真正值得被读出来、被汇总的内容
这和图书馆找书非常像:
- 你脑子里的需求是
Q - 书目索引卡是
K - 书的正文内容是
V
你不会拿整本书正文直接去做索引检索;同样,模型也不会直接拿“原始表示”同时兼任所有角色。
Q/K/V的关键不是“多了三个矩阵”,而是把提问、匹配、取内容这三件事拆开学。
4.2 注意力的核心公式
Q=XWQ,K=XWK,V=XWV
Q = XW_Q, quad K = XW_K, quad V = XW_V
Q=XWQ,K=XWK,V=XWV
Attention(Q,K,V)=softmax(QK⊤dk)V
text{Attention}(Q,K,V) = text{softmax}left(frac{QK^top}{sqrt{d_k}}right)V
Attention(Q,K,V)=softmax(dkQK⊤)V
现在正式来看公式。
假设输入矩阵是:
X∈Rn×dmodel
X in mathbb{R}^{n times d_{model}}
X∈Rn×dmodel
其中 nnn 是序列长度,dmodeld_{model}dmodel 是隐藏维度。通过三组不同参数矩阵,我们得到:
Q=XWQ,K=XWK,V=XWV
Q = XW_Q,qquad K = XW_K,qquad V = XW_V
Q=XWQ,K=XWK,V=XWV
其中常见形状是:
WQ∈Rdmodel×dk,WK∈Rdmodel×dk,WV∈Rdmodel×dv
W_Q in mathbb{R}^{d_{model}times d_k},quad
W_K in mathbb{R}^{d_{model}times d_k},quad
W_V in mathbb{R}^{d_{model}times d_v}
WQ∈Rdmodel×dk,WK∈Rdmodel×dk,WV∈Rdmodel×dv
所以:
Q∈Rn×dk,K∈Rn×dk,V∈Rn×dv
Q in mathbb{R}^{ntimes d_k},quad
K in mathbb{R}^{ntimes d_k},quad
V in mathbb{R}^{ntimes d_v}
Q∈Rn×dk,K∈Rn×dk,V∈Rn×dv
接下来最关键的一步是:
QK⊤∈Rn×n
QK^top in mathbb{R}^{ntimes n}
QK⊤∈Rn×n
这个矩阵的第 (i,j)(i,j)(i,j) 个元素,本质上就是“第 iii 个查询和第 jjj 个键有多匹配”。
如果回到高考志愿的类比里,可以这样看:
- 第 iii 行对应“当前要回答的某个局部问题”
- 第 jjj 列对应“案例库/上下文里的第 jjj 条候选依据”
- 分数越高,说明这条候选依据越值得参考
为什么还要除以 dksqrt{d_k}dk?
QK⊤dk
frac{QK^top}{sqrt{d_k}}
dkQK⊤
因为当维度 dkd_kdk 变大时,内积的数值会自然变大,softmax 容易变得过于尖锐,导致训练不稳定。除以 dksqrt{d_k}dk 相当于做一个尺度校正,让分数保持在更合适的范围。
然后通过 softmax:
A=softmax(QK⊤dk)
A = text{softmax}left(frac{QK^top}{sqrt{d_k}}right)
A=softmax(dkQK⊤)
得到注意力权重矩阵 AAA。这里每一行都会被归一化成一组权重,总和为 111。这意味着:
- 它不是在做“硬检索”
- 而是在做“软检索”
- 也就是:不是只选一个最相关对象,而是允许多个候选条目按权重共同贡献
最后:
Attention(Q,K,V)=AV
text{Attention}(Q,K,V) = AV
Attention(Q,K,V)=AV
这一步表示:用刚刚算出的匹配权重,去对内容向量 VVV 做加权汇总。
这正是“提问-检索-汇总”的三步闭环:
-
Q决定我在找什么 -
K决定我如何判断“谁和问题相关” -
V决定我最终把什么内容拿回来
如果用一句话总结这一整套机制:
注意力不是“让所有信息互相看看”,而是“让当前问题有能力从一堆候选信息里按相关性挑出依据并汇总”。
再把它压回到单个查询的形式,假设只有一个查询向量 q′q'q′,以及一组候选键值对 {(ki,vi)}i=1N{(k_i,v_i)}_{i=1}^{N}{(ki,vi)}i=1N,那么它就写成:
αi=softmax(q′ki⊤dk),out=∑i=1Nαivi
alpha_i = text{softmax}left(frac{q'k_i^top}{sqrt{d_k}}right),qquad
text{out} = sum_{i=1}^{N}alpha_i v_i
αi=softmax(dkq′ki⊤),out=i=1∑Nαivi
这正好和第 1 章里那个“当前学生的问题去检索案例库”的贯穿例子一一对应。
4.3 多头注意力为什么本质上也是一种“子空间分工”
如果单头注意力已经能做“提问-检索-汇总”,为什么还要多头?
最直观的原因是:一个问题往往不止一个检索角度。
还拿高考志愿的例子说,同一个学生的问题,可能同时需要看:
- 成绩结构像不像
- 城市偏好像不像
- 风险承受能力像不像
- 专业兴趣像不像
如果只让一个头去学所有关系,它很容易把这些不同维度的判断揉在一起。多头注意力的做法是:把表示拆成多个子空间,让不同的头各自学习不同的匹配模式。
形式上,假设有 hhh 个头,每个头都有自己的投影矩阵:
Q(m)=XWQ(m),K(m)=XWK(m),V(m)=XWV(m),m=1,…,h
Q^{(m)} = XW_Q^{(m)},quad
K^{(m)} = XW_K^{(m)},quad
V^{(m)} = XW_V^{(m)},qquad m=1,dots,h
Q(m)=XWQ(m),K(m)=XWK(m),V(m)=XWV(m),m=1,…,h
每个头各自计算:
head(m)=softmax(Q(m)K(m)⊤dk)V(m)
text{head}^{(m)} = text{softmax}left(frac{Q^{(m)}{K^{(m)}}^top}{sqrt{d_k}}right)V^{(m)}
head(m)=softmax(dkQ(m)K(m)⊤)V(m)
最后再把多个头拼接起来并映射回主空间:
MultiHead(X)=Concat(head(1),…,head(h))WO
text{MultiHead}(X) = text{Concat}big(text{head}^{(1)},dots,text{head}^{(h)}big)W_O
MultiHead(X)=Concat(head(1),…,head(h))WO
这里最值得记住的,不是公式本身,而是它背后的结构直觉:
多头注意力不是简单地“多算几次”,而是在说:同一个输入表示,应该允许多个检索小组并行工作,每个小组从自己的角度找依据。
如果用一个更接地气的类比,它像是一个志愿咨询专案组:
- 一组老师重点看分数与选科
- 一组老师重点看城市与地域偏好
- 一组老师重点看预算与风险偏好
- 一组老师重点看专业兴趣与长期规划
最后把这些视角的结果汇总起来,形成一个更稳的建议。
这也是为什么多头注意力常常比单头更强:它不是单纯增加参数,而是在强行制造“子空间分工”。
4.4 原论文图
下面图直接来自 Attention Is All You Need 原论文
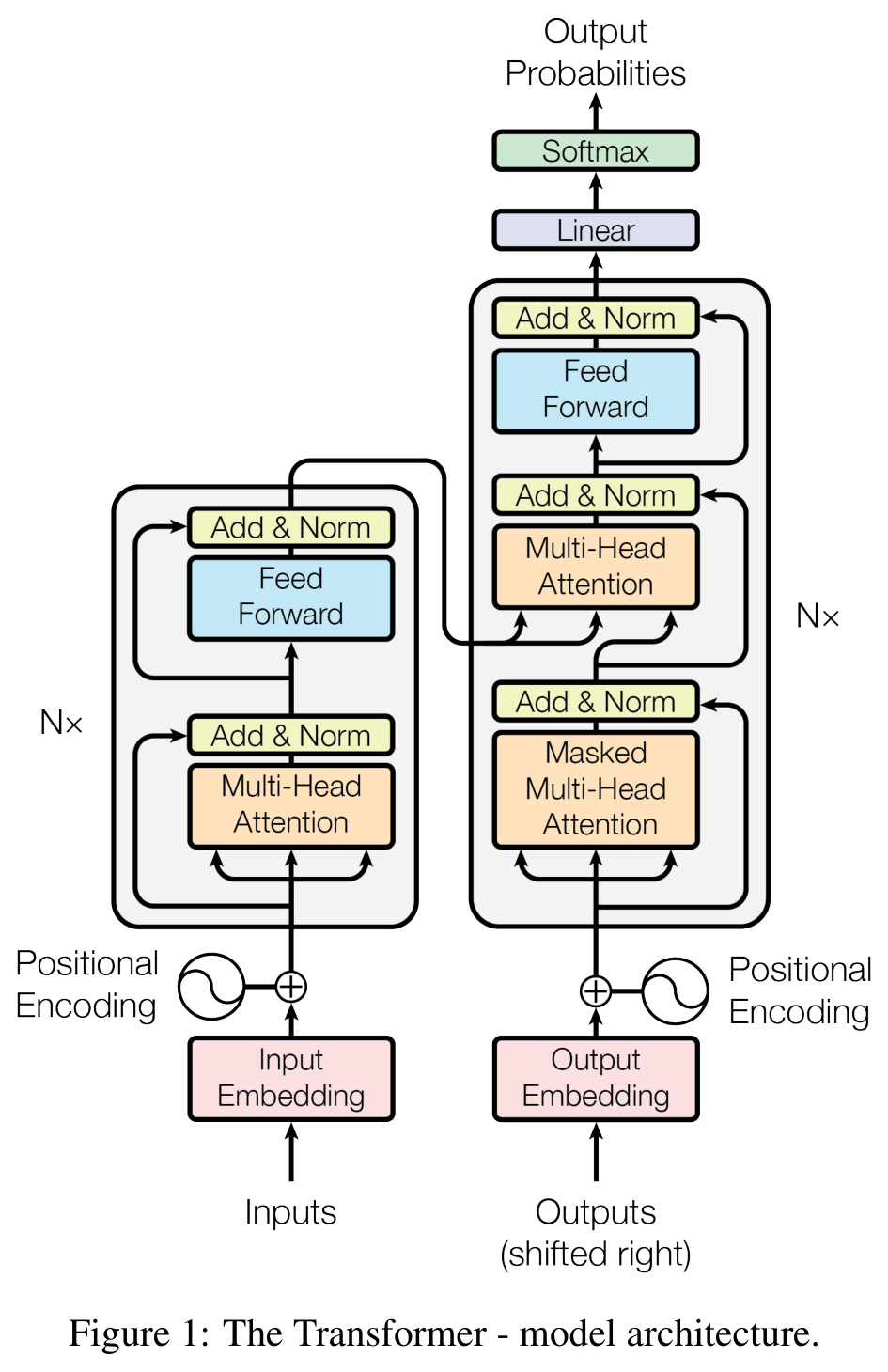
4.5 本章小结
这一章真正想讲透的,其实只有一句话:
注意力机制的本质,不是“大家互相看一眼”,而是“当前问题如何从候选信息里检索依据,再把依据汇总回来”。
从这个角度看:
-
Q负责定义“我要找什么” -
K负责定义“谁适合被匹配” -
V负责定义“匹配上以后拿回什么内容” - 多头注意力负责让不同子空间并行承担不同检索视角
有了这一层理解,你再回头看 Q/K/V/O 这些名字,就不会觉得它们只是一些莫名其妙的 proj 层,而会知道:它们是在把“提问-检索-汇总”这件事拆成可学习的模块。
既然模型已经能检索依据,下一步自然就是:拿回来的这些信息,怎样在 token 内部继续被重新组合? 这就会把我们带到下一章的 FFN。
第 5 章 自动造交叉特征:FFN 的先升维再降维
5.1 如果不升维,只在原空间里做非线性会怎样
第 4 章的注意力更像“去案例库里找依据”。但真正给出建议时,你还需要做一件更“本地”的事:把这些依据和当前学生的特征,在一个 token 的表示里重新组合,产出更像“结论”的表示。
在 Transformer 里,承担这个角色的就是 FFN(也常叫 MLP)。它的一个关键特点是:逐 token 处理。
- 注意力:负责跨 token 检索与汇总(把“外部信息”拿回来)
-
FFN:负责 token 内部的非线性组合(把“拿回来的信息”做出更高阶的结构)
现在回答你问的“如果不升维会怎样”:
如果我们把 FFN 简化到极致,只允许在同一维度里做一次线性变换(哪怕后面接激活),它能做的组合其实非常受限。更具体一点:
- 单纯的线性层只能学到“加权相加”的结构
- 而很多关键判断需要的是“组合关系”(交叉特征),例如:
- “理科强 并且 愿意跨省”通常导向不同建议
- “城市偏好强 且 预算敏感”会改变学校范围
这类“并且/交互”关系,恰好就是第 1 章 XOR 例子在玩具数据上的抽象:单靠一条直线(线性层)切不漂亮。
所以 FFN 的核心目标可以粗暴总结为一句:
把原空间里“分不开/组合不出来”的结构,搬到一个更宽的中间空间里,用非线性把它们拼出来,再压回主干表示。
5.2 FFN 的标准公式
FFN(x)=W2σ(W1x+b1)+b2
text{FFN}(x) = W_2 sigma(W_1 x + b_1) + b_2
FFN(x)=W2σ(W1x+b1)+b2
其中:
- W1∈Rdff×dmodelW_1 in mathbb{R}^{d_{ff} times d_{model}}W1∈Rdff×dmodel
- W2∈Rdmodel×dffW_2 in mathbb{R}^{d_{model} times d_{ff}}W2∈Rdmodel×dff
- 通常 dff>dmodeld_{ff} > d_{model}dff>dmodel
把这个式子按“升维-非线性-降维”拆开看:
- 升维:h=W1x+b1h = W_1x + b_1h=W1x+b1,把 dmodeld_{model}dmodel 维送到更宽的 dffd_{ff}dff 维
- 非线性:h~=σ(h)tilde h = sigma(h)h~=σ(h),在更宽空间里做非线性变换
- 降维:y=W2h~+b2y = W_2tilde h + b_2y=W2h~+b2,把结果压回 dmodeld_{model}dmodel
注意:这里的“升维”不是为了让最终输出维度变大(最后还是回到 dmodeld_{model}dmodel),而是为了让中间层有足够的“工作台面积”,去制造更丰富的交叉/组合特征。
在很多实现里,dffd_{ff}dff 常取 4dmodel4d_{model}4dmodel(例如 dmodel=4096d_{model}=4096dmodel=4096 时 dff=11008d_{ff}=11008dff=11008 或附近),这不是拍脑袋:它基本反映了“想要足够的非线性组合能力”与“算力/显存预算”之间的折中。
5.3 一个直觉:先把菜铺开,再重新组合
回到你熟悉的“志愿建议”场景。注意力解决的是“去哪里找依据”;但依据拿回来以后,还需要把它们变成一句可执行建议,这一步更像是在厨房里做菜:
- 你把食材(特征、证据)一股脑堆在案板上,信息都在,但很难直接出菜
- 先把食材切开、分类、摆盘(升维),让不同因素不再纠缠
- 然后按规则加热、混合、调味(非线性),做出“组合关系”
- 最后装盘上桌(降维),变回一个简洁的输出表示
所以 FFN 在 Transformer Block 里常被称作“逐 token 的非线性计算”,它不像注意力那样跨 token 交流,而更像“在每个 token 自己的脑子里做推理”。
5.4 从表达能力角度看“升维 -> 非线性 -> 降维”
这一小节我们把第 1 章的 XOR 例子正式接回来:FFN 为什么能“自动造交叉特征”?
关键点是:两层线性 + 非线性的组合,能表达很多“非线性可分”的结构。最直观的展示方式,就是写一个能精确实现 XOR 的小 FFN。
5.4.1 用一个两层 FFN 精确实现 XOR(可计算版)
我们仍然用第 1 章的输入:
x=[x1x2],(x1,x2)∈{0,1}2
x=
begin{bmatrix}
x_1\
x_2
end{bmatrix},
quad (x_1,x_2)in{0,1}^2
x=[x1x2],(x1,x2)∈{0,1}2
目标输出是:
y=x1⊕x2
y = x_1 oplus x_2
y=x1⊕x2
在第 1 章我们证明过:不存在一组 (a,b,c)(a,b,c)(a,b,c) 使得 sign(ax1+bx2+c)text{sign}(ax_1+bx_2+c)sign(ax1+bx2+c) 在二维里把 XOR 分开。
现在我们用一个非常小的 FFN,取激活函数为 ReLU:σ(t)=max(0,t)sigma(t)=max(0,t)σ(t)=max(0,t),并设:
W1=[1−1−11],b1=[00]
W_1 =
begin{bmatrix}
1 & -1\
-1 & 1
end{bmatrix},
quad b_1 =
begin{bmatrix}
0\
end{bmatrix}
W1=[1−1−11],b1=[00]
W2=[11],b2=0
W_2 =
begin{bmatrix}
1 & 1
end{bmatrix},
quad b_2 = 0
W2=[11],b2=0
于是:
h=W1x,h~=σ(h),y=W2h~
h = W_1x,quad
tilde h = sigma(h),quad
y = W_2tilde h
h=W1x,h~=σ(h),y=W2h~
把 h~tilde hh~ 写开,其实就是两条“自动造出来的交叉特征”:
h~1=max(0,x1−x2),h~2=max(0,x2−x1)
tilde h_1 = max(0, x_1-x_2),qquad
tilde h_2 = max(0, x_2-x_1)
h~1=max(0,x1−x2),h~2=max(0,x2−x1)
最后输出:
y=h~1+h~2=∣x1−x2∣
y = tilde h_1 + tilde h_2 = |x_1-x_2|
y=h~1+h~2=∣x1−x2∣
而当 (x1,x2)∈{0,1}2(x_1,x_2)in{0,1}^2(x1,x2)∈{0,1}2 时,∣x1−x2∣|x_1-x_2|∣x1−x2∣ 恰好就是 XOR 的标签(相等为 0,不等为 1)。
这个构造很重要,因为它说明:
-
FFN不需要显式写出 x1x2x_1x_2x1x2 这种乘法特征,也能通过“升维 + ReLU”造出一个可分的中间表示 - 中间层的维度(这里是 2)就是
d_{ff}的雏形:你给它多少宽度,就给它多少“造特征的工位”
5.4.2 回到 Transformer:d_{ff} 就是“造交叉特征的预算”
在真实的 Transformer 里,xxx 不是二维,而是 dmodeld_{model}dmodel 维;要处理的“交叉关系”也远比 XOR 复杂。
因此 FFN 的直觉就是:
- W1W_1W1 把信息投到更宽空间:把潜在的组合关系“展开”
- σsigmaσ 在宽空间里把空间切成更多区域(分段线性/门控)
- W2W_2W2 再把这些非线性结果压回主干表示
你可以把它理解成:注意力负责“找信息”,FFN 负责“把信息组合成结构”,而“升维”提供的是组合结构所需的容量。
5.5 LLaMA 中的 gate_proj / up_proj / down_proj
LLaMA 的 FFN 看起来“更显眼”,主要是因为它把 FFN 写成了门控结构(常见是 SwiGLU)。你会看到三个名字:
-
up_proj:升维分支之一 -
gate_proj:升维分支之二(用于门控) -
down_proj:降维,把结果压回 dmodeld_{model}dmodel
一种常见写法是:
FFN(x)=Wdown(σ(Wgatex)⊙(Wupx))
text{FFN}(x)=W_{text{down}}Big(sigma(W_{text{gate}}x)odot (W_{text{up}}x)Big)
FFN(x)=Wdown(σ(Wgatex)⊙(Wupx))
这里的 ⊙odot⊙ 是逐元素乘法。门控的直觉是:它让模型不仅能“生成一堆候选特征”(WupxW_{text{up}}xWupx),还能同时“决定哪些特征该放行”(σ(Wgatex)sigma(W_{text{gate}}x)σ(Wgatex))。
如果回到高考志愿建议的类比,门控像是:
- 你能想到很多因素(候选特征)
- 但你会根据当前问题,把其中一部分因素压下去,把另一部分因素抬上来
这类门控结构在实践里往往更强,也更稳定,因此 LLaMA 这类模型会让 FFN 变得更大、也更关键。
5.6 FFN 流程图

5.7 本章小结
这一章把“升维-非线性-降维”这条主线落在了 FFN 上,并把 XOR 例子接回来了:
- 注意力解决的是“检索依据”,
FFN解决的是“在 token 内部把依据组合成更高阶结构” -
FFN的 dff>dmodeld_{ff}>d_{model}dff>dmodel 不是为了输出更大维度,而是提供“造交叉特征的预算” - XOR 这个玩具例子说明:只要有升维和非线性,一个非常小的
FFN就能把二维线性不可分的问题变成可分 -
LLaMA的门控FFN(gate_proj/up_proj/down_proj)进一步增强了“生成特征 + 选择放行”的能力
下一章我们会把视角从“表征空间里的升降维”切到“参数更新空间里的低秩约束”:当建议口径变了,为什么 LoRA 能用很小的 rank 快速适配?
第 6 章 当口径变了怎么快速适配:LoRA 的低秩更新
继续沿用高考志愿分流的例子:当“建议口径”发生变化(更看重城市/就业/专业稳定性),你不想把整个模型重练一遍,而是希望用很小的可训练自由度快速把关键方向挪一挪。
6.1 全量微调的问题不只是显存大
先说清一个常见误解:大家提 LoRA 经常第一反应是“省显存”。显存当然重要,但如果你把它放到“高考志愿建议”这种长期运营的场景里,会发现更关键的问题其实是可控性和可维护性。
当“建议口径”变化时(例如更看重城市平台/就业导向/专业确定性),你通常希望做到的是:
- 只改动少数关键偏好,让建议风格可切换
- 不破坏底座已经学到的通用能力(语言、推理、检索与组合结构)
- 多套口径能并行存在、随时切换、易于部署
如果用全量微调(更新所有参数)来应对,会带来一串工程现实:
-
版本和部署成本高
- 每个口径一套完整模型,权重大、发布慢、灰度复杂
-
容易“牵一发而动全身”
- 你只想调某些偏好,但全量更新会在很多层同时变化,稳定性难控
-
多口径切换更笨重
- 你想“一个底座 + 多个适配器”,但全量微调等价于“多个大模型”
-
数据与训练成本更高
- 全量微调更依赖数据规模与正则化,否则更容易退化
所以这章的目标可以压缩成一句话:
冻结一套强底座,只允许你用很小的“改动预算”,把模型沿少数关键方向挪一下。
6.2 LoRA 的核心公式
W′=W+ΔW,ΔW=BA
W' = W + Delta W, quad Delta W = BA
W′=W+ΔW,ΔW=BA
其中:
- A∈Rr×dinA in mathbb{R}^{r times d_{in}}A∈Rr×din
- B∈Rdout×rB in mathbb{R}^{d_{out} times r}B∈Rdout×r
- r≪min(din,dout)r ll min(d_{in}, d_{out})r≪min(din,dout)
这行式子最关键的性质是:更新量天然是低秩的。
rank(ΔW)=rank(BA)≤r
mathrm{rank}(Delta W) = mathrm{rank}(BA) le r
rank(ΔW)=rank(BA)≤r
也就是说:你不是在“压缩权重矩阵 WWW”,你是在限制更新空间,只允许它在少数 rrr 个主方向上改变模型。
LoRA最值得记住的不是“省参数”,而是:它把更新限制成“少数几个主方向上的改动”。
工程实现里经常还会写成:
W′=W+αrBA
W' = W + frac{alpha}{r}BA
W′=W+rαBA
其中 αalphaα(也就是 lora_alpha)更像一个“旁路增益旋钮”。加上 α/ralpha/rα/r 的缩放后,不同 rrr 下的更新幅度更容易保持在同一量级,调参也更直观。
6.3 为什么这是“先降维再升维”
把 ΔW=BADelta W=BAΔW=BA 写成作用在输入上的形式更容易理解:
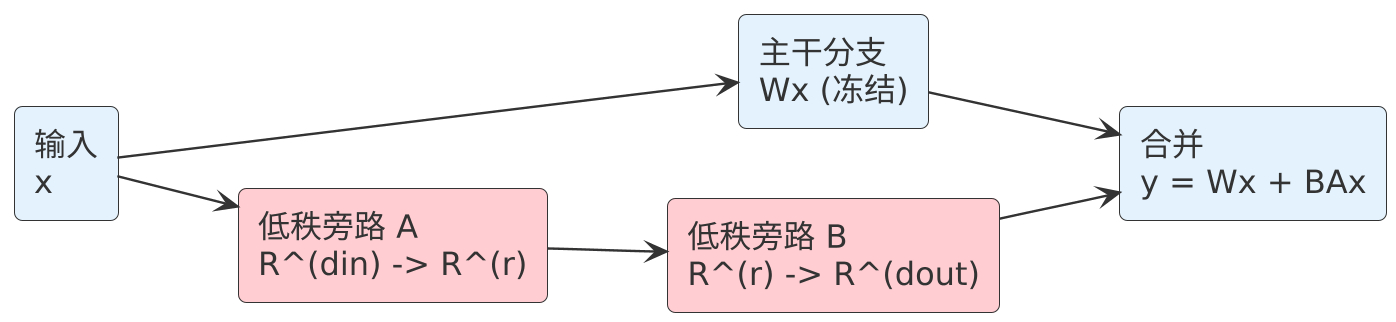
y=W′x=Wx+ΔWx=Wx+BAx
y = W'x = Wx + Delta W x = Wx + BAx
y=W′x=Wx+ΔWx=Wx+BAx
这条计算路径本身就是“先降维再升维”:
- A∈Rr×dinA in mathbb{R}^{rtimes d_{in}}A∈Rr×din:把 xxx 压到 rrr 维瓶颈空间(降维)
- B∈Rdout×rB in mathbb{R}^{d_{out}times r}B∈Rdout×r:再把瓶颈空间抬回输出空间(升维)
但这里的“降/升维”一定要读对:它不是第 5 章那种“表征空间为了造交叉特征而升维”,而是:
用一个 rrr 维瓶颈,限制“允许更新的自由度”。
因此 LoRA 的直觉不是“模型前向变简单了”,而是“训练时你给更新开了一个小旁路,并规定这条旁路只有 rrr 个自由方向”。
这也解释了它的参数效率:
- 全量更新:dout⋅dind_{out}cdot d_{in}dout⋅din
-
LoRA:r(din+dout)r(d_{in}+d_{out})r(din+dout)
当 r≪min(din,dout)r ll min(d_{in},d_{out})r≪min(din,dout) 时,差距会非常大。
6.4 用 SVD 视角理解 LoRA
第 2 章我们讲过一个核心事实:SVD 给出了“最优低秩近似”的意义,截断前 rrr 项可以保留主要能量。
把这个直觉搬到 LoRA 上,你可以把它理解成对更新量 ΔW⋆Delta W^starΔW⋆ 的一种假设:
有效的更新方向往往集中在少数几个主方向上,因此 ΔW⋆Delta W^starΔW⋆ 可以被一个低秩矩阵很好地逼近。
如果我们真的对 ΔW⋆Delta W^starΔW⋆ 做 SVD:
ΔW⋆≈UrΣrVr⊤
Delta W^star approx U_r Sigma_r V_r^top
ΔW⋆≈UrΣrVr⊤
那你会发现它天生就可以写成 LoRA 形式:
ΔW⋆≈(UrΣr)(Vr⊤)
Delta W^star approx (U_rSigma_r)(V_r^top)
ΔW⋆≈(UrΣr)(Vr⊤)
令:
B=UrΣr,A=Vr⊤
B = U_rSigma_r,qquad A = V_r^top
B=UrΣr,A=Vr⊤
就得到 ΔW≈BADelta W approx BAΔW≈BA,并且 rank(ΔW)≤rmathrm{rank}(Delta W)le rrank(ΔW)≤r。
这里有一个非常关键但容易被忽略的点:
- SVD 截断是在“给定矩阵后求最佳秩 rrr 逼近”
-
LoRA是在“训练时把更新空间限制在秩 rrr 的集合里”
也就是说,LoRA 不需要你真的去算 SVD,它只是利用了“低秩结构常常够用”的事实,把这个结构当作可控的归纳偏置塞进训练过程里。
因此 lora_rank(rrr)在直觉上就是:
我愿意给“更新空间”多少个主方向?
当 rrr 太小,口径变化装不下;当 rrr 太大,参数与不稳定性上来,甚至更接近全量微调。
6.5 lora_rank、lora_alpha、lora_target 分别在控制什么
把前面第 2 章(秩/SVD)和第 5 章(FFN 造交叉特征)连起来后,这几个超参就很好解释了:
-
lora_rank(rrr)- 控制低秩更新的秩上限:rank(ΔW)≤rmathrm{rank}(Delta W)le rrank(ΔW)≤r
- 更像“改动预算”的维度数:允许沿多少个主方向去改模型
-
lora_alpha(αalphaα)- 控制旁路更新的有效幅度(常见是 α/ralpha/rα/r 的缩放)
- 更像“这条旁路的增益旋钮”,影响适配强度
-
lora_target- 控制把
LoRA插到哪些线性层上,也就是你想改“哪一类行为”
- 控制把
结合前面高考志愿的叙事,你可以用一个很工程化的对照来理解 lora_target:
- 插在注意力投影(
Q/K/V/O)上:更像在改“检索偏好/检索视角”,例如你更愿意参考哪类案例、哪类依据 - 插在
FFN(up/down或gate/up/down)上:更像在改“如何把依据组合成结论”,例如你更看重哪类交叉关系
实践里常见做法是两者都插,但如果你希望训练更稳、可解释性更强,可以先从一个侧重点开始,再逐步扩大 target 范围。
6.6 原论文图
下面这张图直接来自 LoRA 原论文。它最直观地说明了:LoRA 不是改写整层权重,而是在冻结原权重的同时,加上一条低秩旁路。
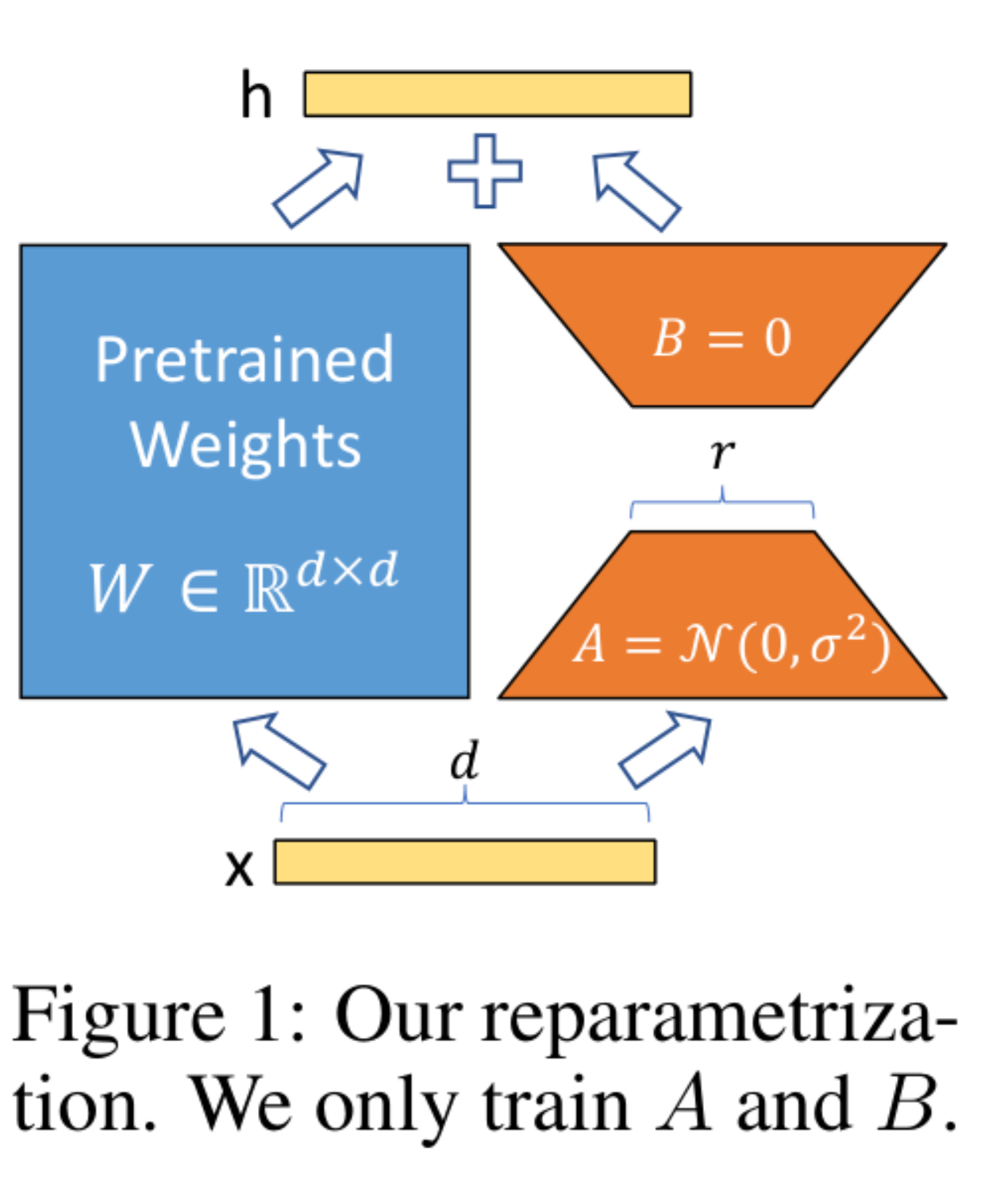
6.7 LoRA 低秩旁路图
6.8 本章小结
这一章把 LoRA 的低秩约束和前面的 SVD/FFN 主线串起来了:
- 全量微调的问题不只是显存,而是可维护性、可控性与多口径切换成本
-
LoRA用 ΔW=BADelta W=BAΔW=BA 把更新限制在低秩集合里:rank(ΔW)≤rmathrm{rank}(Delta W)le rrank(ΔW)≤r - 用第 2 章的 SVD 直觉理解:很多有效更新可以由少数主方向逼近,rrr 就是你愿意放行的“更新自由度”
- 和第 5 章对照:dffd_{ff}dff 是“造交叉特征的预算”,rrr 是“改变模型行为的预算”
下一章我们会继续看结构层面的延伸:为什么 LLaMA 的门控 FFN 和头结构会让“升维/降维”在工程上更显眼。
第 7 章 LLaMA 为什么让“升维/降维”更显眼
这一章把视角从“标准 Transformer”延伸到
LLaMA系列,解释它在几乎不改大框架的前提下,是怎么重排维度与计算预算的。
7.1 gate_proj / up_proj / down_proj 本质上还是 FFN
先把第 5 章和这一章的分工说清楚:
- 第 5 章讲的是:为什么
FFN需要“升维 -> 非线性 -> 降维” - 第 7 章讲的是:
LLaMA怎样把这件事做得更显式、更大、更讲究预算
所以看到 gate_proj / up_proj / down_proj 时,不要被名字吓住。它们并不是一种全新的魔法结构,本质上还是第 5 章那类“在表征空间里先展开、再组合、再压回去”的 FFN。
只不过 LLaMA 把标准两层 FFN
FFN(x)=W2σ(W1x+b1)+b2
text{FFN}(x)=W_2sigma(W_1x+b_1)+b_2
FFN(x)=W2σ(W1x+b1)+b2
改写成了更强的门控形式。于是你在代码里不再只看到“一个升维矩阵 + 一个降维矩阵”,而会看到:
-
up_proj:负责生成候选特征 -
gate_proj:负责生成门控信号 -
down_proj:把门控后的结果压回主干空间
这就是为什么 LLaMA 看起来“到处都是 proj”。不是因为它比 Transformer 多了完全不同的数学对象,而是因为它把内部结构拆得更明确了。
7.2 SwiGLU 的公式与维度形状
LLaMA 常见的门控 FFN 写法可以记成:
FFN(x)=Wdown(σ(Wgatex)⊙(Wupx))
text{FFN}(x)=W_{text{down}}Big(sigma(W_{text{gate}}x)odot (W_{text{up}}x)Big)
FFN(x)=Wdown(σ(Wgatex)⊙(Wupx))
其中常见形状是:
Wgate∈Rdff×dmodel,Wup∈Rdff×dmodel,Wdown∈Rdmodel×dff
W_{text{gate}} in mathbb{R}^{d_{ff}times d_{model}},quad
W_{text{up}} in mathbb{R}^{d_{ff}times d_{model}},quad
W_{text{down}} in mathbb{R}^{d_{model}times d_{ff}}
Wgate∈Rdff×dmodel,Wup∈Rdff×dmodel,Wdown∈Rdmodel×dff
把计算拆开看更容易理解:
g=Wgatex,u=Wupx
g = W_{text{gate}}x,qquad
u = W_{text{up}}x
g=Wgatex,u=Wupx
h~=σ(g)⊙u
tilde h = sigma(g)odot u
h~=σ(g)⊙u
y=Wdownh~
y = W_{text{down}}tilde h
y=Wdownh~
这里最值得注意的是:LLaMA 不是只做一次升维,而是做了两条并行的升维分支。
- 一条分支生成候选特征 uuu
- 一条分支生成门控信号 σ(g)sigma(g)σ(g)
- 两者逐元素相乘,再决定哪些特征被放大、哪些被压制
所以它比普通 FFN 多出来的,不只是“多一个矩阵”,而是多了一层更细的结构控制:
标准
FFN更像“先做出一堆特征,再整体映射回来”;SwiGLU更像“先做出一堆候选特征,再用另一条支路决定哪些特征该被放行”。
如果你回到高考志愿建议的类比,它就像:
-
up_proj:把你脑子里所有可能相关的因素都摊开 -
gate_proj:根据当前问题,判断这些因素哪些该重、哪些该轻 -
down_proj:把筛过之后的结果重新整理成一句简洁的建议
这也是为什么 LLaMA 的 FFN 在实践里往往更强:它不是只靠“更宽”,而是在“更宽”的同时引入了更细的门控。
7.3 GQA:投影矩阵的“头数结构”变了,但维度逻辑没变
除了 FFN,LLaMA 里另一个很值得讲清楚的点是 GQA(Grouped-Query Attention)。
先回顾标准多头注意力。假设有 hhh 个头,那么通常:
-
Q有 hhh 个头 -
K有 hhh 个头 -
V也有 hhh 个头
这很好理解,但代价是:推理时每个 token 都要缓存所有头的 K/V,KV cache 会很大。
GQA 的核心思路是:保留较多的查询头,但减少 K/V 头数。
如果设:
- 查询头数为 hqh_qhq
-
KV头数为 hkvh_{kv}hkv - 且 hkv<hqh_{kv} < h_qhkv<hq
那么多个查询头会共享同一组 K/V 头。直觉上,你可以把它理解成:
- 问问题的人还是很多(不同查询视角仍然保留)
- 但资料管理员的人数减少了(更少的
K/V头被共享)
为什么这件事重要?因为它直接影响推理时的计算和内存预算。
如果单头维度是 dheadd_{head}dhead,序列长度是 TTT,那么 KV cache 大小大致与:
T⋅hkv⋅dhead
T cdot h_{kv} cdot d_{head}
T⋅hkv⋅dhead
成正比,而不是和 hqh_qhq 成正比。也就是说:你把 KV 头数降下来,KV cache 就会明显变小。
这就是 GQA 的工程核心:
尽量保留足够多的“提问视角”,同时减少“被缓存的答案索引数量”。
所以 GQA 的本质并不是“改了注意力的数学定义”,而是重分配了头结构里的预算:
- 更多预算留给
Q的多样性 - 更少预算花在
K/V的存储与重复上
这和本文的总主题完全一致:不是一味地增大所有维度,而是把预算放在最值钱的地方。
7.4 RoPE 与 “旋转”不是升降维,但会改变你如何理解 Q/K
RoPE(Rotary Positional Embedding)是这一章里最容易被误读的一点,因为它会让人觉得:“既然也在改向量,那是不是又是一种升维/降维?”
答案是否定的。RoPE 的关键不是改变维度,而是在保持维度不变的前提下,把位置信息以旋转的方式注入到 Q/K 中。
如果把二维子空间里的一对分量写成:
[q2iq2i+1]
begin{bmatrix}
q_{2i}\
q_{2i+1}
end{bmatrix}
[q2iq2i+1]
那么 RoPE 对它做的是一个位置相关的旋转:
R(θp)[q2iq2i+1]
R(theta_p)
begin{bmatrix}
q_{2i}\
q_{2i+1}
end{bmatrix}
R(θp)[q2iq2i+1]
其中:
R(θp)=[cosθp−sinθpsinθpcosθp]
R(theta_p)=
begin{bmatrix}
costheta_p & -sintheta_p\
sintheta_p & costheta_p
end{bmatrix}
R(θp)=[cosθpsinθp−sinθpcosθp]
这里的 θptheta_pθp 与位置 ppp 有关。K 也会做对应的旋转。这样做的效果是:内积 QK⊤QK^topQK⊤ 不再只反映内容相似,还会隐式带上相对位置信息。
所以 RoPE 的作用更像是:
- 不改“空间有多大”
- 而是改“你在这个空间里怎么看方向关系”
这和前面讲的升维/降维不是同一类操作,但它仍然值得放在这一章讲,因为它体现了 LLaMA 的另一种设计哲学:
不一定靠增加更多维度,也可以通过更聪明的结构化变换,让已有维度更有用。
7.5 LLaMA Block 里的维度流

7.6 本章小结
这一章讲的不是一个新的主线,而是对前面主线的“工程化升级版”:
-
SwiGLU说明LLaMA如何把第 5 章的FFN做得更细:两条升维支路 + 一条降维支路 -
GQA说明LLaMA如何在注意力里重新分配预算:尽量保留Q的多样性,压缩KV的缓存成本 -
RoPE说明LLaMA不只是靠“更多维度”取胜,也会通过结构化旋转让已有维度承载更有效的位置信息
如果把这三者和全文主线放在一起看,LLaMA 其实做的是一件很一致的事:
不迷信把所有东西都做大,而是反复问:哪些维度值得保留,哪些预算值得压缩,哪些结构值得拆得更显式。
最后一章我们就回到工程配置:当你在训练 YAML 里看到 d_ff、head 数、KV head 数、lora_rank、lora_target 时,到底是在给哪一类预算拨钱。
第 8 章 工程视角:如何从训练配置读出“升降维”和“低秩”
本章不依赖持续学习背景,只讲通用的
Transformer/LLaMA + LoRA训练配置如何阅读与调参。
8.1 训练配置里你实际上在控制什么
前面 1 到 7 章讲了很多抽象概念:升维、降维、秩、SVD、FFN、LoRA、GQA、RoPE。真正到工程里,读者最容易问的是:
那我打开一份训练配置,看到
d_ff、head 数、KV head 数、lora_rank、lora_target,我到底是在改什么?
最有用的读法,不是把这些参数当成零散超参,而是把它们放进三类预算里:
-
维度预算
- 决定表征空间有多宽、
FFN有多宽、每个头有多少容量 - 典型参数:dmodeld_{model}dmodel、dffd_{ff}dff、head 数、dheadd_{head}dhead
- 决定表征空间有多宽、
-
计算/缓存预算
- 决定推理和训练时你要为注意力与上下文付出多少算力、显存、KV cache
- 典型参数:seq length、head 数、KV head 数(
GQA)、batch size
-
更新预算
- 决定你允许模型沿多少方向改变行为、改哪些位置、改得多大
- 典型参数:
lora_rank (r)、lora_alpha、lora_dropout、lora_target
如果用一句话把这三类预算压缩起来,就是:
训练配置本质上是在回答三件事:表征空间给多少钱,推理/训练成本给多少钱,参数更新又给多少钱。
把这个框架套回前文会非常顺:
- 第 5 章的
FFN:主要在动维度预算 - 第 6 章的
LoRA:主要在动更新预算 - 第 7 章的
GQA:主要在动计算/缓存预算
这样你以后看配置,就不容易把“维度大一点”和“rank 大一点”混成同一类改动。
8.2 lora_target: all 命中了哪些模块
仓库实现中,all 会覆盖:
q_projk_projv_projo_projgate_projup_projdown_proj
如果我们把这些模块按“它们在前文里承担什么角色”来重新分类,会更容易理解:
-
注意力投影链路
q_projk_projv_projo_proj
这一组更偏向“检索系统”:
-
q_proj决定怎么提问 -
k_proj决定怎么建立索引 -
v_proj决定取回什么内容 -
o_proj决定多头结果怎么汇总回主空间
如果你在这组层上挂 LoRA,本质上是在给“检索偏好和检索视角”开更新旁路。用高考志愿的类比,就是:你在改“更愿意参考哪类案例、如何理解相关性、如何汇总依据”。
-
FFN/ 组合链路gate_projup_projdown_proj
这一组更偏向“组合系统”:
-
up_proj/gate_proj决定候选特征怎么被展开和门控 -
down_proj决定这些特征怎么被压回主干表示
如果你在这组层上挂 LoRA,更像是在改“拿到依据之后,如何组织成结论”,也就是在改第 5 章讲的“自动造交叉特征”的偏好。
所以 lora_target: all 的真正含义不是“到处都加一遍 LoRA 就完事”,而是:
同时给“检索机制”和“组合机制”都留一条可训练旁路。
这通常会带来更强的适配能力,但也意味着:
- 可训练参数更多
- 训练更重
- 不同模块之间的变化更容易互相耦合
如果你希望更稳、更好解释,完全可以从更小的 target 开始。
8.3 一个统一阅读框架
现在我们把前面所有概念压缩成一个真正可用的“读配置顺序”。
第一步:先看模型结构
先问自己:这是标准 Transformer,还是 LLaMA 一类变体?
- 有没有门控
FFN(gate_proj/up_proj/down_proj) - 有没有
GQA - 有没有
RoPE
这一步决定的是:你面对的是一套什么样的“默认预算分配方案”。
第二步:看维度预算
重点看:
- dmodeld_{model}dmodel
- dffd_{ff}dff
- head 数
- dheadd_{head}dhead(如果配置里显式出现)
- KV head 数(如果用了
GQA)
这一步本质上在回答:
- 模型内部的表示空间有多宽
-
FFN有多少“造交叉特征预算” - 注意力头有多少“分工空间”
如果你把这些数全拉大,通常表达能力会上升,但算力、显存、推理成本也会一起上升。
第三步:看计算与缓存预算
很多时候真正把训练/推理卡死的,不是参数量本身,而是上下文和 KV cache。
重点看:
- seq length
- batch size
- 是否使用
GQA - KV head 数
你可以把这一步理解成:同样一个模型结构,在“上下文有多长、KV 要缓存多少、每步要算多少”上,成本可能差很多。
例如在 GQA 下,KV cache 大小近似跟:
T⋅hkv⋅dhead
T cdot h_{kv} cdot d_{head}
T⋅hkv⋅dhead
成正比。也就是说,很多时候减小 KV 头数,比盲目改别的超参更直接地省预算。
第四步:看更新预算
最后再看 LoRA:
lora_ranklora_alphalora_dropoutlora_target
这一步本质上回答的是:
- 你允许模型沿多少主方向改变?
- 你允许这些变化出现在哪些模块?
- 你允许它改得多激进?
这一步和前面的“维度预算”很容易混,但其实完全不是一回事:
-
d_ff变大:前向能力更强,能造更多交叉特征 -
lora_rank变大:适配自由度更强,能沿更多方向改行为
一个更偏“能力容量”,一个更偏“更新容量”。
第五步:最后再综合任务目标做判断
真正调参时,不是所有预算都同时加。更合理的判断顺序通常是:
- 先明确任务主要瓶颈是“表达不够”,还是“检索不准”,还是“适配不够”
- 如果是表达不够,优先看维度预算(尤其
d_ff、head 结构) - 如果是上下文/推理成本不稳,优先看计算与缓存预算(seq、KV head、
GQA) - 如果是口径切换/领域适配,优先看更新预算(
LoRA的 rank/target)
这样调参时,你就不是在“蒙着眼睛改数字”,而是在明确地给某一种预算加钱或省钱。
8.4 本章小结
这一章真正想做的,是把全文前面的抽象概念都翻译成配置语言。
最后可以把它收成一张非常简洁的对照表:
-
d_model / d_ff / head 数:你在买表征能力 -
KV head / seq length / batch:你在买算力与缓存能力 -
lora_rank / lora_alpha / lora_target:你在买适配自由度
如果你把这三类预算分清了,再回头看本文前面的内容,就会发现整篇文章其实一直在讲同一件事:
模型训练里那些看起来零散的“升维、降维、投影、低秩”,本质上都是在重新分配预算。
它们分配的对象不同:
- 有的是表征空间预算
- 有的是计算与缓存预算
- 有的是更新自由度预算
但它们回答的始终是同一个问题:
哪些方向值得展开,哪些方向应该压缩,哪些位置需要被重点改动?
把这条线拎清,你以后再看一份训练配置,就不只是“看超参数表”,而是在看一份关于能力、成本和适配性的预算书。
结语
最后用一个判断标准收束全文:名字里都叫 projection,不代表它们在做同一种事情。真正要看的,是它作用在哪个空间、限制了什么自由度、优化了什么矛盾。
等把这条线拎清,你再看 Transformer、LoRA 和 LLaMA 的训练代码,很多看似分散的设计就会突然串起来。
© 版权声明
文章版权归作者所有,未经允许请勿转载。