
OpenSpec 实测,五步搞定 AI 编程,需求不跑偏、修改有记录
作为一名长期和代码打交道的程序员,相信很多人都有过这样的困扰:用 AI 编程时,明明说清楚了需求,AI 却总能写出“跑偏”的代码;多次修改后,忘了最初的需求逻辑,也没有完整的修改记录,后续维护起来一团乱麻;迭代现有项目时,AI 对已有代码的改动毫无章法,甚至破坏原有逻辑。直到我接触到 OpenSpec,才发现这些问题都能迎刃而解。
今天就给大家带来 OpenSpec 的详细实测,从它是什么、能做什么,到具体怎么用,再到实战案例拆解和使用建议,全程干货无废话,帮你彻底搞懂如何用这个工具让 AI 编程变“听话”,让每一次开发都规范、可控、可追溯。
先跟大家交个底,OpenSpec 不是什么复杂的大型平台,也不是能替代 Cursor、Copilot 这些常用 AI 编程工具的新神器,它本质上是一个轻量级命令行工具,再加上一套标准化的协作流程。核心逻辑特别简单,就一句话:先定规矩,再写代码。看似简单的一句话,却能解决 AI 编程中最核心的痛点,需求模糊、改动无序、无据可查。
一、先搞懂:OpenSpec 到底是什么?给 AI 配张“需求图纸”
很多人刚听到 OpenSpec 这个名字,可能会觉得它是一个编程框架或者 AI 插件,其实不然。如果用一个通俗的比喻,它更像是“AI 编程的项目经理”,不负责具体的编码工作,却能帮你和 AI 之间建立起清晰的“施工契约”,让 AI 严格按照你的需求来输出代码,不跑偏、不越界。
这里要特别澄清一个误区:OpenSpec 不是来替代你常用的 AI 编程工具的。不管你平时用 Cursor、Claude Code,还是 Copilot,都可以搭配 OpenSpec 使用。它的核心作用有两个,相当于给这些 AI 工具配了两个“辅助装备”。
第一个是“需求翻译器”。我们平时跟 AI 提需求,大多是口语化的描述,比如“帮我加一个 Word 转 Markdown 的功能”,这种描述太模糊,AI 很容易误解,比如不清楚支持哪些 Word 格式、遇到图片该怎么处理、转换后的 Markdown 样式有什么要求。而 OpenSpec 会帮你把这些模糊的口语化需求,转化为结构化、标准化的需求说明,让 AI 一眼就能看懂,避免理解偏差。
第二个是“进度跟踪器”。AI 编程的一大问题就是改动无记录,比如你让 AI 修改一段代码,改了三次后,想回到第一次的版本,却发现没有任何记录;或者项目迭代时,想知道某个功能是怎么一步步实现的,为什么要这么改,都无从查证。而 OpenSpec 会记录下每一次功能改动的全过程,从需求提案到设计决策,再到任务执行和归档,每一步都有迹可循,让项目演进过程清晰可见。
另外要强调的是,OpenSpec 尤其适合迭代现有项目,也就是从 1 到 N 的开发场景。对于已有代码的项目,它能帮你对代码进行可控的增强和重构,避免 AI 乱改代码导致的 bug;而如果是从零开始的新项目(从 0 到 1),它的作用相对没那么突出,毕竟新项目初期需求变化快,过于规范反而可能限制效率。
二、核心能力:OpenSpec 能帮我们解决什么问题?
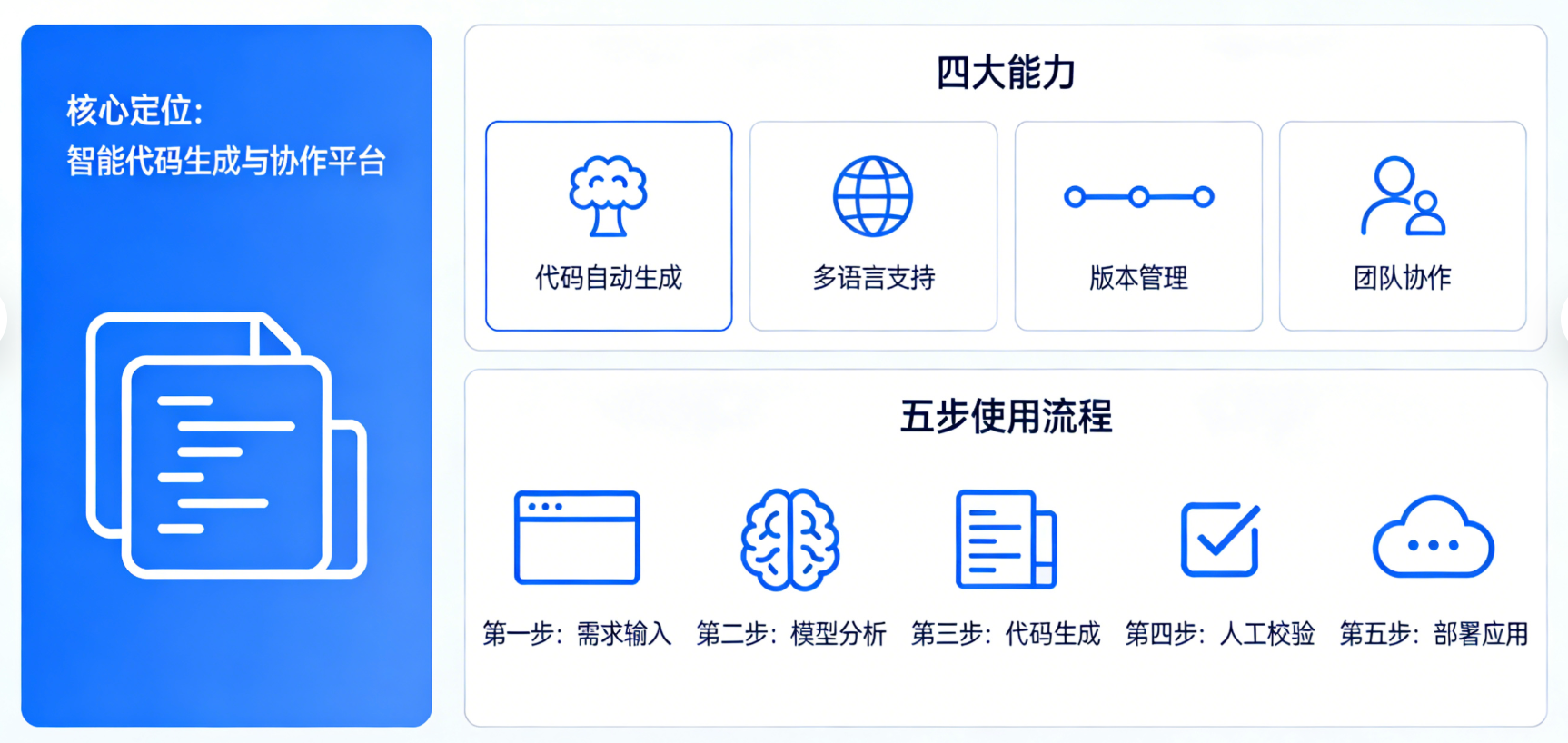
了解了 OpenSpec 的定位,接下来我们看看它具体能做什么。总结下来,它有四大核心能力,每一个都切中 AI 编程的痛点,而且上手简单、兼容性强,不用花费大量时间学习。
1. 极简上手:不用复杂配置,npm 一键安装
对于程序员来说,最烦的就是那些需要复杂配置才能使用的工具,而 OpenSpec 完全没有这个问题。它是一个命令行工具,只要你的电脑上安装了 Node.js,执行一句 npm install,再输入几条简单的命令,就能快速上手使用,全程不超过5分钟,哪怕是对命令行不熟悉的新手,也能轻松操作。
而且它不需要单独安装客户端,也不需要配置复杂的环境变量,安装完成后,直接在项目目录中执行相关命令,就能和你常用的 AI 编程工具联动,大大降低了使用门槛。
2. 无缝兼容:主流 AI 编程工具都能搭
很多工具看似好用,但兼容性差,只能搭配特定的软件使用,这就很限制场景。而 OpenSpec 几乎兼容所有主流的 AI 编程工具,比如 Cursor、Claude Code、Copilot 等,不需要你更换常用的工具,也不需要做额外的集成配置,直接把 OpenSpec 的命令集成到这些工具的聊天框里,就能实现联动。
比如你平时用 Claude Code 写代码,只要在 Claude Code 的聊天框里输入 OpenSpec 的相关命令,就能让 Claude Code 按照 OpenSpec 的规范来生成代码、处理需求,完全不影响你的使用习惯,做到“无缝衔接”。
3. 全程留痕:每一次改动,都有四份“档案”保驾护航
这是 OpenSpec 最核心的功能,也是解决 AI 编程无据可查的关键。每次你用 OpenSpec 进行功能改动,它都会自动生成四份结构化的“档案”,涵盖从需求到实现的全过程,让每一次改动都有章可循、有据可查。
第一份是提案文档,核心回答两个问题:为什么要做这个改动?具体要做什么?比如你想给项目加一个 Word 转 Markdown 的功能,提案文档就会明确记录下这个功能的需求背景、核心目标、具体范围,避免后续出现“忘了为什么要做这个功能”的情况。
第二份是设计决策文档,记录的是“为什么用这个方案实现”。比如实现 Word 转 Markdown 功能,有多种技术方案,你选择了其中一种,设计决策文档就会详细说明选择这个方案的原因,比如兼容性更好、效率更高、更贴合项目现有技术栈等,后续如果有人质疑方案的合理性,或者需要优化方案,这份文档就能提供参考。
第三份是任务清单,把具体的实现步骤拆解开,明确每一步要做什么。比如实现 Word 转 Markdown 功能,会拆分成“处理 Word 文档读取”“处理图片转换”“处理文本格式转换”“测试功能兼容性”等具体任务,AI 会严格按照这个任务清单来编码,避免出现遗漏或跑偏的情况。
第四份是规范更新文档,记录项目规范的变化。比如新增了 Word 转 Markdown 的功能,可能会涉及到新的数据结构、新的接口规范,这份文档就会把这些新增的规范记录下来,确保项目规范和代码实时同步,后续开发人员(包括你自己)在维护或迭代时,能快速了解项目的最新规范。
4. 变更可溯:项目演进过程,一目了然
除了每次改动生成的四份档案,OpenSpec 还会把所有的历史提案、讨论记录、实现过程都沉淀下来,形成一个完整的项目演进记录。不管是几个月后,你想回顾某个功能的开发过程,还是新加入项目的开发人员,想快速了解项目的迭代历史,只要查看 OpenSpec 沉淀的记录,就能一目了然。
这种变更可溯的能力,不仅能方便后续的维护和迭代,还能在出现问题时,快速定位问题根源。比如某个功能出现 bug,你可以通过 OpenSpec 的记录,查看这个功能的提案、设计决策、实现步骤,快速找到问题出在哪个环节,大大提高问题排查的效率。
三、实测教程:五步走,像管理项目一样管理 AI 编程
了解了 OpenSpec 的核心能力,接下来就是最实用的实测教程。很多人觉得“规范”就意味着“繁琐”,但 OpenSpec 的五步流程,不仅不繁琐,还能帮你节省时间,避免因为需求跑偏而反复修改代码。
下面我们就以“给现有项目添加 Word 转 Markdown 功能”为例,一步步教大家如何使用 OpenSpec,全程实测,每一步都有详细的操作说明,大家可以跟着一步步操作,快速掌握使用方法。
第一步:起草提案——先定需求,再写代码(最关键的一步)
很多人用 AI 编程时,习惯一上来就让 AI 写代码,结果就是需求模糊,AI 写出来的代码不符合预期,反复修改,反而浪费时间。而 OpenSpec 的第一步,就是让你先“定规矩”,起草一份完整的需求提案,一行代码都不写。
操作很简单:进入你的项目目录,打开你常用的 AI 编程工具(比如 Claude Code),在聊天框里输入命令:/openspec:proposal 添加Word转Markdown功能。
输入命令后,AI 不会直接写代码,反而会反过来问你一系列关键细节,比如:支持哪些 Word 格式(.doc、.docx 还是两者都支持)?遇到 Word 中的图片,是忽略还是转换为 Markdown 中的图片链接?转换后的 Markdown 文本,是否需要保留原有的标题层级、列表格式?是否需要支持批量转换?
这些问题,其实都是你平时可能忽略的细节,也是 AI 容易跑偏的地方。你只需要逐一回答这些问题,AI 就会根据你的回答,生成一份结构化的“需求说明书”和任务清单,这份说明书就是你和 AI 之间的“施工契约”,后续所有的编码工作,都要围绕这份说明书来进行。
这里要提醒大家,提案阶段一定要耐心,AI 追问的每一个细节,都可能是你未来开发中会踩的坑。比如你如果忽略了“图片处理”这个细节,AI 可能会直接忽略图片,导致转换后的 Markdown 文档缺失图片,后续还要重新修改,反而浪费时间。
第二步:审查对齐——和 AI 一起“找茬”,降低修改成本
起草完提案后,不要着急让 AI 编码,第二步是“审查对齐”,你和 AI 一起评审这份“需求说明书”,确认需求是否完整、技术方案是否靠谱。这一步是重点,也是最能节省时间的一步,因为此时还没有写一行代码,修改需求的成本几乎为零。
审查的重点的有三个:一是需求是否完整,有没有遗漏的细节,比如是否支持批量转换、是否需要处理特殊格式(如表格、公式);二是技术方案是否合理,比如选择的转换工具是否贴合项目现有技术栈、是否存在性能问题;三是任务清单是否清晰,每一步的执行逻辑是否顺畅,有没有遗漏的执行步骤。
如果发现问题,直接在 AI 聊天框里提出修改意见,AI 会快速修改提案文档和任务清单,直到你确认无误。比如你发现提案中没有提到“表格转换”,就可以告诉 AI“需要支持 Word 中表格转换为 Markdown 表格”,AI 会立即更新提案和任务清单,补充相关细节。
这一步就相当于你和 AI 进行了一次“需求确认会”,把所有可能出现的问题都提前解决,避免后续写代码后再修改,大大降低修改成本。
第三步:实施编码——AI 按清单执行,不跑偏、不遗漏
当你和 AI 确认提案无误后,就可以进入第三步:实施编码。这一步很简单,只需要在 AI 聊天框里执行命令:/openspec:apply,AI 就会严格按照提案中的任务清单,一步步进行编码,不会偏离需求,也不会遗漏任何一个步骤。
比如任务清单中拆分成了“处理 Word 文档读取”“处理图片转换”“处理文本格式转换”“测试功能兼容性”四个步骤,AI 就会先完成“处理 Word 文档读取”,再进行下一步,每完成一步,都会向你反馈进度,让你随时了解编码情况。
这里要说明的是,编码的主体还是 AI 编程工具(比如 Claude Code、Cursor),OpenSpec 只是起到“监督”和“引导”的作用,确保 AI 按照需求和任务清单来编码,避免出现“随心所欲”写代码的情况。而且在编码过程中,如果你发现某个步骤有问题,还可以随时暂停,修改提案后再继续执行。
第四步:归档更新——沉淀交付记录,方便后续追溯
当 AI 完成编码,并且功能测试通过后,就进入第四步:归档更新。执行命令:/openspec:archive,OpenSpec 就会把这次改动的所有“档案”(提案文档、设计决策文档、任务清单、规范更新文档)自动合并到主项目文档里,形成一次干净、完整的交付记录。
归档完成后,你可以在项目目录中找到这些归档文件,后续不管是需要回顾这次改动的细节,还是需要排查问题,都可以快速找到相关记录。同时,OpenSpec 还会更新项目的“活文档”(后续会详细说明),确保项目规范和代码实时同步。
这一步看似简单,但却非常重要。很多项目之所以维护困难,就是因为没有完整的交付记录,后续开发人员不知道之前的功能是怎么实现的,为什么要这么改,只能一点点摸索,浪费大量时间。而 OpenSpec 的归档功能,就能完美解决这个问题。
第五步:规范演进——打造项目“活文档”,成为长期导航图
第五步不是一次性的操作,而是一个持续的过程。随着一次次的“提案-审查-实施-归档”,你的项目会拥有一份和代码实时同步的“活文档”。这份“活文档”包含了项目的所有需求、设计决策、规范要求、迭代记录,是项目最权威的“宪法”。
这份“活文档”最大的价值,就是它会随着项目的迭代而持续生长。比如你后续又给项目添加了“批量转换”“格式自定义”等功能,每一次改动都会更新到“活文档”中,让“活文档”始终保持和代码一致。不管是你自己后续维护项目,还是新加入的开发人员快速熟悉项目,这份“活文档”都是最实用的导航图。
而且这份“活文档”还能帮你规避“规范混乱”的问题。很多项目在迭代过程中,因为没有统一的规范,不同的开发人员(包括 AI)写的代码风格不一、逻辑混乱,后续维护起来非常困难。而 OpenSpec 会通过“规范更新文档”,不断完善项目规范,让所有的代码都遵循统一的标准,让项目更加规范、易维护。
四、实战案例深度解析:从零开始用 OpenSpec 实现 Word 转 Markdown 功能
上面的五步教程,大家可能还有些抽象,下面我们就带来一个完整的实战案例,从项目初始化到功能归档,一步步拆解,让大家更直观地了解 OpenSpec 的使用过程。本次实战我们使用 Claude Code 作为 AI 编程工具,项目名称为 wd2md,核心功能是实现 Word 转 Markdown 转换。
1. 准备工作:进入项目目录,确认环境
首先,打开终端,进入你的项目目录(如果没有现成的项目,可以新建一个名为 wd2md 的目录),执行以下命令,确认 Node.js 环境已安装(OpenSpec 依赖 Node.js):
node -v
如果能正常显示 Node.js 的版本号,说明环境没问题。如果没有安装 Node.js,需要先安装 Node.js(建议安装 16.0 及以上版本),安装完成后再进行后续操作。
2. 项目初始化:执行 OpenSpec 初始化命令
在项目目录中,执行以下 OpenSpec 初始化命令:
openspec init
执行命令后,系统会提示你选择原生支持的 AI 工具,比如 Claude Code、Cursor、Copilot 等,本次实战我们选择 Claude Code。选择完成后,项目目录会发生一系列变化,主要有以下几点:
第一,在项目根目录中,会生成一个 Claude.md 文件,文件中会增加一段 OpenSpec 说明,内容和根目录中的 AGENTS.md 文件一致,主要是给 AI 助手看的 OpenSpec 使用说明,告诉 AI 什么时候需要参考 OpenSpec 规范,如何使用 OpenSpec 进行协作。
这段说明的核心内容如下(简化版):
<!-- OPENSPEC:START -->
# OpenSpec Instructions
These instructions are for AI assistants working in this project.
Always open `@/openspec/AGENTS.md` when the request:
- Mentions planning or proposals (words like proposal, spec, change, plan)
- Introduces new capabilities, breaking changes, architecture shifts, or big performance/security work
- Sounds ambiguous and you need the authoritative spec before coding
Use `@/openspec/AGENTS.md` to learn:
- How to create and apply change proposals
- Spec format and conventions
- Project structure and guidelines
Keep this managed block so 'openspec update' can refresh the instructions.
<!-- OPENSPEC:END -->
这段说明的作用,就是让 Claude Code 知道,当遇到需求提案、功能变更、模糊需求时,要参考 OpenSpec 的规范,按照 OpenSpec 的流程来协作。
第二,在项目目录中,会生成一个 .claude 文件夹,文件夹下包含 commands/openspec 目录,里面有三个文件:apply.md、archive.md、proposal.md。这三个文件主要是 OpenSpec 相关命令的 prompt 说明,告诉 AI 执行 /openspec:apply、/openspec:archive、/openspec:proposal 这三个命令时,应该做什么、怎么做。
第三,在项目根目录中,会生成 AGENTS.md 文件和 openspec 目录。其中,AGENTS.md 文件是 OpenSpec 的核心配置文件,包含了 OpenSpec 的工作流程、规范要求等内容;openspec 目录是后续我们主要用来生成需求、记录协作过程的目录,里面会包含项目文档、变更记录、规范文件等。
初始化完成后,项目目录结构如下(简化版):
wd2md/
├── .claude/
│ └── commands/
│ └── openspec/
│ ├── apply.md
│ ├── archive.md
│ └── proposal.md
├── AGENTS.md
└── openspec/
├── AGENTS.md
├── changes/
│ └── archive
├── project.md
└── specs
3. 完善项目文档:填写 project.md,明确项目上下文
初始化完成后,我们需要先完善 openspec 目录下的 project.md 文件。这份文件是项目的核心文档,主要记录项目的基本信息、技术栈、约定规范等内容,AI 会根据这份文件来了解项目上下文,避免写出不符合项目规范的代码。
操作方法很简单:打开 Claude Code,在聊天框里输入以下提示:请阅读 openspec/project.md 并帮助我填写项目详情、技术栈和约定规范。
输入提示后,AI 会先读取 project.md 文件的默认内容,然后反过来问你相关信息,比如:项目的名称、核心功能、目标用户、使用的技术栈(如 Node.js、Express、React 等)、代码规范(如命名规范、缩进规范等)、项目结构约定等。
你只需要逐一回答这些问题,AI 就会自动更新 project.md 文件,填写完整的项目信息。比如本次实战,我们的项目名称是 wd2md,核心功能是 Word 转 Markdown 转换,技术栈是 Node.js + Express,代码规范遵循 Airbnb JavaScript 规范,项目结构采用 MVC 模式,AI 就会按照这些信息,完善 project.md 文件。
如果是老项目,已经有一定的代码和项目结构,也可以用同样的方法,让 AI 帮你完善 project.md 文件,确保 AI 能准确了解项目上下文,避免后续编码出现偏差。
4. 生成功能变更提案:明确需求,生成任务清单
完善 project.md 文件后,我们就可以生成第一个功能变更提案了。在 Claude Code 的聊天框里,输入以下命令,清晰描述需求:
/openspec:proposal 添加 word转markdown的能力,支持.doc和.docx格式,遇到图片时,将图片转换为Markdown中的图片链接并保存到项目的images文件夹中,保留原有的标题层级、列表格式和表格格式,支持单个文件转换,后续可扩展批量转换功能。
输入命令后,AI 会根据我们的需求,追问一些细节(如果有遗漏的话),比如:图片链接的路径格式是什么、表格转换后是否需要保留边框样式、转换后的 Markdown 文件保存到哪个目录等。我们逐一回答这些问题后,AI 就会生成一份完整的变更提案,包含提案文档、设计决策文档、任务清单和规范更新文档。
此时,openspec 目录下的 changes 文件夹会新增一个 add-word-to-markdown 目录,里面包含以下文件:
add-word-to-markdown/
├── design.md (设计决策文档)
├── proposal.md (提案文档)
├── specs (规范文件目录)
│ ├── document-converter/
│ │ └── spec.md
│ └── word-to-markdown/
│ └── spec.md
└── tasks.md (任务清单)
我们可以打开这些文件,检查需求是否完整、设计决策是否合理、任务清单是否清晰。如果发现问题,直接在 Claude Code 中提出修改意见,AI 会快速修改相关文件,直到我们确认无误。
5. 代码开发执行:AI 按清单编码,全程可控
确认提案无误后,我们就可以让 AI 开始编码了。在 Claude Code 的聊天框里,输入命令:/openspec:apply,AI 就会严格按照 tasks.md 中的任务清单,一步步进行编码。
本次实战的任务清单大致如下(简化版):
1. 安装依赖包:安装 docx-pdf-converter、markdown-it 等相关依赖,用于 Word 文档读取和 Markdown 转换;
2. 编写 Word 文档读取模块:实现 .doc 和 .docx 格式文件的读取,提取文档中的文本、图片、表格等内容;
3. 编写图片处理模块:将 Word 中的图片提取出来,保存到项目的 images 文件夹中,生成对应的 Markdown 图片链接;
4. 编写格式转换模块:将提取的文本、表格转换为 Markdown 格式,保留原有的标题层级、列表格式和表格样式;
5. 编写主函数:整合各个模块,实现单个 Word 文件转 Markdown 的功能;
6. 编写测试用例:对转换功能进行测试,确保转换后的 Markdown 文档格式正确、图片能正常显示。
AI 会按照这个任务清单,一步步编码,每完成一个任务,都会向我们反馈进度,并展示相关代码。在编码过程中,如果我们发现某个步骤有问题,比如图片保存路径不正确、表格转换格式有误,就可以随时暂停,让 AI 修改,确保代码符合需求。
6. 功能测试与归档:沉淀记录,完成交付
AI 完成编码后,我们需要对功能进行测试,比如上传一个包含文本、图片、表格的 Word 文档,执行转换命令,查看转换后的 Markdown 文档是否符合预期,图片是否能正常显示,格式是否正确。
测试通过后,就可以执行归档命令了。在 Claude Code 的聊天框里,输入命令:/openspec:archive,OpenSpec 会将这次改动的所有档案(proposal.md、design.md、tasks.md、specs 文件夹中的文件)自动合并到 openspec 目录的 archive 文件夹中,形成一次完整的交付记录。
同时,OpenSpec 会更新 project.md 文件和 openspec 目录下的 specs 文件,将本次新增的功能规范、技术细节添加到项目“活文档”中,确保项目规范和代码实时同步。
7. 后续迭代:重复“提案-实施-归档”流程
如果后续我们想给项目添加新的功能,比如批量转换、格式自定义等,只需要重复前面的流程:起草提案、审查对齐、实施编码、归档更新、规范演进。
比如我们想添加“批量处理”功能,只需要在 Claude Code 中输入命令:/openspec:proposal 规划新功能,增加批量处理的能力,支持同时选择多个 Word 文件进行转换,转换后的 Markdown 文件按原文件名保存到指定目录。然后和 AI 审查对齐提案,确认无误后执行 /openspec:apply 编码,测试通过后执行 /openspec:archive 归档即可。
通过这种方式,项目的每一次迭代都规范、可控、可追溯,不管是后续维护还是功能扩展,都能轻松应对。
五、真心建议:这些坑别踩,高效使用 OpenSpec
经过一段时间的实测,我总结了一些使用 OpenSpec 的建议,不管你是新手还是有一定经验的程序员,都可以参考,避免踩坑,让 OpenSpec 发挥最大的作用。
1. 从小功能试起,建立信心
如果你是第一次使用 OpenSpec,不要一开始就用它来处理复杂的功能改动,建议先拿一些简单的小功能试起,比如“改个按钮颜色”“添加一个简单的接口”“优化一段简单的代码”,先把 OpenSpec 的五步流程走通,熟悉它的使用方法,建立信心后,再用它来处理复杂的功能和项目迭代。
这样做的好处是,即使出现问题,也能快速排查和解决,不会因为复杂功能导致挫败感,也能更快地掌握 OpenSpec 的核心用法。
2. 珍惜 AI 的提问,每一个追问都是避坑机会
在起草提案时,AI 会追问很多细节,很多人会觉得麻烦,随便敷衍过去,结果就是后续编码出现问题,反复修改。其实,AI 追问的每一个细节,都是你未来可能踩的坑,也是需求中可能遗漏的点。
比如 AI 问你“遇到图片怎么处理”,如果你随便说“忽略即可”,后续用户使用时发现图片丢失,就需要重新修改代码;而如果你认真思考,明确“将图片转换为图片链接并保存”,就能避免这个问题。所以,一定要珍惜 AI 的提问,认真思考每一个细节,把需求考虑周全。
3. 提案阶段多打磨,修改成本最低
前面我们反复强调,提案阶段是修改需求成本最低的阶段,因为此时还没有写一行代码,修改需求只需要修改提案文档,耗时少、难度低。而一旦进入编码阶段,再修改需求,就需要修改大量的代码,耗时耗力,甚至可能导致整个功能重构。
所以,在提案阶段,一定要多打磨,和 AI 反复审查对齐,确保需求完整、清晰、无歧义,技术方案合理、可行,任务清单清晰、具体。不要急于进入编码阶段,多花一点时间在提案上,后续能节省大量的修改时间。
4. 把规范当核心资产,重视“活文档”的维护
很多程序员觉得“规范不重要”,只要代码能运行就行,这种想法是错误的。对于长期维护的项目来说,规范比代码本身更重要。代码可以重构,但规范一旦混乱,后续维护就会变得非常困难。
OpenSpec 生成的“活文档”,是项目的核心资产,它记录了项目的所有需求、设计决策、规范要求和迭代记录,是项目长期发展的导航图。所以,一定要重视“活文档”的维护,每次迭代后,及时归档更新,确保“活文档”和代码实时同步。后续不管是自己维护项目,还是新加入的开发人员,都能通过“活文档”快速熟悉项目,提高开发效率。
5. 个人项目非必要无需使用,避免过度规范
最后一点建议,也是很重要的一点:如果只是个人项目,非必要无需使用 OpenSpec。因为个人项目通常需求简单、迭代速度快,不需要复杂的规范和记录,过度使用 OpenSpec 反而会增加不必要的操作,降低开发效率。
OpenSpec 更适合团队项目,或者需要长期维护、频繁迭代的项目。在这些项目中,规范和记录非常重要,OpenSpec 能帮团队建立统一的协作流程,避免需求跑偏、改动无序,提高团队开发效率。而个人项目,只要自己能看懂代码、记住需求,就不需要刻意使用 OpenSpec。
六、总结:OpenSpec 让 AI 编程从“开盲盒”变成可靠工程实践
经过详细的实测和实战,我对 OpenSpec 的评价是:它不是一个能提升 AI 编程能力上限的工具,但它能牢牢守住 AI 编程的质量底线,让 AI 编程从“开盲盒”一样的不可控,变成规范、可控、可追溯的可靠工程实践。
它的核心价值,不在于“帮你写代码”,而在于“帮你管理需求、规范流程、记录过程”。通过“先定规矩,再写代码”的核心逻辑,它解决了 AI 编程中最常见的需求跑偏、改动无序、无据可查等痛点,让 AI 成为你的“可靠助手”,而不是“添乱工具”。
对于需要长期维护、频繁迭代的项目,尤其是团队项目,OpenSpec 绝对是一个值得尝试的工具。它上手简单、兼容性强,不需要花费大量时间学习,就能快速融入你的开发流程,帮你提高开发效率、降低维护成本。
最后,给大家附上 OpenSpec 的官方 GitHub 开源地址,感兴趣的朋友可以去下载安装,亲自实测一下,相信你会和我一样,爱上这个能让 AI 编程变“听话”的工具:https://github.com/Fission-AI/OpenSpec/
© 版权声明
文章版权归作者所有,未经允许请勿转载。


