Agent/ChatGPT API 实战:从 0 搭建小龙虾门店运营助手,完成评测与上线全流程
Agent/ChatGPT API 实战:从 0 搭建小龙虾门店运营助手,完成评测与上线全流程
结合 2026-04-25 到 2026-04-26 的 Agent 热点,用最小可复现方案把会聊天的模型做成可评测、可部署、可优化的业务助手
工具资源导航
如果你看完这波热点,想顺手把方案跑起来或者把账号环境补齐,这两个入口可以先收藏:
- API调用:主打各种主流模型接入、稳定转发和低门槛调用。
- GPT代购:官方渠道GPT PLUS/pro充值,秒到账,可开发票
文末资源导航属于工具信息整理,请结合平台规则和自身需求判断。
导语:先看最终效果,再决定要不要往下敲代码
先说最终产出:你会得到一个可复现的最小系统。输入门店库存、昨日销量、客流预估和供应商报价,输出采购建议、促销建议、风险提示;同时配一个最小 benchmark 脚本,帮你判断这个 Agent 到底是真会推理,还是只会一本正经地把预算聊没了。
一个示例输出大致会像这样:
- 采购建议:在预算 1200 元内优先选择单价更低的供应商,并控制采购量
- 促销建议:如果库存偏高,优先做不明显伤毛利的套餐活动
- 风险提示:客流预测偏差、库存积压、预算不足要单独提示
这篇文章不追求“十分钟造 AGI”,而是走 CSDN 读者更关心的路线:场景明确、代码能跑、结果能测、问题能排、上线有边界。
一、热点拆解:这几条新闻放一起看,信号其实很清楚
事实描述
- 2026-04-26,MarkTechPost 讨论了一个非常关键的话题:当 AI Agent 从 demo 走向生产环境时,真正重要的是哪些推理基准,怎么判断它是不是可靠。
- 2026-04-25,TechCrunch 报道 Anthropic 做了一个分类信息市场实验,让买方和卖方都由 AI agent 代表,而且真的完成了交易撮合。
- 2026-04-25,MarkTechPost 介绍了基于 vLLM 的 kvcached,关注动态 KV Cache、突发流量以及多模型共享 GPU 资源。
- 2026-04-26,MarkTechPost 还介绍了 BudouX 在多语言文本智能换行上的做法,重点是 phrase-aware 的文本显示体验。
- 同样是 2026-04-26,Google News AI 聚合里,一边是 AI 需求带动半导体景气,另一边《经济学人》提到旧金山虽然是 AI 之都,但经济表现并不会自动同步起飞。
观点分析
把这些信息拼起来,开发者能看到三个现实:
- Agent 要进入真实业务了,不再只是会议室里演示“它会订机票”。
- 评测比演示更重要,因为业务系统不能靠“看起来挺聪明”过日子。
- 服务层优化和前端体验会补课,算力成本、突发流量、多语言展示,都会变成工程问题。
换句话说,2026 年继续只卷提示词,已经有点像拿螺丝刀参加挖掘机比赛:不是完全没用,但明显不够了。
二、场景定义:为什么我建议先做“小龙虾门店运营助手”
要做副业项目,最怕一上来就做“万能企业智能体”。听起来很大,落地时通常也很大,大到根本动不了。
餐饮场景,尤其是门店运营助手,反而适合做第一个可上线的 Agent:
- 输入变量明确:库存、销量、客流、预算、供应商报价
- 输出结果明确:补货建议、促销建议、风险提示
- 约束条件明确:预算不能超、毛利不能乱写、供应商数据不能编
- 很适合验证模型是否真有推理能力
本文定义的最小目标如下:
- 输入:库存、昨日销量、今日客流预估、预算、供应商价格
- 输出:采购建议、促销建议、风险提示
- 评测:是否遵守预算、是否覆盖关键约束、是否能给出可执行步骤
这也是为什么 2026-04-26 那类“Agentic Reasoning Benchmark”讨论值得关注:业务里你需要的不是“会聊”,而是“遇到约束也不掉线”。
三、技术栈:尽量轻,先把最小闭环跑起来

这里我故意不堆复杂架构,先把最小可复现方案打通。
- Python 3.11
- FastAPI:封装接口
- OpenAI 兼容 SDK 或等价 HTTP 调用:接 ChatGPT/大模型 API
- requests:跑本地评测
- JSON:存测试任务
项目结构:
bash
agent-demo/
app.py
eval.py
tasks.json
安装依赖:
bash
python -m venv .venv
source .venv/bin/activate
pip install fastapi uvicorn openai requests
如果你是 Windows,激活虚拟环境命令自行替换即可,别在这一步和终端互相伤害太久。
四、步骤 1:先做评测集,再谈智能体
这里有个边界先说明白:下面这 7 个维度,是本文为了复现“生产级 Agent 评测思路”而设计的工程化任务,不是对 2026-04-26 那篇文章标题的逐条转述。
建议你至少覆盖这 7 类能力:
- 规划能力
- 约束遵循
- 数据引用完整性
- 成本意识
- 多轮一致性
- 异常恢复
- 输出结构化
先给一个最小 tasks.json:
[
{
“name”: “budget_check”,
“input”: “库存 20 斤,昨日销量 35 斤,今晚预估客流上涨 30%,预算 1200 元,A 供应商 38 元/斤,B 供应商 42 元/斤。请给采购建议。”,
“must_include”: [“预算”, “供应商”, “采购量”, “风险”]
},
{
“name”: “promo_plan”,
“input”: “库存偏高,客流一般,毛利目标不能低于 45%。请给今晚促销方案。”,
“must_include”: [“毛利”, “促销”, “客流”]
}
]
很多 Agent 的问题不是不会回答,而是回答到第三段时把最重要的约束忘了。业务方看完只会说一句:它挺能说,就是不太能负责。
五、步骤 2:接入 ChatGPT/大模型 API,先把服务跑起来
下面这个 app.py 是最小可用版:
python
import os
from fastapi import FastAPI
from pydantic import BaseModel
from openai import OpenAI
client = OpenAI(
api_key=os.getenv(‘LLM_API_KEY’),
base_url=os.getenv(‘LLM_BASE_URL’)
)
app = FastAPI()
SYSTEM_PROMPT = ‘’’
你是餐饮门店运营助手。
输出必须包含:采购建议、促销建议、风险提示。
如果信息不足,要明确指出缺失项,不允许编造供应商数据。
‘’’
class Query(BaseModel):
text: str
model: str = ‘gpt-4o-mini’
@app.post(‘/run’)
def run_agent(q: Query):
resp = client.chat.completions.create(
model=q.model,
temperature=0.2,
messages=[
{‘role’: ‘system’, ‘content’: SYSTEM_PROMPT},
{‘role’: ‘user’, ‘content’: q.text}
]
)
return {‘result’: resp.choices[0].message.content}
启动服务:
bash
export LLM_API_KEY=你的密钥
export LLM_BASE_URL=你的兼容接口地址
uvicorn app:app –reload
测试接口:
bash
curl -X POST ‘http://127.0.0.1:8000/run’
-H ‘Content-Type: application/json’
-d ‘{“text”:“库存 20 斤,昨日销量 35 斤,今晚客流上涨 30%,预算 1200 元,A 38 元/斤,B 42 元/斤,请给建议”}’
这里 temperature=0.2 是一个很实用的参数建议:先追求稳定,再追求花活。餐饮运营助手不是脱口秀演员,没必要每次都 improvise。
六、步骤 3:把感觉不错,改成可以打分
接下来写一个最小评测脚本 eval.py:
python
import json
import requests
def score(output, must_include):
return sum(1 for x in must_include if x in output) / len(must_include)
tasks = json.load(open(‘tasks.json’, ‘r’, encoding=‘utf-8’))
for t in tasks:
r = requests.post(
‘http://127.0.0.1:8000/run’,
json={‘text’: t[‘input’]}
).json()[‘result’]
print(t[‘name’], score(r, t[‘must_include’]))
print®
print(‘-’ * 60)
运行方式:
bash
python eval.py
这当然不是学术 benchmark,但非常适合做版本回归测试。你每次换模型、改提示词、加工具调用,都跑一遍。如果分数下降,就别跟自己说“应该只是风格变化”,生产环境不吃这套。想更严谨一点,可以再补一个 JSON Schema 校验。
七、步骤 4:从单 Agent 走向真实业务闭环
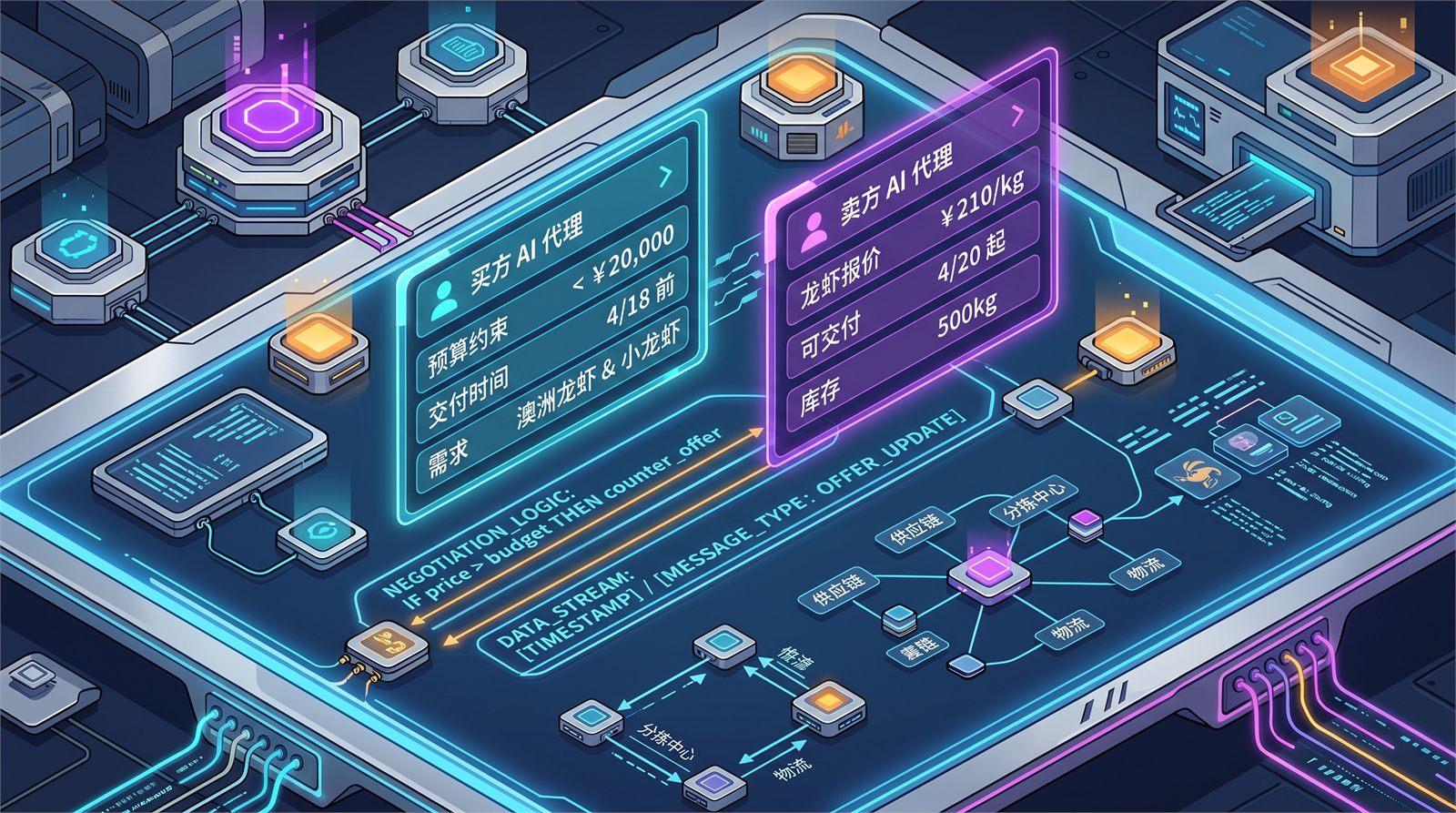
如果你被 2026-04-25 那条 agent-on-agent commerce 新闻启发,完全可以把这个门店助手扩展成两个角色:
- 买方 Agent:代表门店,关注预算、销量预测、库存安全线
- 卖方 Agent:代表供应商,给出价格、交付时间、活动政策
但这里非常重要的一点是:第一版不要全自动下单。更稳的做法是:
- Agent 生成采购候选方案
- Agent 列出风险和理由
- 人工确认后再执行
这样做的好处是,你既能利用智能体提升效率,又不会让系统在凌晨两点帮你“理性采购”出一仓库明天卖不掉的小龙虾。
八、调试排错:最常见的 5 个坑

-
输出不稳定
先降低 temperature,必要时固定输出结构。 -
预算约束经常丢
在系统提示词里明确写“不得忽略预算”,并把预算题放进回归测试。 -
接口一忙就超时
生产里要做超时控制、重试和限流。若后续流量有明显波峰,可以关注 2026-04-25 提到的动态 KV Cache、突发服务优化这类思路。 -
多语言界面显示很丑
如果你的副业项目要做海外市场,2026-04-26 提到的 BudouX 这类文本换行方案值得研究。否则页面断行可能比模型幻觉更先劝退用户。 -
把模型回答当成事实
报价、库存、合同条款、财务数字,都应该以真实数据源为准。模型负责建议,不负责凭空捏造世界。
九、上线建议、成本与合规注意点
1)上线建议
- 先给店长、运营、采购内部使用
- 先做建议系统,不要直接做自动执行系统
- 保留日志,至少记录输入摘要、模型版本、输出结果、人工确认状态
2)成本控制
2026-04-26 的半导体相关新闻提醒了一个现实:AI 需求上来后,算力和推理资源不太可能自己降温。所以副业项目从第一天就要有成本意识:
- prompt 尽量短而结构化
- 高频问题做缓存
- 非实时任务走异步
- 先把业务逻辑理顺,再考虑上更贵的模型
3)合规注意点
- 不要把未脱敏的手机号、支付信息直接塞进 prompt
- 不要让模型编造供应商合同或报价依据
- 涉及交易、报价、采购时,保留人工审核和审计日志
这些听起来不性感,但真的比“我做了一个超级智能体”更接近能长期运行的产品。
十、趋势判断:2026 年开发者真正该盯什么
事实描述
从 2026-04-25 到 2026-04-26,这几条新闻覆盖了 Agent 评测、Agent 交易实验、推理服务优化、前端多语言体验,以及 AI 对基础设施和城市经济的外溢影响。
观点分析
对开发者最直接的启发不是“下一个风口肯定在哪”,而是:
- 应用层机会依然很多,尤其是垂直行业助手
- 但演示式智能体会越来越不够用,必须补上评测体系
- 基础设施成本、服务效率、合规审计,都会前置到产品早期
简单说,接下来真正拉开差距的,不是谁做出一个最会聊天的 Agent,而是谁把评测、服务、业务闭环串起来。旧金山是不是经济领跑,可能很有讨论价值;但你的 Agent 会不会稳定执行门店规则,这件事对项目生死更重要。
结尾总结
如果你想做 AI/ChatGPT/API 方向的副业项目,我更建议你复现一个可测、可改、可上线的小系统,而不是只做一个视频里看起来很神的 demo。
今天这套小龙虾门店运营助手,其实就是一个起点:
- 先定义清楚业务场景
- 再把评测集建起来
- 然后接入模型 API
- 接着跑回归测试
- 最后再考虑多 Agent、推理加速和多语言体验
一句话收尾:先让 Agent 对业务负责,再让它显得聪明。
© 版权声明
文章版权归作者所有,未经允许请勿转载。