
构建现代化实时数据仓库的完整解决方案:从技术选型到企业级实战
构建现代化实时数据仓库的完整解决方案:从技术选型到企业级实战
【免费下载链接】data-warehouse-learning 【2024最新版】 大数据 数据分析 电商系统 实时数仓 离线数仓 建设方案及实战代码,涉及组件 flink、paimon、doris、seatunnel、dolphinscheduler、datart、dinky、hudi、iceberg。  项目地址: https://gitcode.com/gh_mirrors/da/data-warehouse-learning
项目地址: https://gitcode.com/gh_mirrors/da/data-warehouse-learning
实时数仓作为企业数字化转型的核心基础设施,正成为大数据领域的技术焦点。本文将深入解析基于Flink、Doris、Paimon等主流技术栈的企业级完整解决方案,涵盖架构设计、实战部署到性能优化的全流程。
🏗️ 实时数仓架构深度解析
技术架构全景图
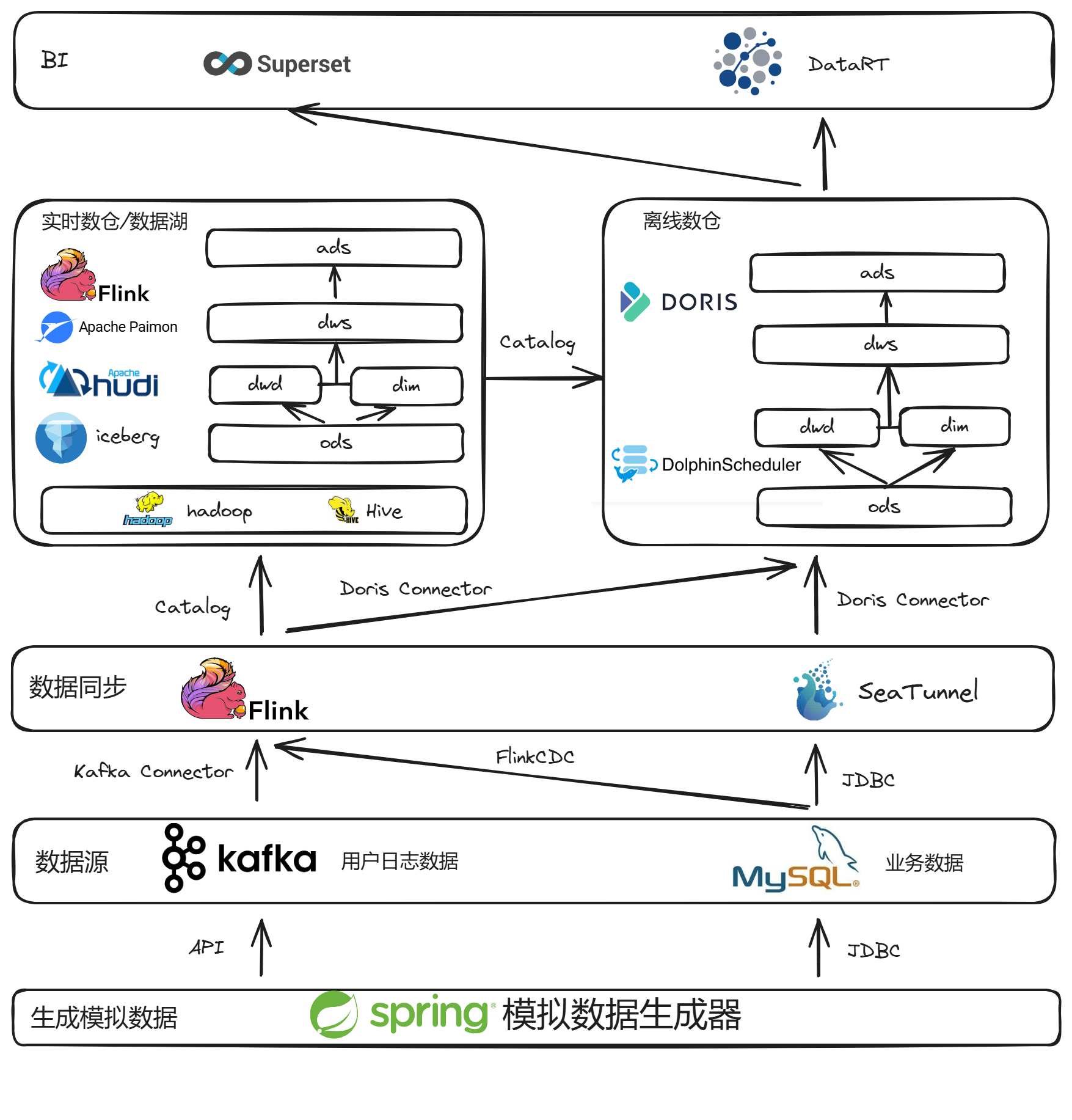
核心架构特点:
- 双引擎驱动:同时支持实时流处理和离线批处理,满足不同业务场景需求
- 多存储方案:提供Doris、Paimon、Hudi、Iceberg等多种数据存储选择
- 全链路监控:从数据采集到最终展示的完整监控体系
分层架构设计:
- ODS层:原始数据存储,通过Kafka、MySQL CDC等技术接入业务数据
- DWD/DIM层:数据清洗与维度建模,构建标准化数据模型
- DWS层:轻度汇总与主题宽表,支撑业务分析需求
- ADS层:应用数据服务与指标输出,直接面向业务应用
核心技术组件选型
Flink实时计算引擎:
- 支持SQL和DataStream API两种开发模式
- 提供Exactly-Once语义保证数据一致性
- 内置丰富的连接器支持多种数据源
数据湖存储方案对比:
| 技术组件 | 适用场景 | 核心优势 | 性能指标 |
|---|---|---|---|
| Doris | 实时分析查询 | 高性能MPP架构 | 查询延迟<1s |
| Paimon | 实时数仓存储 | 流批一体设计 | 写入吞吐>10MB/s |
| Hudi | 增量数据处理 | 事务性保证 | 支持upsert操作 |
| Iceberg | 大规模数据管理 | 格式标准化 | 支持ACID事务 |
🚀 快速部署实战指南
环境准备与系统要求
基础环境配置:
- Java 8+ 运行环境
- Maven 3.6+ 构建工具
- MySQL 5.7+ 数据库
- Kafka 2.8+ 消息队列
部署步骤详解:
-
项目克隆与初始化
git clone https://gitcode.com/gh_mirrors/da/data-warehouse-learning cd data-warehouse-learning mvn clean install -
依赖组件安装
# 安装大数据组件集群 cd src/main/java/org/bigdatatechcir/learn_flinkcdc/mysql_2_doris/ docker-compose up -d
数据生成与实时采集
业务数据模拟: 项目提供完整的电商业务数据生成工具,位于src/main/java/org/bigdatatechcir/warehouse/datageneration/目录,可生成:
- 用户交易行为数据
- 商品浏览记录
- 订单支付信息
实时数据采集流程:
- 用户日志数据通过Kafka实时采集,配置示例见
src/main/java/org/bigdatatechcir/learn_kafka/模块
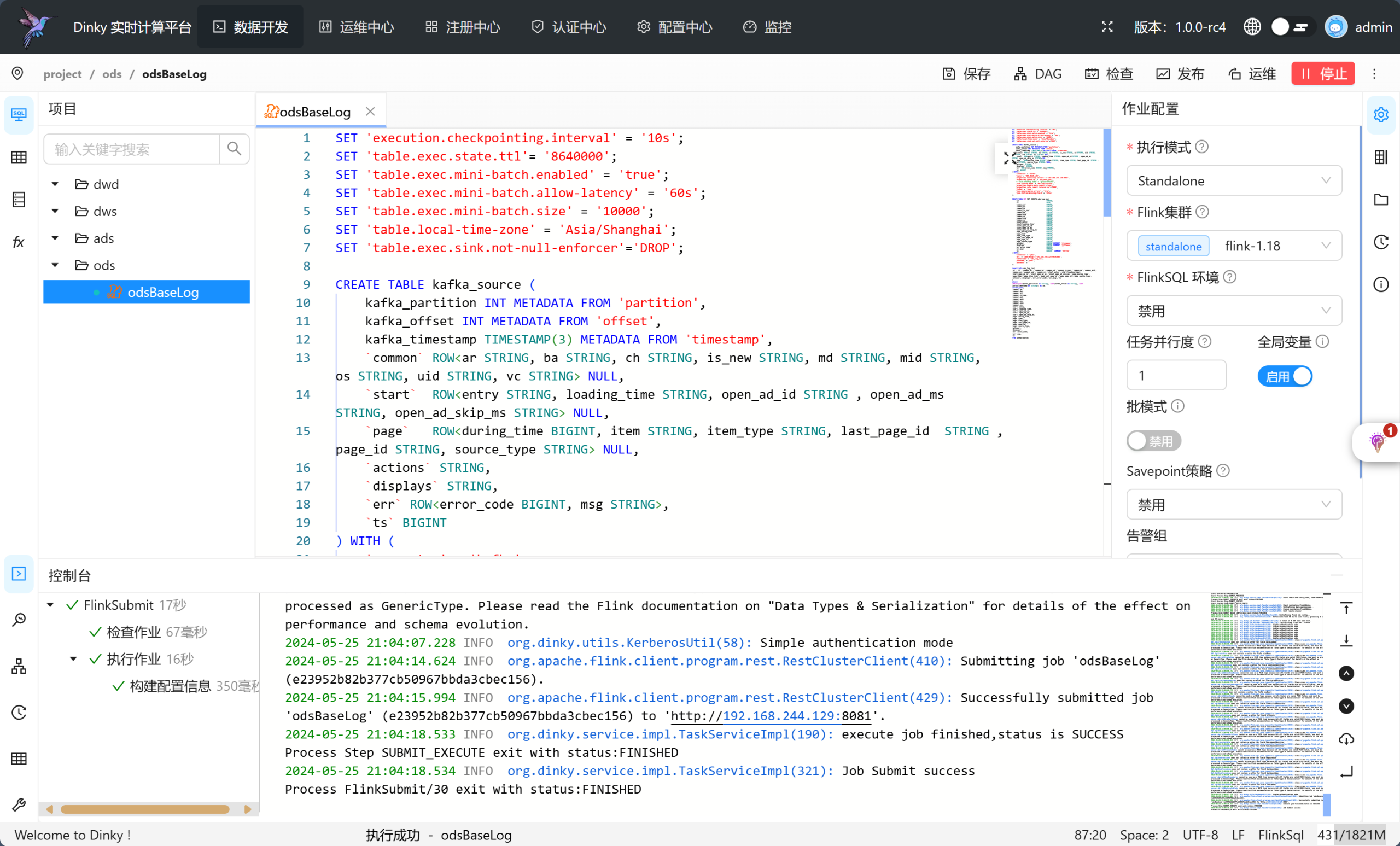
💡 核心功能模块详解
Flink实时计算能力
典型应用场景:
- 实时用户行为分析:监控用户点击、浏览等行为
- 实时业务指标计算:计算GMV、UV、PV等核心指标
- 数据质量实时监控:及时发现数据异常
配置参数参考:
-- 执行模式:Standalone/YARN
-- 集群版本:flink-1.18
-- 时区配置:Asia/Shanghai
数据湖架构实践

Paimon数据湖优势:
- 流批一体:同一份数据支持实时和离线处理
- 事务支持:保证数据操作的原子性和一致性
- Schema演进:支持表结构的动态变更
SeaTunnel数据同步
连接器丰富度: 项目包含90+ SeaTunnel连接器配置,覆盖主流数据源和目标,位于src/main/java/org/bigdatatechcir/learn_seatunnel/目录
🎯 实战演练全流程
完整构建流程
-
数据源配置
- MySQL业务数据库连接配置
- Kafka主题和消费者组设置
- 数据格式定义与解析
-
数据处理管道搭建
- ODS层数据接入与存储配置
- DWD层数据清洗与标准化处理
- DWS层数据聚合与主题构建
- ADS层指标输出与可视化对接
典型业务场景实现
电商实时大屏:
- 实时交易额监控:秒级更新交易数据
- 用户活跃度分析:实时统计在线用户
- 商品热销排行:基于实时点击数据计算
🔧 性能优化与最佳实践
存储优化策略
表分区设计:
- 按时间分区:适合时序数据场景
- 按业务维度分区:提升查询效率
- 合理设置分桶策略:优化数据分布
数据压缩配置:
- 选择合适的压缩算法:ZSTD/LZ4/Snappy
- 平衡压缩率与CPU开销:根据业务需求调整
- 监控存储空间使用:及时优化存储策略
查询性能调优
索引优化技巧:
- 为高频查询字段创建索引
- 合理设置索引类型:B-Tree/Bitmap等
- 定期维护索引:重建碎片化索引
📊 项目价值与总结
技术价值体现
架构先进性:
- 采用业界主流技术栈,保证技术前瞻性
- 提供多种技术方案对比,便于技术选型决策
- 标准化的数据处理流程,提升开发效率
业务价值贡献:
- 为企业级数仓建设提供完整参考模板
- 支持实时业务决策,提升企业响应速度
- 降低技术门槛,加速大数据人才培养
实践指导意义
通过本项目的学习和实践,您将能够:
- 快速掌握企业级实时数仓的构建方法
- 理解各技术组件的适用场景和配置要点
- 为实际业务场景提供强有力的数据支撑能力
🔍 进阶学习资源
项目提供了丰富的学习模块,包括:
- Flink学习:10个核心模块,覆盖API、窗口、状态管理等
- Kafka实践:4个专题,涵盖生产者、消费者、主题管理等
- SeaTunnel连接器:90+配置示例,覆盖主流数据源
- 数据湖技术:Paimon、Hudi、Iceberg的完整应用案例

该项目不仅是技术实现的展示,更是大数据工程师成长的学习平台。无论您是初学者还是资深开发者,都能从中获得有价值的技术洞察和实践经验。
【免费下载链接】data-warehouse-learning 【2024最新版】 大数据 数据分析 电商系统 实时数仓 离线数仓 建设方案及实战代码,涉及组件 flink、paimon、doris、seatunnel、dolphinscheduler、datart、dinky、hudi、iceberg。 项目地址: https://gitcode.com/gh_mirrors/da/data-warehouse-learning
© 版权声明
文章版权归作者所有,未经允许请勿转载。


