全球首例AI涉刑事调查案给企业IT什么警示?从桌面支持视角看AI工具的合规边界与落地治理

🔥
个人主页:
杨利杰YJlio
个人主页:
杨利杰YJlio
❄️
个人专栏:
《Sysinternals实战教程》
《Windows PowerShell 实战》
《WINDOWS教程》
《IOS教程》
个人专栏:
《Sysinternals实战教程》
《Windows PowerShell 实战》
《WINDOWS教程》
《IOS教程》
《微信助手》
《锤子助手》
《Python》
《Kali Linux》
《锤子助手》
《Python》
《Kali Linux》
《那些年未解决的Windows疑难杂症》
🌟
让复杂的事情更简单,让重复的工作自动化



全球首例AI涉刑事调查案给企业IT什么警示?从桌面支持视角看AI工具的合规边界与落地治理
- 1. 这篇文章想解决什么问题?
- 2. 从一条 AI 新闻开始:为什么这件事值得 IT 人员高度关注?
- 3. 为什么桌面支持会成为 AI 合规的第一道现实防线?
-
- 3.1 AI 风险最先落地的位置,不是会议室,而是用户桌面
-
- 场景一:员工私自安装 AI 客户端
- 场景二:浏览器插件型 AI 滥装
- 场景三:把企业文档直接喂给外部 AI
- 场景四:AI 输出被当成正式建议
- 3.2 桌面支持为什么最容易第一个发现问题?
- 4. 企业终端里,最需要优先管住的 5 类 AI 风险
-
- 4.1 数据外发风险
- 4.2 工具来源与软件供应链风险
- 4.3 输出可信度风险
- 4.4 权限绕过与边界模糊风险
- 4.5 审计缺失风险
- 5. 桌面支持如何落地?我建议直接建立这 6 条 AI 使用边界
-
- 5.1 先建软件准入边界
- 5.2 再建数据输入边界
- 5.3 浏览器插件要单独管
- 5.4 AI 输出必须有人复核
- 5.5 做最小可用审计
- 5.6 培训不要讲概念,要讲场景
- 6. 我更推荐企业这样引入 AI:先控边界,再谈提效
-
- 6.1 正确顺序应该是这样
-
- 情况一:全面放开,后面被动补锅
- 情况二:因为担心风险,最后一刀切禁用
- 6.2 哪些 AI 使用场景更适合优先开放?
- 6.3 哪些场景更适合先收紧?
- 7. 如果我是桌面支持负责人,我会这样写一版 AI 使用 SOP
-
- 7.1 目标
- 7.2 适用范围
- 7.3 允许场景
- 7.4 禁止场景
- 7.5 审批与复核
- 7.6 日志与审计
- 8. 写在最后:AI 真正进入企业时,拼的不是谁先用,而是谁先把边界讲清楚

1. 这篇文章想解决什么问题?
今天看到一条很有冲击力的 AI 新闻:AI 工具不再只是效率工具,它正在被放到“责任”和“边界”的放大镜下重新审视。
对很多人来说,这可能只是一个热点;
但对我这种长期站在 企业 Windows 桌面支持 / IT 终端管理 / 工具落地 一线的人来说,这条消息真正值得关注的,不是“热闹”,而是一个非常现实的问题:
当 AI 工具开始进入企业终端、办公桌面和支持流程后,IT 部门到底应该怎么管?
这篇文章我想讲清楚 4 件事:
- 为什么这类 AI 新闻,桌面支持人员必须重视
- 企业终端里最容易被忽视的 AI 风险点在哪里
- IT / 桌面运维如何建立一套可落地的 AI 使用边界
- 怎样把“AI 合规”写成真正能执行的 SOP,而不是口号
如果你平时负责企业电脑、办公终端、标准软件、浏览器策略、终端初始化、权限和支持工单,这篇文章会非常贴近你的实际工作。

2. 从一条 AI 新闻开始:为什么这件事值得 IT 人员高度关注?
先说结论:
AI 的风险,已经不再只是“回答准不准”,而是开始进入“输出会不会带来现实后果”的阶段。
过去很多人理解 AI,停留在下面这些层面:
- 能不能写文案
- 能不能做总结
- 能不能查资料
- 能不能提升办公效率
但今天这类新闻提醒我们,问题已经升级了:
- AI 输出是否可能被误用
- AI 建议是否可能越过现实边界
- 企业内部员工是否可能把 AI 当成“非正式决策者”
- 一旦出事,责任边界怎么划
也就是说,AI 进入企业环境后,它不再只是一个“新工具”,而正在变成一个“需要被治理的系统变量”。
这对桌面支持意味着什么?
意味着你以后要处理的,可能不只是:
- Outlook 登不上
- OneDrive 不同步
- Teams 没声音
- 打印机连不上
还会越来越多地碰到这些问题:
- 员工私装 AI 客户端是否允许
- 浏览器端 AI 插件是否该开放
- 本地知识库和聊天记录是否涉及敏感信息
- AI 生成内容能不能进入正式业务流
- AI 工具接入企业环境后,日志、权限、审计怎么做
站在企业桌面运维视角,这已经不是一个“会不会用 AI”的问题,而是“怎么让 AI 在可控边界内被使用”的问题。

3. 为什么桌面支持会成为 AI 合规的第一道现实防线?
很多人会觉得,AI 合规应该是法务、内控或者安全团队的事。
这话没错,但只说了一半。
因为在企业真正落地时,AI 首先碰到的不是制度,而是终端。
也就是说,AI 是否会进入企业环境,往往先体现在这些地方:
- 员工电脑装了什么
- 浏览器能访问什么
- 插件能不能装
- 数据能不能上传
- 本地缓存落在哪里
- 登录凭据怎么管
- 日志能不能追
- 权限有没有分层
这些东西,恰恰就是桌面支持和终端管理最熟悉的战场。
3.1 AI 风险最先落地的位置,不是会议室,而是用户桌面
举几个最典型的场景:
场景一:员工私自安装 AI 客户端
为了图方便,用户自己装了桌面版 AI 工具,用来处理邮件、翻译文档、总结会议纪要。
问题在于:
- 软件来源是否可信
- 是否带自动同步
- 是否上传本地内容
- 是否绕过公司标准软件清单
场景二:浏览器插件型 AI 滥装
用户在 Chrome / Edge / Firefox 里装了各种 AI 插件,看起来只是“提高效率”,实际上可能:
- 读取网页内容
- 捕获表单输入
- 获取剪贴板内容
- 调用第三方接口
场景三:把企业文档直接喂给外部 AI
这在现实里非常常见,尤其是:
- 会议纪要
- 合同草稿
- 客户资料
- 内部流程文档
- 配置脚本和系统信息
一旦没有脱敏、没有审批、没有边界,这种“顺手一贴”的动作,本身就可能成为风险源。
场景四:AI 输出被当成正式建议
比如用户问 AI:
- 某个策略怎么配置
- 某个注册表能不能删
- 某个软件能不能绕过限制
- 某个系统异常怎么“快速解决”
如果员工没有基本判断能力,AI 的输出就可能被误当成“可信方案”直接执行。
3.2 桌面支持为什么最容易第一个发现问题?
因为你是最早接触这些“异常表象”的人:
- 软件异常安装
- 浏览器扩展异常增长
- 本地缓存异常
- 用户配置漂移
- 日志里出现未知外联
- 终端出现不在白名单内的进程或服务
所以从企业实际落地角度看,桌面支持不是 AI 合规的外围角色,而是最靠近“真实使用现场”的第一道防线。

4. 企业终端里,最需要优先管住的 5 类 AI 风险
这一节我直接讲重点,不讲空话。
4.1 数据外发风险
这是第一优先级。
风险对象包括:
- 客户信息
- 员工隐私数据
- 内部制度文件
- 合同草稿
- 财务数据
- 系统配置和网络结构信息
很多时候不是员工故意泄露,而是他根本没意识到:
“发给 AI”本身,就是一种对外部系统的输入。
对于企业来说,最大的风险不是 AI 回答错,而是员工把不该出去的数据送出去了。
4.2 工具来源与软件供应链风险
很多 AI 工具看起来只是个客户端、一个插件、一个增强助手。
但从终端管理角度,你必须问清楚:
- 软件是谁发布的
- 是否有数字签名
- 是否为官方版本
- 是否带更新器
- 是否自启动
- 是否会调用本地文件权限
这和你平时判断第三方桌面工具、远控软件、下载器的思路,其实没有本质区别。
AI 工具的“新”,并不能抵消桌面运维里最基本的供应链判断逻辑。
4.3 输出可信度风险
AI 的一个真实问题是:
它经常会把“不确定”说得像“很确定”。
这在企业环境里会带来一个特别危险的后果:
员工会把“像答案的内容”当成“可以执行的结论”。
在桌面支持场景里,这种风险尤其明显,比如:
- 建议修改注册表
- 建议删除系统文件
- 建议关闭安全组件
- 建议用脚本批量处理终端
如果没有验证机制,AI 输出就可能直接变成事故入口。
4.4 权限绕过与边界模糊风险
员工在用 AI 时,很容易产生一种错觉:
“只是问一下,不算真正操作。”
但现实不是这样。
只要 AI 已经参与了:
- 操作建议生成
- 脚本生成
- 内容生成
- 决策辅助
那它就已经进入业务边界了。
这时候如果企业没有明确规定:
- 哪些场景可以用
- 哪些场景必须人工复核
- 哪些内容禁止输入
- 哪些输出不能直接执行
那边界一定会越来越模糊。
4.5 审计缺失风险
最后一个最容易被忽视。
很多企业现在引入 AI,最大的问题不是“有没有人用”,而是:
用了之后,根本追不回来。
比如:
- 谁用了
- 用了哪个工具
- 输入了什么类型的数据
- 输出被拿去做了什么
- 是否留存了记录
- 是否触发了审批
没有审计,就没有复盘;没有复盘,就没有真正的治理。

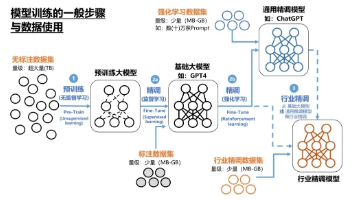
5. 桌面支持如何落地?我建议直接建立这 6 条 AI 使用边界
讲到这里,最关键的不是“意识到风险”,而是“怎么做”。
下面这 6 条,我认为是企业桌面支持最值得先落地的动作。
企业AI治理目标
软件准入边界
数据输入边界
插件与浏览器边界
日志与审计边界
输出复核边界
培训与工单边界
5.1 先建软件准入边界
不要上来就谈“大模型战略”,先把最基础的事情做掉:
- 哪些 AI 客户端允许安装
- 哪些网站允许访问
- 哪些插件允许启用
- 哪些版本必须统一
- 哪些来源必须禁用
对桌面支持来说,最先能落地的治理,永远不是宏大原则,而是软件白名单。
5.2 再建数据输入边界
要明确写清楚:
- 哪些内容禁止输入外部 AI
- 哪些内容需要脱敏后才能输入
- 哪些内容只能使用企业内部 AI
- 哪些场景必须先走审批
这一条一定要写成员工能看懂的话,而不是法务术语。
比如不要写:
禁止处理敏感业务数据
而要写成:
- 客户姓名、电话、邮箱禁止直接输入外部 AI
- 合同全文禁止直接输入公共 AI 平台
- 内部网络结构、服务器信息、账号信息禁止输入 AI
- 涉及员工隐私和绩效内容禁止输入 AI
5.3 浏览器插件要单独管
这一条特别重要。
因为现在大量 AI 使用行为,其实不是来自独立客户端,而是来自:
- Edge 扩展
- Chrome 扩展
- 网页侧助手
- 输入法联动
- PDF / Office 插件
建议最少做到:
- 禁止用户自行装未经审批的 AI 插件
- 对已装插件做周期审查
- 高风险插件纳入黑名单
- 对浏览器扩展目录和策略做标准化管理
很多企业把客户端管住了,却把浏览器扩展放开了,这会留下非常大的口子。
5.4 AI 输出必须有人复核
这一条一定要写进制度,也要写进支持话术。
原则非常简单:
AI 可以辅助,但不能直接替代正式判断。
在企业 IT / 桌面支持场景里,至少这些内容不能“AI 生成就直接执行”:
- 注册表修改建议
- 系统脚本
- 权限调整
- 网络策略调整
- 删除类操作
- 终端批量命令
你可以让 AI 当“初稿助手”,但不能让它当“最终审批人”。
5.5 做最小可用审计
如果现阶段企业还没有完整 AI 平台,那至少也要做到最小留痕:
- 用了什么工具
- 处理了什么类型的问题
- 是否涉及企业数据
- 是否经过人工复核
- 是否进入正式业务流程
这个动作的价值非常高,因为它会让 AI 从“灰色自发使用”慢慢转向“可追踪使用”。
5.6 培训不要讲概念,要讲场景
很多 AI 培训失败,问题就在于太喜欢讲愿景,不讲现场。
真正有效的培训应该直接回答这些问题:
- 我能不能把 Excel 导出数据发给 AI?
- 我能不能让 AI 帮我写 PowerShell 脚本?
- 我能不能把工单截图发给 AI 让它分析?
- 我能不能把 Outlook 邮件内容复制给 AI 翻译?
员工真正需要的不是“AI 时代到来了”,而是“这件事我到底能不能做”。

6. 我更推荐企业这样引入 AI:先控边界,再谈提效
我见过很多企业在引入新工具时,最容易犯的错误就是:
一上来只谈效率,不谈边界。
但在 AI 这件事上,我反而建议顺序倒过来:
6.1 正确顺序应该是这样
- 先明确哪些场景能用
- 再明确哪些数据不能碰
- 再明确哪些输出必须复核
- 最后才谈怎么提高效率
因为如果顺序反了,就很容易出现两种情况:
情况一:全面放开,后面被动补锅
表面上效率提升了,实际上风险已经散到每台终端上了。
情况二:因为担心风险,最后一刀切禁用
这也不理想,因为会逼员工转去用更不可控的私人方式。
真正成熟的做法,不是“全开”或“全禁”,而是“在可控边界内允许高价值使用”。
6.2 哪些 AI 使用场景更适合优先开放?
从企业桌面支持和 IT 场景看,我更建议优先开放这几类:
- 通用知识问答
- 已脱敏文档总结
- 非敏感脚本初稿生成
- 标准化话术润色
- 培训材料框架整理
- FAQ 初稿生成
6.3 哪些场景更适合先收紧?
- 含客户数据的内容处理
- 含账号信息、权限信息、网络结构信息的终端问题
- 合同、法务、薪酬、绩效类内容
- 可直接执行的系统脚本和批量变更
- 涉及对外正式承诺的文档生成
一句话:越靠近真实数据、真实系统、真实责任边界的内容,越不能放任 AI 自由进入。

7. 如果我是桌面支持负责人,我会这样写一版 AI 使用 SOP
这一节我直接给一个可落地骨架,你后面可以继续往企业内部文档改。
7.1 目标
规范企业终端环境中 AI 工具的使用边界,控制数据外发、工具失控、输出误用和审计缺失风险。
7.2 适用范围
- Windows 办公终端
- 浏览器与插件环境
- 企业标准软件体系
- IT 支持与知识库使用场景
- 员工桌面侧 AI 辅助办公场景
7.3 允许场景
- 非敏感文本润色
- 通用知识检索
- 已脱敏内容总结
- 培训材料框架生成
- FAQ、工单模板初稿整理
7.4 禁止场景
- 输入客户隐私信息
- 输入内部账号、密码、Token、配置文件
- 输入未脱敏合同、报价、财务数据
- 直接执行 AI 生成的高风险脚本
- 安装未经审批的 AI 客户端或浏览器插件
7.5 审批与复核
- 新 AI 工具接入,需走软件准入审批
- 高风险使用场景,需人工复核输出
- 涉及业务正式文档,需责任人确认后方可使用
7.6 日志与审计
- 建立 AI 工具清单
- 周期检查终端安装情况
- 周期审查浏览器扩展
- 对重点场景建立使用记录
这类 SOP 写得越像现场能执行的动作,价值越高;写得越抽象,越容易最后没人看、没人用。

8. 写在最后:AI 真正进入企业时,拼的不是谁先用,而是谁先把边界讲清楚
今天这条 AI 新闻,对我最大的提醒不是恐慌,也不是唱衰。
而是让我更确定一件事:
AI 真正进入企业环境后,最先决定成败的,不是模型能力,而是治理能力。
谁先把下面这些事讲清楚,谁就更可能把 AI 真正用好:
- 什么能用
- 什么不能用
- 谁能装
- 谁能审
- 什么要脱敏
- 什么要留痕
- 什么必须人工复核
从桌面支持视角看,AI 合规并不是遥远的大词,它就是你每天面对的终端、软件、插件、权限、日志和工单。
所以,真正成熟的企业,不会只问“AI 能不能提高效率”,还会问“AI 进入我的终端环境后,责任边界有没有被重新定义”。
这,才是今天这条 AI 新闻对企业 IT 最有价值的地方:它提醒我们,AI 的落地从来不只是技术接入,更是边界接入、责任接入和治理接入。
返回顶部
© 版权声明
文章版权归作者所有,未经允许请勿转载。