
一篇文章带你理解Spring AI和Spring AI Alibaba最火技术
无奈的现状
💻 作为一名还在深耕传统 Java 的在校生,你是不是也有过这种时刻:
刷着抖音——
📱 “AI 三句话写一个游戏”
📱 “程序员要被取代了!”
📱 “不会用 Codex / Claude Code / Cursor 等于失业”
再打开 BOSS 直聘——
💼 “要求:熟练使用 AI 编程工具”
💼 “了解 Agent / Skill / 工作流优先”
然后你沉默了。
😶🌫️:我连这些工具都没怎么用过……
😨:我是不是已经落后了?
💔:前途是不是要没了?
——别慌,真的别慌。
你现在的状态,其实是绝大多数人正在经历的阶段:
👉 会写代码,但不会用 AI 加速
👉 听说过 Agent,但不知道怎么落地
👉 知道 RAG,但不知道下一步是什么
👉 被新概念轰炸,但没有体系
这不是你不行,是——
🚨 行业在突然加速变道
🧠 真相 1:AI 不是替代你,而是筛选你
- 不会写代码的人,用 AI 只能拼 prompt
- 会写代码的人,用 AI 能做系统
👉 区别在这:
-
普通人:让 AI 写一个页面
-
你:让 AI 接入你的系统、调用你的工具、走你的流程
💡 未来拼的是:工程能力 + AI能力,而不是谁更会复制粘贴
⚙️ 真相 2:你已经在正确的路上了
你会 Java ✔
你想理解 Agent ✔
这些不是落后,是——
🔥 正在进入“AI工程师”的核心路径
🚀 那你该干嘛?一句话:
👉 从“写代码的人”升级成“调度 AI 的人”
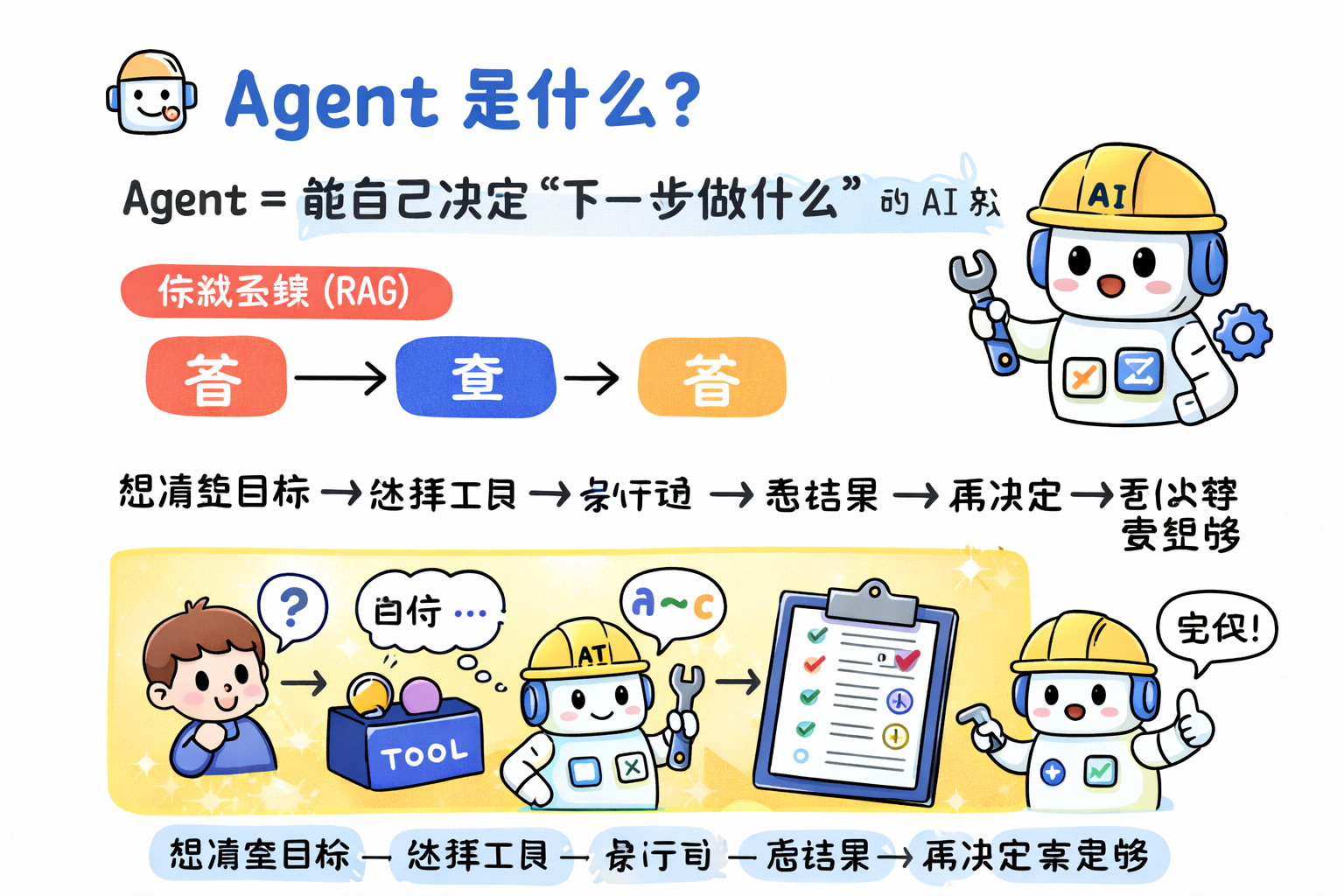
🤖 用最简单的话解释 Agent 是啥:
比如回答一个用户的问题:
以前你写的是:
用户请求 → 代码逻辑(搜数据库/网络查询) → 返回结果
现在你要做的是:
用户请求 → LLM思考 → 调用工具(tool) → 多步推理 → 返回结果
你不是被替代
你是在升级成——
🧠 “agent应用开发工程师”
😎 最后送你一句很真实的话:
❌ 被 AI 取代的,从来不是程序员
✅ 是不会用 AI 的程序员
🌱 别焦虑,你只是在升级阶段
别人三句话生成游戏,那只是 demo
你做的是系统,那才是企业级能力
👉 AI时代拼的不是写代码,而是:看得懂代码、理得清流程、能做优化、会设计系统的人。这些东西,你让一个完全不是计算机行业的人来做,他们根本做不到,只会口嗨
但是话说回来:你又不得不承认AI的强大,不得不享受AI带来的好处
想入门agent,第一步你得学会使用AI编程
工具推荐
🚀 AI时代开发者开局四件套(别再拿着石器时代装备打现代战争了)
🧰 1️⃣ IDE先升级!
别再守着你那古董级 IDEA 2021 了兄弟…
👉 现在已经是 IDEA 2025 + JetBrains AI 的时代了
直接内置 AI:
-
写代码 ✔
-
改 bug ✔
-
理解项目 ✔
💬 一句话:
👉 IDE 已经从“编辑器”进化成“副驾驶”了
🤖 2️⃣ 智能体选谁?
别纠结太多,直接上:Codex
它不是简单补全工具,而是:
👉 能写代码 + 调工具 + 跑流程 的 AI 工程师
💰 价格:还行(没你想的那么离谱)
⚡ 能力:够用(甚至有点猛)
👉 性价比选手,适合入局 Agent 的第一步
🧠 3️⃣ 大模型怎么选?
给你最实用的分法👇
-
🧪 学习 / 小 demo:GPT-5.4 Medium
👉 便宜 + 快 + 够用 -
🏗️ 项目 / 企业级:GPT-5.4 High
👉 稳定 + 智商在线 + 不容易翻车
💡 别一上来就拉满配置——
👉 用对,比用贵更重要
🌐 4️⃣ 网络环境(现实但必须说)
如果你现在:
❌ GitHub 打不开
❌ Google 访问不了
❌ AI 工具各种报错
那你不是不会用 AI ——
👉 是网络在卡你脖子😅
所以:
✔ 准备一个稳定的 VPN
✔ 保证能正常访问国外服务
(我自己用的是 ViewTurbo,按流量收费,比较灵活,仅供参考)
Spring AI /Spring AI Alibaba
👉 Spring AI 和 Spring AI Alibaba 本质是同一体系,后者是在前者基础上的增强版封装。
👉 Spring AI Alibaba = 基于 Spring AI + 阿里云生态适配 + 企业级能力扩展
具体来说就是:
- ✔ 对接阿里云模型(通义等)
- ✔ 补齐 Agent / Workflow 等上层能力
- ✔ 增强企业级能力(监控、配置、扩展性)
- ✔ 做了一些工程化优化与封装
所以,如果你是新手的话,我这里推荐你先去B站学习尚硅谷的Spring AI Alibaba去了解一些必要的基础知识,了解基础的语法和LLM思想,配套博客:一篇文章带你快速入门Spring AI Alibaba:与企业接轨-CSDN博客
👉 学完这些基础:LLM调用、RAG、MCP、Tool、Prompt
是不是有种感觉:
😶 “好像懂了,但又没完全懂”
🤔 “AI就这?好像也没啥特别的”
别急——你现在这个阶段,太正常了
因为你现在只是:
👉 “会用AI”
但还没到:
👉 “理解AI系统是怎么工作的”
所以接下来,我不打算再带你看概念了
❌ 不再讲一堆新名词
❌ 不再停留在demo层
👉 我们直接上项目 💥
接下来我会带你:
- 🧠 从一个真实项目出发
- 🔍 一步步拆解:每一步为什么这么设计
- ⚙️ 每一层优化到底解决了什么问题
- 🚀 从“能跑”进化到“能打”
RAG
👉 这套技术,其实就是目前网上最常见的企业级AI开发入门路径
也是我第一次接触“企业级开发”时真正系统学到的东西
接下来我会带你一步步搞懂:
👉 什么是企业级 RAG
👉 为什么要这么设计
👉 每一步到底在解决什么问题
首先,我们知道RAG包括,解析文档+切分文档+存入向量数据库+LLM检索数据库
但是,当你真正开始做 RAG 的时候,很快就会发现——
👉 事情远没有“向量检索 + 丢给 LLM”这么简单
甚至可以说:
💥 一不小心,你的系统就会变成“胡言乱语生成器”
😵💫 问题 1:切太粗 = 喂撑 LLM
如果你把文档切得太大:
👉 一次性塞给 LLM 一大坨上下文
会发生什么?
- 🤯 信息太多,重点被淹没
- 🧠 LLM 抓不到关键点
- 💸 token 疯狂消耗
👉 最终效果:
“看起来信息很多,但一句有用的都没有”
🧩 问题 2:切太细 = 讲不完整
那你可能会想:
👉 那我切细一点?
结果又炸了:
- 📉 信息被切碎
- 🔗 上下文断裂
- 📄 长问题回答不完整
👉 最终效果:
“一句一句都对,但拼不成一句完整的话”
🎯 问题 3:TopK 选不好 = 要么不够,要么混乱
TopK 看起来很简单,其实是个坑王:
- K 太小 👉 信息不够,答不全
- K 太大 👉 噪音进来,答得乱
👉 最终效果:
“不是没答出来,就是答偏了”
🤡 问题 4:只靠向量召回 = 直接进入胡说模式
最致命的问题来了:
👉 如果你只是:
“向量检索 → TopK → 丢给 LLM”
中间什么都不做👇
- ❌ 不做融合
- ❌ 不做重排
- ❌ 不做过滤
那基本等于:
👉 把一堆“可能相关、也可能不相关”的内容,直接喂给 LLM
结果就是:
💥 上下文被污染
💥 LLM 开始自由发挥
💥 一本正经胡说八道
问题远不止这些,坑其实一大堆。
那怎么办?难道 RAG 就这样了吗?
👉 当然不是。
接下来,我会给你一个整体解决思路,再带你一条一条拆开讲清楚:
- 为什么要这么设计
- 每一步到底在解决什么问题
- 这些优化是怎么一步步叠出来的
我们不再做这种简单粗暴的链路:
解析文档->切分文档->文档向量化->Query → 向量检索 → TopK → LLM
📄 1️⃣ 知识入库阶段(离线链路)
文件上传
→ 存储(MinIO + MySQL)
→ 异步解析(RabbitMQ)
→ 文档切分(chunk)
→ 向量化(embedding)
→ 写入 Elasticsearch2️⃣ 问答阶段(在线链路)
用户提问
→ Query Rewrite(问题优化)
→ Query Planning(策略选择)
→ 结构化直答(如果命中)
→ Hybrid Recall(向量 + 关键词)
→ Score Fusion(融合)
→ Rerank(重排)
→ Retrieval Guard(是否可答)
→ TopN / Token 控制
→ Context Builder(上下文构建)
→ Answer Guard(生成前兜底)
→ LLM 生成答案
→ 返回结果 + 日志 + 缓存👉 从海量知识里,筛出最有用的信息,并安全地交给 LLM
1.从文件上传开始
用户上传文件后,系统会先做两件事:
- 把原始文件存入 MinIO
- 把文档元数据写入 MySQL
这里保存的不是“答案”,而是最原始的知识来源
© 版权声明
文章版权归作者所有,未经允许请勿转载。


