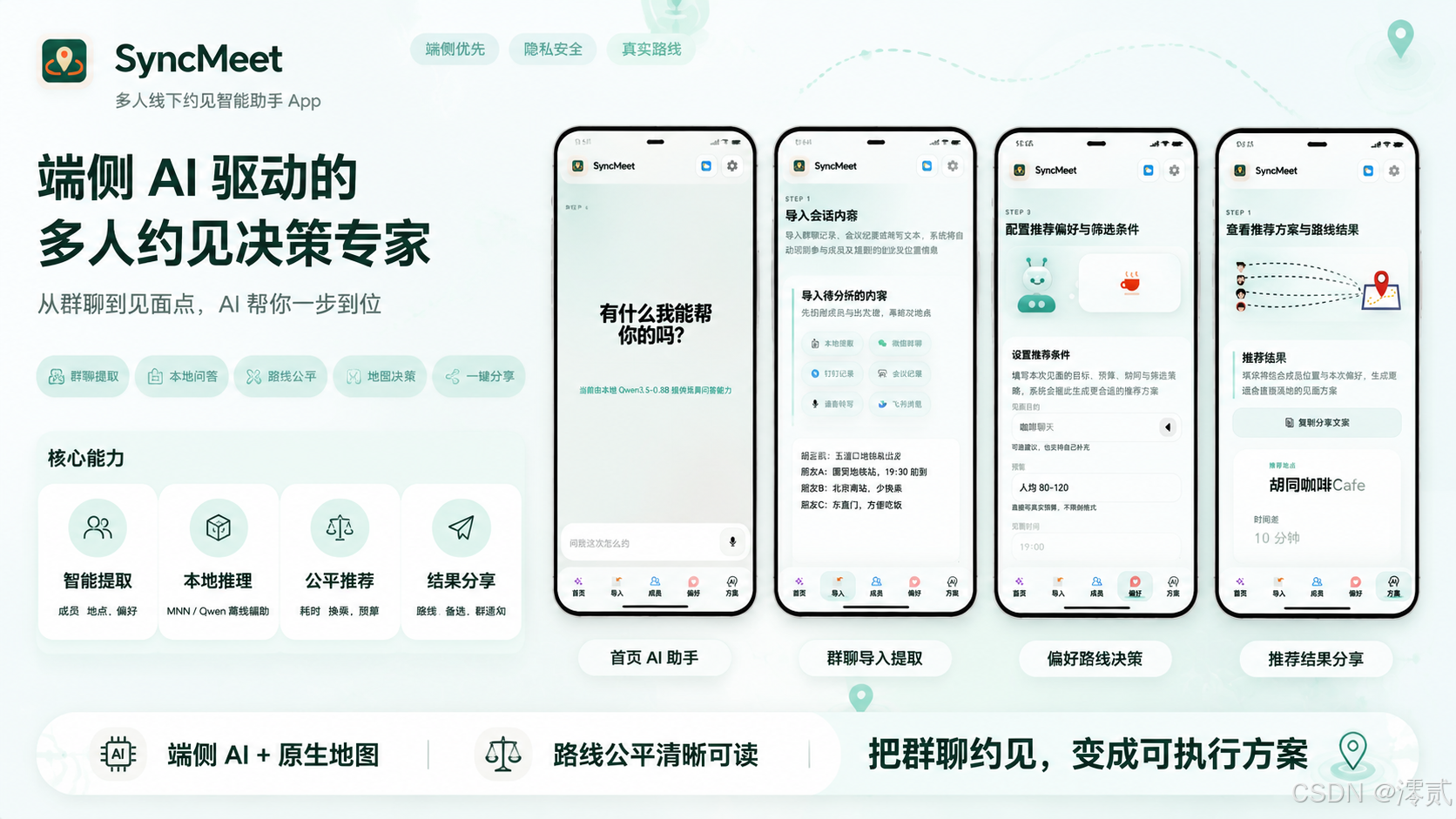
从群聊到会面决策:一个端侧 AI 手机应用的工程化实践
文章目录
-
- 一、为什么这个问题适合做成手机端 AI 应用
- 二、整体架构:为什么不是纯原生,也不是纯 Web
-
- 为什么上层 UI 用 Web
- 为什么底层能力必须原生化
- 三、为什么端侧模型不是直接输出最终答案
- 四、端侧模型接入:MNN + JNI 的选择
-
- Java 层负责什么
- C++ 层负责什么
- 五、为什么结构化提取不能只靠“提示词约束”
- 六、地图能力为什么一定要走原生插件
- 七、规则系统为什么仍然必要
- 八、移动端 AI 应用里一个常被忽略的问题:流式体验
- 九、构建链路:从前端资源到 APK
- 十、这个项目里最重要的技术取舍
-
- 1. 不追求“全靠模型”
- 2. 不追求“全原生页面”
- 3. 不追求“先做最大模型”
- 十一、后续还能继续优化什么
- 结语
很多 AI Demo 停留在“能对话”这一层,但真正落地到移动端时,问题很快会变成另外一套:
- 模型放在哪里跑
- 手机端怎么接入本地推理
- 非结构化输入怎么变成稳定的结构化结果
- 地图、路线、语音这类强设备能力怎么和 AI 组合
- 怎样把一个“会聊天的模型”变成“能完成任务的应用”
SyncMeet 是我围绕这个问题做的一个实践项目。
它的目标不是做一个泛泛的聊天机器人,而是做一个面向多人线下约见场景的手机端智能会面助手:从群聊、会议纪要、语音输入中提取参与者与出发地,结合真实地图 POI 和路线规划能力,生成推荐会面点、每个人的路线说明,以及可以直接发到群里的通知文案。
这篇文章不重点讲产品包装,而是重点讲这个项目背后的几个工程设计:为什么这样拆、端侧模型怎么接、原生能力怎么接进来,以及在移动端做 AI 应用时哪些地方不能只靠模型。
Gitee仓库:https://gitee.com/zhang-zhanhua-000/sync-meet-app
一、为什么这个问题适合做成手机端 AI 应用
多人约见看起来不是一个“典型 AI 问题”,但它非常适合拿来做手机端 AI 落地:
- 输入是自然语言,通常来自群聊、会议纪要、语音转写
- 输出不是一句答案,而是一个结构化决策结果
- 强依赖地图、路线、天气、语音、权限等移动端能力
- 涉及隐私,群聊内容和出发位置不太适合全量上传
- 结果必须可执行,不能只是“推荐一个点”
这意味着它天然要求一套组合式架构:
- 模型负责理解和提取
- 地图负责真实世界约束
- 规则负责稳定性和可解释性
- 手机端负责交互闭环
这也是 SyncMeet 的核心思路:端侧 AI 优先,真实地图闭环。
二、整体架构:为什么不是纯原生,也不是纯 Web
项目当前采用的是四层结构:
-
ui/:移动端交互层 -
mobile-build/:打包后的前端静态资源 -
android/:Android 原生能力层 -
MNN + JNI:本地推理层
对应到仓库结构大致是这样:
SyncMeets/
├─ ui/
├─ mobile-build/
├─ android/
├─ vendor/
├─ models/
└─ models_mnn/
为什么上层 UI 用 Web
这个项目的页面流程比较多,而且交互迭代频率高,包括:
- 文本导入
- 成员确认
- 偏好设置
- 结果展示
- 设置页
- 天气页
如果这部分一开始就全写成原生页面,开发和改动成本会比较高。相反,用 HTML + CSS + JavaScript 承载上层 UI,可以更快把流程跑通,也更适合频繁修改展示逻辑。
为什么底层能力必须原生化
但这个项目又不能是一个单纯的“套壳 H5”,因为真正值钱的能力都不在页面层:
- 地图
POI联想 - 多人路线规划
- 天气能力
- 离线语音识别
- 本地模型加载
- 流式推理输出
这些能力最终都放到了 Android 原生层,通过 Capacitor 插件暴露给上层。
所以这套架构的真实含义不是“Web 套 Android”,而是:
用 Web 保持交互迭代效率,用原生层承载所有高价值、强设备绑定、强性能约束的能力。
三、为什么端侧模型不是直接输出最终答案
做这类应用时,一个很容易踩的坑是:希望模型一步到位,直接读完整段群聊,然后输出最终会面地点。
这个思路理论上很省事,实际上问题很多:
- 结果不稳定
- 很难约束输出格式
- 很难解释为什么选这个点
- 真实路线、公平性、预算、营业状态等约束不适合交给模型硬猜
所以在 SyncMeet 里,模型并不承担全部逻辑,而是只做它擅长的部分:
- 从群聊中提取参与者和地点文本
- 生成摘要
- 生成偏好补充
- 首页助手问答
- 生成结果解释文案
真正和现实世界强绑定的能力,比如:
-
POI搜索 - 路线规划
- 候选地点打分
- 公平性计算
- 营业状态和预算约束
都交给了地图 SDK 和规则算法。
这个拆分非常关键。它让模型负责“理解人类表达”,让确定性系统负责“理解城市和路线”,最终系统的可控性会高很多。
四、端侧模型接入:MNN + JNI 的选择
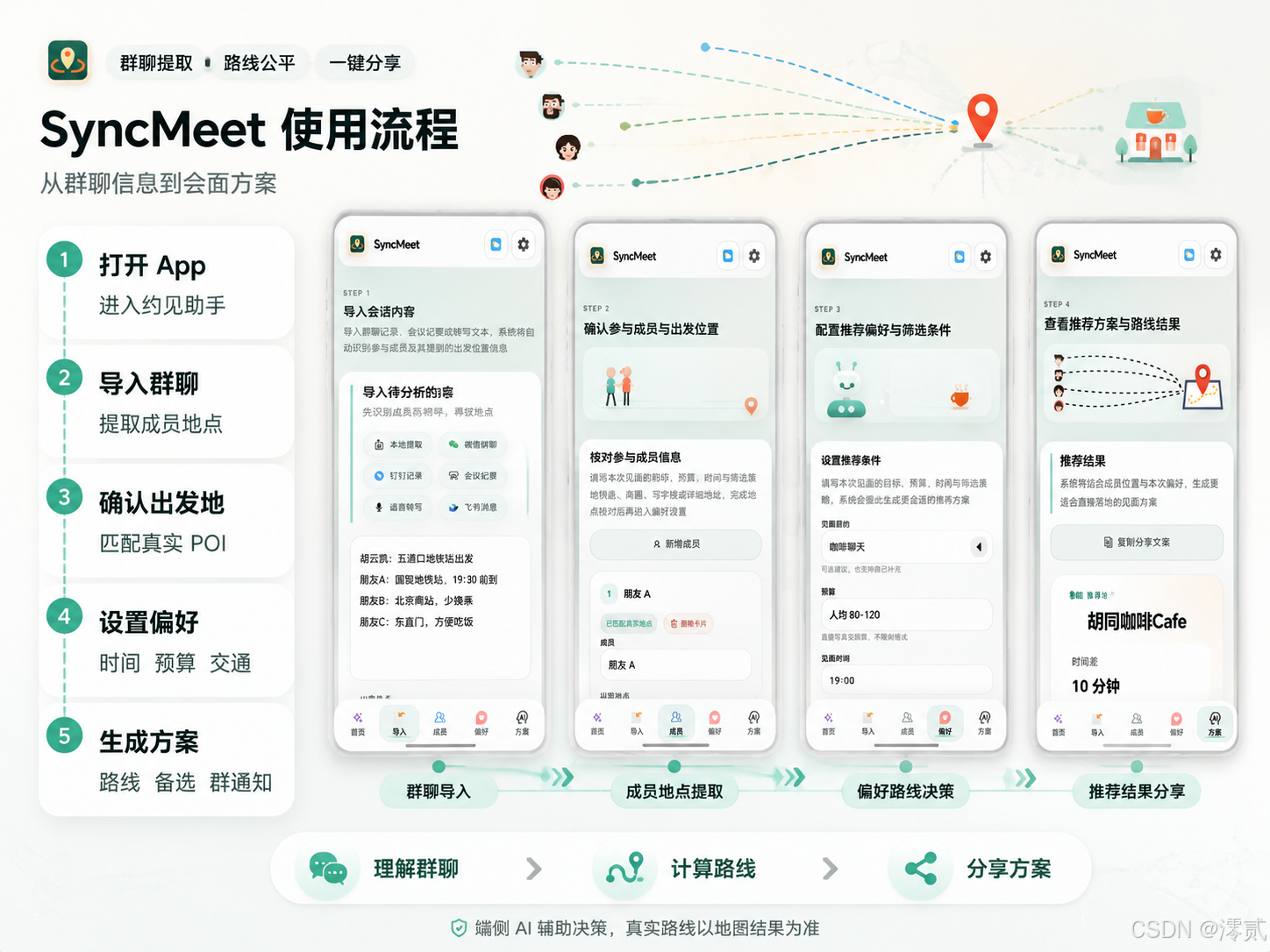
项目当前使用 MNN 作为端侧推理框架,在 Android 侧通过 JNI 接入本地推理链路。
对应代码主要在这几个位置:
- LocalMnnEngine.java
- SyncMeetMNNPlugin.java
- syncmeet_mnn_jni.cpp
Java 层负责什么
LocalMnnEngine 的职责比较清晰:
- 检查模型目录是否完整
- 选择当前可用模型
- 准备运行配置
- 管理
native handle - 对外暴露普通生成、结构化生成、历史对话生成和流式生成接口
这里有两个实现细节我觉得比较关键。
第一,模型目录不是强行打进 APK,而是做成可管理的本地模型目录。这样做的好处是:
- 避免 APK 体积过大
- 允许后续更换模型
- 便于按设备性能选择不同尺寸模型
第二,结构化任务和普通问答任务使用不同的请求配置。比如结构化提取时会把温度、采样范围收得更紧,以减少 JSON 漂移。
C++ 层负责什么
JNI 层做的不是简单包一层函数,而是处理了几个移动端场景里比较麻烦的问题:
-
LLM生命周期管理 - 流式输出
-
UTF-8分片处理 - 逐
token推进生成 - 生成状态恢复
在 syncmeet_mnn_jni.cpp 里,核心路径是:
-
createLLM()创建实例 -
set_config()应用初始配置 -
load()加载本地模型 -
response()启动首轮输出 -
generate(1)逐步推进后续 token
流式输出这块额外做了两层处理:
- 自定义
streambuf捕获模型输出 -
UTF-8分片处理,避免把一个汉字拆坏后直接回传到上层
这个点看起来小,但如果不做,中文流式输出在 UI 上非常容易出现乱码或半字符闪烁。
五、为什么结构化提取不能只靠“提示词约束”
端侧模型在结构化输出上,稳定性通常不如云端大模型,尤其是在:
- 输入长
- 中英混杂
- 群聊口语化强
- 输出
schema稍复杂
这种情况下,如果只靠一句“请输出 JSON”,经常会遇到:
- 前后夹杂解释文本
-
JSON不闭合 - 引号缺失
- 额外字段
- 截断输出
所以在 SyncMeetMNNPlugin.java 里,结构化提取实际上做了三层保障:
- 约束
prompt -
JSON对象抽取 - 失败后的
JSON修复重试
对应思路是:
- 先要求模型严格输出单个
JSON对象 - 再从返回文本里抽出最外层
JSON - 如果解析失败,再把损坏输出和原始任务一起喂回模型,让它只做
JSON修复
这套方案不算优雅,但非常工程化。对于端侧轻量模型来说,比追求“第一次一定正确”更现实。
六、地图能力为什么一定要走原生插件
在这个项目里,真正把“AI 文本理解”变成“可执行决策”的,是地图和路线层。
对应原生能力主要集中在 SyncMeetMapPlugin,它负责:
-
POI联想 - 候选地点搜索
- 多人路线规划
- 结果评分与排序
- 天气查询
为什么这些能力不直接放在上层 JavaScript 里做?
原因有两个:
第一,地图 SDK 和手机权限能力天然更适合原生层承载。
第二,路线规划和候选打分本身是比较重的逻辑,用原生层做性能和数据组织都会更稳。
更重要的是,这层不是在做“查一条路线”,而是在做“多人、多候选点、多路线并发评估”。
它的输出也不是普通地图页面那种原始路线数据,而是会继续进入评分系统,形成类似下面这样的维度:
- 到达时间差
- 平均耗时
- 最长耗时
- 换乘次数
- POI 评分
- 预算匹配
- 营业状态
- 易找程度
- 回程便利性
最终系统输出的不是地图中点,而是一个更接近现实公平的会面点。
七、规则系统为什么仍然必要
很多做 AI 应用的人一开始会倾向于“尽量少写规则”,但这个项目让我更确定一件事:
在移动端真实场景里,规则系统不是模型能力的对立面,而是它的稳定器。
比如群聊里常见这类表达:
- “我从国贸走”
- “我在望京附近”
- “我地铁过去方便点”
- “小李在五道口”
这些文本既口语化,又不规范,还可能混杂玩笑和冗余表达。完全交给模型当然可以做,但在端侧模型尺寸有限时,误漏提取会明显上升。
所以 SyncMeet 实际上采用了“模型 + 规则”的混合提取方案:
- 规则负责说话人片段识别、地点模式匹配、去重和基础可信度判断
- 模型负责补足语义理解和结构化表达
这样做的收益很直接:即使模型输出偶尔漂移,整体结果仍然有兜底。
八、移动端 AI 应用里一个常被忽略的问题:流式体验
做本地模型接入时,很多时候大家会先追求“能不能跑起来”,但当它进入产品界面后,用户很快会感受到另一个维度:流式体验是否自然。
如果流式输出处理不好,会出现很多问题:
- 输出停顿很奇怪
- 中文字符被截断
- 先打一堆思维链痕迹,真正答案很晚才出现
- 结束标志处理不稳定
在这个项目里,上层首页助手是有流式输出能力的,而底层又是端侧模型,所以必须自己把这些细节处理掉。
在 LocalMnnEngine 里,会针对不同任务类型调整配置;在 JNI 层,会通过分步 generate(1) 和流式缓冲把内容逐步回传给 UI。对于移动端产品来说,这类“看起来只是体验问题”的细节,实际上会直接影响用户是否相信这个系统真的可用。
九、构建链路:从前端资源到 APK
除了推理和插件,工程闭环本身也很重要。
当前项目的构建链路大致如下:
npm run mobile:prepare
npm run mobile:sync
cd android
.gradlew.bat assembleDebug
这里的分工是:
-
mobile:prepare:把ui/资源整理到mobile-build/ -
mobile:sync:执行Capacitor同步并修补Android侧配置 -
assembleDebug:产出可安装APK
这件事的重要性在于:项目并不是停在某个本地网页页面,而是已经具备实际手机端工程闭环。能跑、能构建、能安装、能演示,和“架构思路正确”是两回事,后者不能替代前者。
十、这个项目里最重要的技术取舍
如果总结这个项目里最核心的工程取舍,我会概括成三条:
1. 不追求“全靠模型”
模型负责理解,规则和地图负责落地。这比让模型端到端拍脑袋更可靠。
2. 不追求“全原生页面”
高频变化的交互放在 Web 层,高价值能力放在原生层。这样更符合实际迭代效率。
3. 不追求“先做最大模型”
先让端侧链路跑通,再通过模型尺寸、任务拆分和重试修复去换稳定性,而不是一开始就把问题押给更大的模型。
十一、后续还能继续优化什么
如果继续往下做,我认为几个比较明确的方向是:
- 接入视觉模型,直接理解聊天截图和活动海报
- 做更细粒度的模型切换和设备性能适配
- 把路线评分继续扩展到夜间返程、安全性、天气惩罚等维度
- 优化本地缓存和模型安装管理
- 增强多人协作能力,比如投票、确认和共享结果
这些优化的核心不是“功能堆更多”,而是继续把“手机端 AI + 原生能力 + 真实场景闭环”这条线走深。
结语
做这个项目之后,我越来越觉得,移动端 AI 真正有价值的方向,不是把桌面端聊天体验原封不动搬到手机上,而是把 AI 嵌进那些本来就发生在手机上的真实决策里。
SyncMeet 只是其中一个例子。
它解决的是一个很具体的小问题:大家到底在哪见。
但工程上它覆盖了一条相对完整的链路:端侧模型接入、结构化输出、原生插件协作、路线决策和移动端产品闭环。
如果你也在做移动端 AI 应用,我觉得这里面最值得复用的,不是某一个具体页面,而是这几个思路:
- 模型只做它擅长的部分
- 强设备能力一定要原生化
- 规则系统不是倒退,而是落地手段
- 真正能跑起来的工程闭环,比单点能力更重要
© 版权声明
文章版权归作者所有,未经允许请勿转载。