【深度解析】Kafka生产者核心原理:从异步发送到数据可靠性保证
个人名片
🎓作者简介:java领域优质创作者
🌐个人主页:码农阿豪
📞工作室:新空间代码工作室(提供各种软件服务)
💌个人邮箱:[2435024119@qq.com]
📱个人微信:15279484656
🌐个人导航网站:www.forff.top
💡座右铭:总有人要赢。为什么不能是我呢?
- 专栏导航:
码农阿豪系列专栏导航
面试专栏:收集了java相关高频面试题,面试实战总结🍻🎉🖥️
Spring5系列专栏:整理了Spring5重要知识点与实战演练,有案例可直接使用🚀🔧💻
Redis专栏:Redis从零到一学习分享,经验总结,案例实战💐📝💡
全栈系列专栏:海纳百川有容乃大,可能你想要的东西里面都有🤸🌱🚀
目录
-
- 【深度解析】Kafka生产者核心原理:从异步发送到数据可靠性保证
-
- 一、Kafka生产者核心架构原理
- 二、消息发送模式:异步、回调异步与同步
-
- 1. 异步发送 (Fire-and-Forget)
- 2. 回调异步发送 (Asynchronous with Callback) – **最常用**
- 3. 同步发送 (Synchronous)
- 三、分区(Partition)与分区策略
-
- 1. 默认分区策略
- 2. 自定义分区器
- 四、调优与数据保证
-
- 1. 提高生产者吞吐量
- 2. 数据可靠(不丢失):ACK机制
- 3. 数据重复与幂等性(Idempotence)
- 4. 数据有序与乱序
- 五、面试QA
【深度解析】Kafka生产者核心原理:从异步发送到数据可靠性保证
在Kafka生态中,生产者(Producer)是将数据流注入Kafka集群的起点。它的设计直接决定了数据写入的吞吐量、延迟和可靠性。很多开发者只知其send()方法,却不知其背后精巧的架构与复杂的权衡。本文将深入Kafka生产者的内核,详解其工作原理、发送模式、分区策略以及如何保证数据可靠、有序和不重复,并辅以丰富的图解和Java代码案例。
一、Kafka生产者核心架构原理
首先,我们通过一张图来全局了解Kafka生产者的内部工作流程,它就像一座精心设计的“消息工厂”。
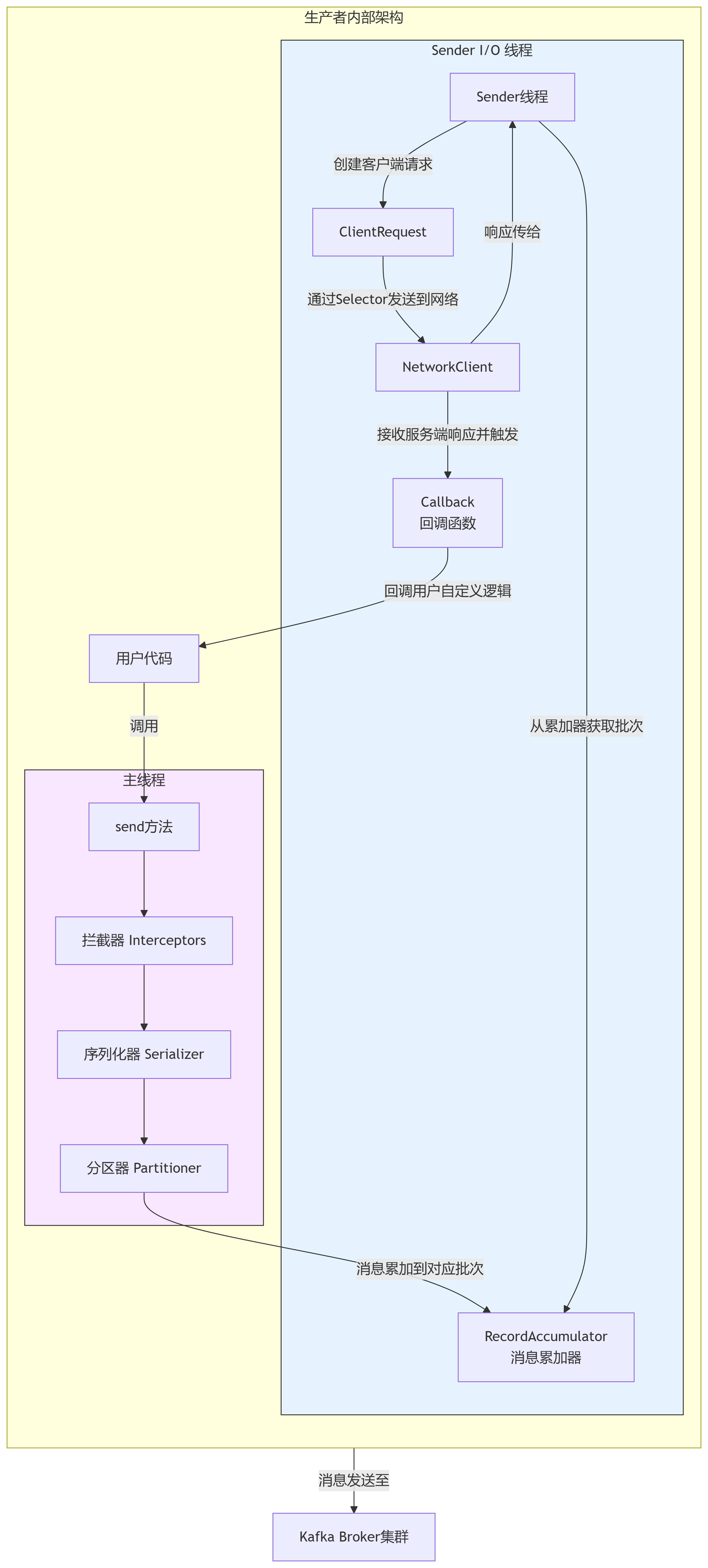
如图所示,生产者的工作流程涉及两个核心线程和多个关键组件:
-
主线程(用户线程):
- 拦截器(Interceptors):在消息发送前进行预处理(如添加时间戳、审计信息)。
-
序列化器(Serializer):将Java对象的Key和Value序列化为字节数组,以便网络传输。常用
StringSerializer,ByteArraySerializer,或自定义Avro/Protobuf序列化器。 - 分区器(Partitioner):决定消息应该被发送到Topic的哪个分区。这是实现负载均衡和顺序性的关键。
-
Sender线程(I/O线程):
- 消息累加器(RecordAccumulator):这是生产者的核心缓冲區。主线程发送的消息并不会立即被发出,而是被累加(Accumulate) 到对应主题分区的批次(Batch) 中。这种批处理是Kafka实现高吞吐量的关键。
-
Sender线程:一个后台I/O线程,负责从
RecordAccumulator中拉取已满的批次或等待时间过长的批次,将它们打包成ProducerRequest,并通过NetworkClient批量发送到Kafka集群。
这种“主线程-Sender线程”分离、批处理的设计,是Kafka生产者高吞吐量的根本原因。
二、消息发送模式:异步、回调异步与同步
1. 异步发送 (Fire-and-Forget)
只管发送,不关心是否成功。性能最高,但可靠性最差,可能丢失数据。
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");
producer.send(record); // 立即返回,不阻塞
producer.close();
2. 回调异步发送 (Asynchronous with Callback) – 最常用
发送后注册一个回调函数,消息成功或失败时会异步调用该回调。在性能和可靠性间取得了最佳平衡。
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("消息发送成功! Topic: " + metadata.topic() + ", Partition: " + metadata.partition());
} else {
System.err.println("消息发送失败: " + exception.getMessage());
// 此处可加入重试逻辑
}
}
});
// 主线程继续执行,不会被阻塞
3. 同步发送 (Synchronous)
调用send()后,立即调用get()方法阻塞当前线程,等待发送结果。性能最低,但可靠性最高。
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");
try {
// get() 方法会阻塞,直到收到服务端响应
RecordMetadata metadata = producer.send(record).get();
System.out.println("消息同步发送成功至分区: " + metadata.partition());
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace(); // 处理异常
}
三、分区(Partition)与分区策略
分区是Kafka实现水平扩展和并行处理的基础。生产者通过分区器决定消息的去向。
1. 默认分区策略
- 指定了Key:对Key进行哈希(默认murmur2Hash算法),然后对分区总数取模,得到目标分区号。这保证了相同Key的消息总是被路由到同一个分区,从而保证了分区内的顺序性。
- 未指定Key:使用“粘性分区(Sticky Partitioning)”策略。在批次填满或到期前,会随机选择一个分区并持续向其发送消息,而不是纯粹轮询。这减少了批次数量,提升了吞吐量。
2. 自定义分区器
你可以实现Partitioner接口,根据业务逻辑自定义分区策略。例如,根据某个业务ID的前缀进行分区。
public class MyCustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
// 自定义无Key时的策略
return 0; // 例如,总是发送到0号分区(不推荐)
}
String keyStr = (String) key;
// 示例:如果key以"important-"开头,则固定发送到最后一个分区
if (keyStr.startsWith("important-")) {
return numPartitions - 1;
}
// 否则,使用默认的哈希策略
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
@Override public void close() {}
@Override public void configure(Map<String, ?> configs) {}
}
// 在生产者配置中指定自定义分区器
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyCustomPartitioner.class.getName());
四、调优与数据保证
1. 提高生产者吞吐量
-
buffer.memory:增大消息缓冲区大小(默认32MB)。 -
batch.size:增大批次大小(默认16KB)。批次满后会立即发送,减少网络请求次数。 -
linger.ms:适当增大等待时间(默认0ms)。即使批次未满,等待一段时间后也会发送,增加批处理效果。 -
compression.type:启用压缩(snappy,lz4,gzip),减少网络IO。权衡:消耗CPU换取网络IO。
2. 数据可靠(不丢失):ACK机制
通过acks配置参数控制Leader副本确认请求的程度。
-
acks=0:生产者不等待任何确认。吞吐量最高,但可能丢失数据。 -
acks=1(默认):生产者等待Leader副本写入成功后就认为成功。在吞吐量和可靠性间平衡。如果Leader刚写入就宕机且数据未同步,仍可能丢失。 -
acks=all(或acks=-1):生产者等待Leader和所有ISR(In-Sync Replicas)副本都写入成功。最可靠,但延迟最高,吞吐量最低。
配置示例:
props.put(ProducerConfig.ACKS_CONFIG, "all"); // 最高可靠性
props.put(ProducerConfig.RETRIES_CONFIG, Integer.MAX_VALUE); // 无限重试
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true"); // 开启幂等性(见下文)
3. 数据重复与幂等性(Idempotence)
在acks=all和高重试配置下,可能因网络抖动导致生产者收不到确认而重复发送,引起数据重复。
解决方案:开启幂等性(enable.idempotence=true,默认自Kafka 2.4起为true)。Kafka会为每个生产者消息分配一个PID(Producer ID)和序列号(Sequence Number),Broker会据此对重复消息进行去重。
4. 数据有序与乱序
- 单分区内有序:Kafka保证单个分区内的消息是严格有序的。
-
可能乱序的场景:如果
max.in.flight.requests.per.connection(默认5)大于1且未开启幂等性,前一个请求失败重试时,后一个请求可能先成功,导致乱序。 -
保证严格有序:
- 设置
max.in.flight.requests.per.connection=1(性能差)。 -
更好的方式:开启幂等性。开启后,
max.in.flight.requests.per.connection可以设置为小于等于5(Broker端限制),Kafka能保证即使重试,消息也是按顺序写入的。
- 设置
五、面试QA
Q1: Kafka生产者如何实现高吞吐量的?
A: 主要通过三个机制:1) 批处理(Batching):消息先累积在内存批次中,由Sender线程批量发送,减少了网络IO次数。2) 缓冲区(RecordAccumulator):作为缓冲,平衡生产者和发送者的速率差。3) 异步I/O:主线程与Sender线程分离,主线程不会被网络IO阻塞。
Q2: 如何保证生产者发送的数据完全可靠(不丢失)?
A: 需要同时满足以下配置:1) 设置acks=all,确保所有ISR副本都确认。2) 设置retries为一个较大的值(或MAX_VALUE),应对瞬时故障。3) 对生产者本身做好异常捕获和处理。更进一步,可以在Broker端设置min.insync.replicas(最少ISR数)来保证写入的冗余度。
Q3: 如何保证全局有序?如何保证分区内有序?
A: 全局有序:将Topic设置为只有1个分区,但这会严重限制吞吐量,实践中极少使用。分区内有序:这是Kafka的默认保证。同时,为了避免重试引起的乱序,需要开启幂等性(enable.idempotence=true)或设置max.in.flight.requests.per.connection=1。
Q4: 发送消息时,分区是如何选择的?
A: 首先,如果消息指定了目标分区,则直接发送。其次,如果指定了Key,则根据Key的哈希值对分区数取模。最后,如果未指定Key,则使用“粘性分区”策略,随机选择一个分区并在一段时间内向其批量发送消息,以提升性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。