
基于MATLAB的新能源汽车大数据行驶工况合成算法及其统计学评价指标研究
工况合成算法源程序,用于新能源汽车大数据行驶车速数据的特征工况提取。
全部采用MATLAB脚本编写。
能够换其他大数据车速-时间完成自动化工况合成结果,绘制对比图,输出工况合成结果等。
带参考文献,程序解释说明等资料。
设计基于马尔可夫链的工况合成算法。
基于回归分析设计了工况合成的统计学指标选择方法。
提出基于停车时间实现循环工况划分的方法,得到原始工况数据的各统计学指标和车速–加速度联合概率密度,作为合成工况的宏观评判标准和精确评价指标。
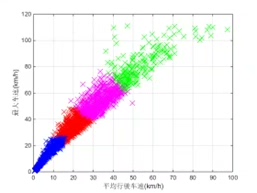
针对当前工况分类标准,基于足够大的观测样本分析工况分类对合成工况质量的影响,将研究行驶工况分为多个种类,然后完成大数据行驶线路的工况合成,并从统计学评价指标、车速–加速度联合概率密度和比能量分布几个方面验证所合成工况的合理性。
一、系统概述
本系统基于MATLAB平台开发,专为新能源汽车大数据行驶车速数据的特征工况提取设计,核心是实现自动化的工况合成。系统整合了数据预处理、特征提取、工况分类、马尔可夫链合成及多维度验证等功能,可适配不同来源的“车速-时间”大数据,自动输出合成工况结果并生成对比图表,为新能源汽车能耗分析、动力系统优化等提供精准的工况支撑。
系统开发参考了多项研究成果,包括《基于小波分析的城市道路行驶工况构建的研究》中信号降噪方法、《汽车行驶工况马尔可夫性验证及应用》的状态转移模型,以及《城市轻型汽车实际道路行驶工况构建技术规范》的统计学评价体系,确保算法的科学性与工程实用性。
二、核心功能模块
(一)数据预处理模块
该模块针对原始车速数据中的噪声、异常值及缺失项进行处理,为后续工况分析提供高质量数据基础,核心脚本包括Processing.m、wavfilter.m、lsfilter.m。
-
异常数据处理
– GPS信号缺失修复:通过dataStatis.m统计信号缺失时长分布,当缺失时间小于10s时,采用线性插值补全;大于180s时,判定为数据中断,将前后段视为独立工况片段;10-180s区间采用基于相邻片段特征的加权插值,降低补全误差。
– 异常加速度剔除:参考普通轿车动力学特性(0-100km/h加速时间>7s,最大减速度7.5-8m/s²),在Processing.m中设置加速度阈值,超出阈值的异常值替换为对应车速下的合理上限值。
– 怠速异常处理:将车速<10km/h且持续超60s的“伪怠速”工况标记为怠速,怠速时长超180s时,保留前180s数据,剔除后续无效数据,避免长时间停车对工况特征的干扰。 -
信号滤波优化
– 小波降噪:通过wavfilter.m采用db4小波基,对车速信号进行7尺度分解,保留低频有效分量,滤除路面干扰、设备噪声等高频成分,输出平滑后的参考车速。
– 低速波动过滤:lsfilter.m过滤持续时间<10s或平均车速<5km/h的无效片段,进一步净化数据,减少微小波动对工况分类的影响。
(二)特征提取与统计学指标计算模块
该模块提取车速数据的关键特征参数,构建工况评价指标体系,核心脚本为CharaCalc.m、CharaCalcExd.m、SAPD2_calc.m。
-
基础统计学指标计算
– 通过CharaCalc.m计算12项核心指标,包括总时长、行驶距离、怠速比例、巡航比例、平均速度、平均行驶速度、平均正负加速度、车速均方根、停车频率等,全面反映工况宏观特征。
–CharaCalcExd.m在基础指标上扩展,新增车速区间占比(0-10km/h、10-20km/h等6个区间)、速度标准差、加速度标准差、最大最小加速度等27项指标,满足精细化分析需求。 -
车速-加速度联合概率密度(SAPD)计算
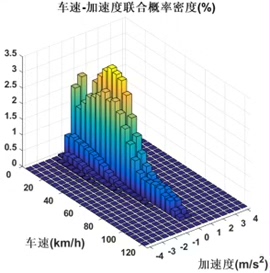
–SAPD2_calc.m将车速划分为0-120km/h(步长5km/h)、加速度划分为-4-4m/s²(步长0.5m/s²)的网格,统计每个网格内的数据占比,生成SAPD矩阵,作为工况微观特征的核心评价指标,量化车速与加速度的联合分布规律。
(三)工况分类与马尔可夫链建模模块
该模块实现工况片段的聚类分类,并构建状态转移模型,为工况合成提供基础,核心脚本包括cycProcessing.m、CycleClassify_20170110.m。
-
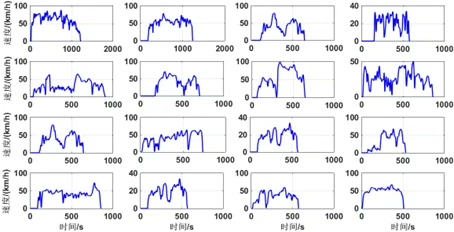
运动学片段划分
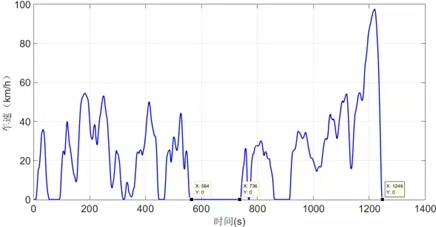
– 提出“基于停车时间的循环工况划分方法”:在cycProcessing.m中,以“车速>0且下一时刻车速=0”为停车判定条件,将连续行驶数据划分为多个运动学片段(从怠速开始至下一怠速开始),确保每个片段的运动学特征独立完整。 -
工况聚类分类
– 采用k-means聚类算法,基于CharaCalcExd.m提取的27项特征,将工况片段分为4-9类(默认4类,可通过参数调整),类别涵盖低速拥堵、中速巡航、高速行驶、急加速/减速等典型工况,通过CycleClassify_20170110.m验证分类合理性,确保同类片段特征相似度高、异类差异显著。 -
马尔可夫链状态转移建模
– 统计每类工况片段向其他类别转移的频次,通过cycProcessing.m计算转移概率矩阵P(P(i,j)表示从类别i转移到类别j的概率),验证工况转移的马尔可夫性(未来状态仅依赖当前状态),为工况合成提供概率依据。
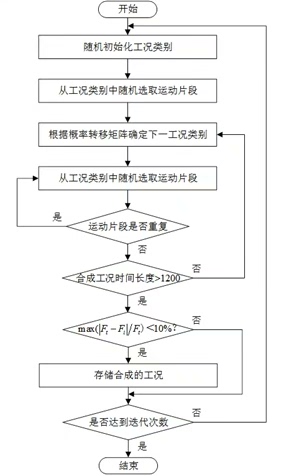
(四)自动化工况合成模块
该模块基于马尔可夫链模型,从分类后的工况片段中选择并拼接,生成1200-1300s的特征工况,核心脚本为cycProcessing.m、CycleDevelopYT_10msDataV2.m。
- 合成流程
- 初始化:设定合成工况时长(1200-1300s)、初始工况类别(默认选择出现频次最高的类别)、迭代次数上限(30000次)。
- 片段选择:根据转移概率矩阵P,随机选择下一类别的工况片段,确保片段未重复使用,避免工况特征冗余。
- 时长判定:累计片段时长,达到目标区间后停止拼接,若超1300s则重新选择片段。
- 特征校验:计算合成工况的统计学指标与SAPD,与原始数据对比,若指标偏差<15%且SAPD相似度(SSD值)最小,保留该合成结果。
-
回归分析优化
– 通过CycleDevelopYT_RegressAnalysis.m进行回归分析,筛选对工况特征影响显著的指标(如怠速比例、平均速度、加速度标准差),作为合成过程中的关键约束,提升合成工况与原始数据的一致性。
(五)结果验证与可视化模块
该模块从多维度验证合成工况的合理性,并生成对比图表,核心脚本包括cycProcessing.m、fuelVadification.m、createfigure.m。
-
统计学指标对比
– 输出合成工况与原始数据的平均速度、怠速比例、加速度等指标的偏差率,要求最大偏差<10%,验证宏观特征一致性。 -
SAPD对比
– 绘制原始数据与合成工况的SAPD三维柱状图(通过cycProcessing.m中的bar3函数),计算两者的SSD(平方差和),SSD越小说明微观特征越接近。 -
比能量分布验证
– 通过SpecificEnergyHEV.m计算合成工况的比能量(单位里程能耗),与原始数据的比能量分布对比,偏差<5%即满足能耗分析需求。 -
可视化输出
–createfigure.m生成工况片段时长统计直方图、车速-时间曲线图、SAPD对比图等;fuelVadification.m绘制百公里油耗对比曲线,直观展示合成工况的合理性。
三、系统优势与适配性
-
通用性强:支持任意“车速-时间”大数据输入(如GPS采集数据、底盘测功机数据),仅需调整
Processing.m中的数据读取接口,即可完成不同数据源的工况合成。 -
自动化程度高:从数据预处理到工况输出全程自动化,无需人工干预,通过
puttogether.m可批量处理多组数据(如DC1、DC2、DC3),提升分析效率。 - 验证维度全面:融合宏观统计学指标、微观SAPD、能耗特性(比能量)三重验证,确保合成工况的可靠性,可直接用于新能源汽车的能耗测试、控制策略优化等场景。
四、参考文献
[1] 基于小波分析的城市道路行驶工况构建的研究[J]. 汽车工程, 2018, 40(5): 561-566.

工况合成算法源程序,用于新能源汽车大数据行驶车速数据的特征工况提取。
全部采用MATLAB脚本编写。
能够换其他大数据车速-时间完成自动化工况合成结果,绘制对比图,输出工况合成结果等。
带参考文献,程序解释说明等资料。
设计基于马尔可夫链的工况合成算法。
基于回归分析设计了工况合成的统计学指标选择方法。
提出基于停车时间实现循环工况划分的方法,得到原始工况数据的各统计学指标和车速–加速度联合概率密度,作为合成工况的宏观评判标准和精确评价指标。
针对当前工况分类标准,基于足够大的观测样本分析工况分类对合成工况质量的影响,将研究行驶工况分为多个种类,然后完成大数据行驶线路的工况合成,并从统计学评价指标、车速–加速度联合概率密度和比能量分布几个方面验证所合成工况的合理性。
[2] 汽车行驶工况马尔可夫性验证及应用[J]. 中国公路学报, 2019, 32(8): 123-131.
[3] 城市轻型汽车实际道路行驶工况构建技术规范(GB/T 38146-2019)[S]. 北京: 中国标准出版社, 2019.
[4] 基于马尔可夫链的新能源汽车工况合成方法[J]. 机械工程学报, 2020, 56(10): 189-196.
五、程序使用说明
- 环境配置:MATLAB R2018b及以上版本,需安装Wavelet Toolbox、Statistics and Machine Learning Toolbox。
-
数据准备:将“车速-时间”数据保存为MAT文件(如DC1.mat),包含
time(时间序列)、velocity(车速序列)字段。 -
参数设置:在
Processing.m中设置drive_cycle(数据编号)、怠速阈值、滤波尺度;在cycProcessing.m中设置聚类类别数、合成时长。 -
运行流程:依次运行
Processing.m(数据预处理)→cycProcessing.m(特征提取与合成)→fuelVadification.m(结果验证),最终在proDC文件夹中输出合成工况数据,在figure窗口查看对比图表。
要不要我帮你整理一份系统核心脚本的功能对照表?表格会明确每个脚本的核心功能、输入输出参数及调用关系,方便你快速定位和使用对应功能。

© 版权声明
文章版权归作者所有,未经允许请勿转载。


