Java 大视界 — Java 大数据在智能政务数字身份认证与数据安全共享中的应用

Java 大视界 — Java 大数据在智能政务数字身份认证与数据安全共享中的应用
- 引言:
- 正文:
-
- 一、智能政务数字身份认证与数据安全共享概述
-
- 1.1 面临的挑战
- 1.2 Java 大数据技术的优势
- 二、Java 大数据在数字身份认证中的应用
-
- 2.1 多维度身份验证模型的构建
- 2.2 实时身份认证系统的实现
- 三、Java 大数据在数据安全共享中的应用
-
- 3.1 数据加密与解密技术
- 3.2 数据共享平台的搭建
- 四、实际案例分析
-
- 4.1 案例背景
- 4.2 解决方案实施
- 4.3 实施效果
- 结束语:
- 🗳️参与投票和联系我:
引言:
嘿,亲爱的 Java 和 大数据爱好者们,大家好!我是CSDN(全区域)四榜榜首青云交!在数字技术持续革新的时代,Java 大数据技术凭借其卓越性能与强大生态,在众多领域掀起了创新变革的浪潮。
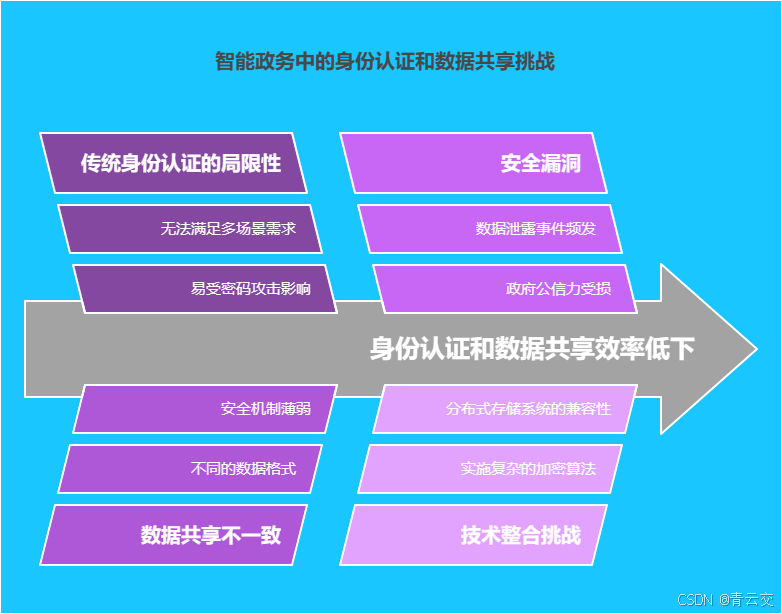
当下,数字化政务服务蓬勃发展,智能政务建设进入了高速发展阶段。然而,数字身份认证和数据安全共享领域存在的问题,严重制约了智能政务的进一步发展。传统身份认证方式,如用户名和密码认证,面临着暴力破解、信息泄露等安全风险。各政务部门之间数据相互独立,数据共享机制不完善,导致 “数据孤岛” 现象普遍存在。以企业开办为例,申请人需向工商、税务、银行等多个部门重复提交身份信息和企业资料,不仅增加了企业的办事成本,也降低了政务服务的整体效率。此外,数据在传输和存储过程中,容易被窃取、篡改,数据安全难以得到有效保障。
Java 大数据技术以其强大的数据处理能力、高效的存储机制和严密的安全体系,为解决这些难题提供了可靠的技术支撑。本文将深入探讨 Java 大数据在智能政务数字身份认证与数据安全共享中的应用,不仅从理论层面进行深入分析,还将结合丰富的实际案例与详实的代码示例,为读者提供全面、实用的技术指导。

正文:
一、智能政务数字身份认证与数据安全共享概述
1.1 面临的挑战
在智能政务的实际应用场景中,传统身份认证与数据共享模式的弊端愈发凸显。从身份认证方面来看,简单的用户名和密码认证方式,难以抵御日益复杂的网络攻击。据权威机构统计,每年因密码泄露导致的信息安全事件数以万计,给政府部门和公众带来了巨大的损失。同时,随着移动办公和远程服务的普及,传统认证方式无法满足多场景、多设备的认证需求。
在数据共享方面,各政务部门之间的数据格式不统一、标准不一致,导致数据难以整合和共享。例如,不同部门对企业登记信息的字段定义和数据格式存在差异,使得数据在共享过程中需要进行大量的转换和清洗工作。此外,数据共享过程中的安全机制不完善,数据泄露事件时有发生,严重损害了政府的公信力和公众的利益。
1.2 Java 大数据技术的优势
Java 大数据技术在智能政务领域具有显著的技术优势。通过大数据分析技术,可以对用户的行为数据进行实时采集和分析,构建用户行为画像,实现多维度的身份验证。例如,结合用户的登录时间、登录地点、使用设备、操作习惯等信息,建立动态的身份验证模型,提高认证的准确性和安全性。一旦发现异常行为,如异地登录、频繁错误登录等,系统立即触发预警机制,采取相应的安全措施。
在数据安全共享方面,Java 大数据技术提供了丰富的加密算法和安全协议,如 AES、RSA 等,确保数据在传输和存储过程中的安全性。同时,利用分布式存储技术,如 Hadoop 分布式文件系统(HDFS)和 HBase 分布式数据库,可以实现数据的多副本存储和冗余备份,提高数据的可靠性和可用性。此外,通过数据脱敏和访问控制技术,可以对敏感数据进行保护,确保只有授权用户才能访问和使用数据。
二、Java 大数据在数字身份认证中的应用
2.1 多维度身份验证模型的构建
基于 Java 的大数据分析框架 Spark,可以构建多维度身份验证模型。该模型通过对用户的身份信息、行为信息、设备信息等多个维度的数据进行分析,实现对用户身份的精准验证。下面以使用 Spark 框架进行用户行为分析为例,详细展示如何实现多维度身份验证。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class UserBehaviorAnalysis {
public static void main(String[] args) {
// 创建Spark配置对象,设置应用名称和运行模式
SparkConf conf = new SparkConf().setAppName("UserBehaviorAnalysis").setMaster("local[*]");
// 根据配置对象创建JavaSparkContext,它是Spark的入口
JavaSparkContext sc = new JavaSparkContext(conf);
// 模拟用户行为数据,每行数据包含用户名、登录时间和登录IP
List<String> data = Arrays.asList(
"user1,2024-01-01 09:00:00,192.168.1.100",
"user1,2024-01-01 09:10:00,192.168.1.100",
"user2,2024-01-01 10:00:00,192.168.1.101"
);
// 将数据并行化,创建JavaRDD
JavaRDD<String> rdd = sc.parallelize(data);
// 通过flatMapToPair操作将每行数据转换为键值对,键为用户名,值为(1, 登录IP)
JavaPairRDD<String, Tuple2<Integer, String>© 版权声明
文章版权归作者所有,未经允许请勿转载。