Kafka 与 Elasticsearch 的集成应用案例深度解析
一、引言
1、Kafka简介
Apache Kafka 是一个分布式的流处理平台,最初由 LinkedIn 开发并贡献给 Apache 软件基金会。它被设计用于高吞吐量、可扩展性和可靠性的分布式消息传递,广泛应用于大数据架构中。
Kafka 主要用于处理实时数据流,能够高效地从不同的数据源中获取数据,并将数据传递到多个目标系统。它支持大规模的消息发布和订阅,具有高可用性和容错性。

2、Elasticsearch简介
Elasticsearch 是一个基于 Lucene 的开源分布式搜索引擎,旨在提供快速、可靠、可扩展的全文搜索和分析能力。它是 Elastic Stack(也称为 ELK Stack)的核心组成部分,常与 Logstash(用于数据处理)和 Kibana(用于数据可视化)一起使用,构成完整的大数据处理和分析平台。
Elasticsearch 被广泛应用于日志分析、全文搜索、应用监控、业务数据分析等场景。它不仅支持文本数据的高效搜索,还可以进行实时的结构化和非结构化数据分析。

二、技术基础
1、Apache Kakfa简介
1.1 Kafka 的核心概念
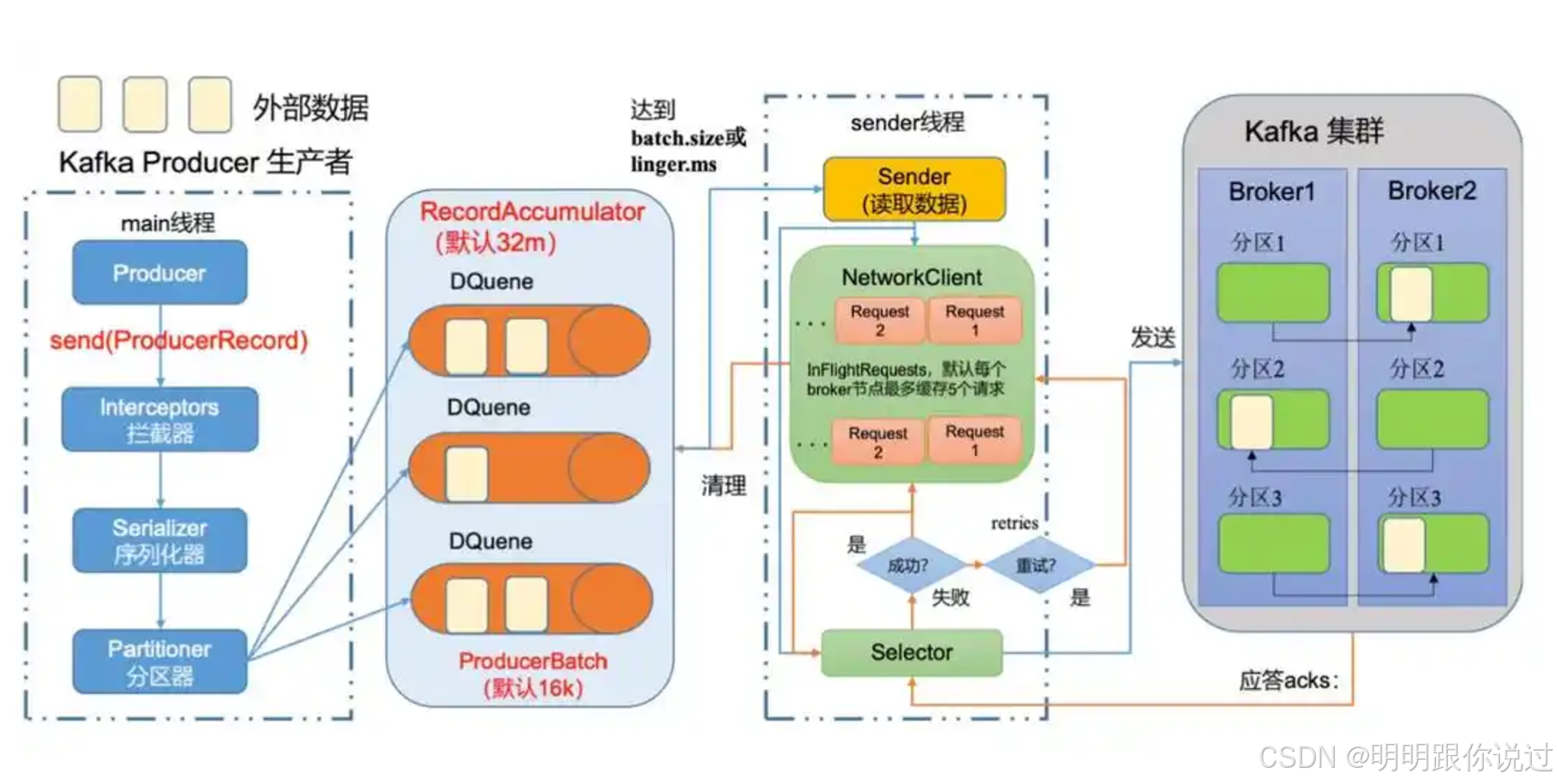
Producer(生产者)
- Producer 是生产数据的应用或系统,将消息发送到 Kafka 集群。
- 消息可以发布到一个或多个 topic(主题)中。
- Kafka Producer 是异步的,消息发布到 Kafka 后,Producer 可以继续执行其他操作。
Consumer(消费者)
- Consumer 是从 Kafka 集群读取数据的应用或系统。
- 消费者通常从一个或多个 topic 中读取数据。
- Kafka 支持多消费者消费同一个消息,消费者可以按组(Consumer Group)进行管理。
Broker(代理)
- Broker 是 Kafka 集群中的节点,负责存储消息并提供对外的访问服务。
- 每个 Kafka 集群由一个或多个 Broker 组成。
- Kafka 是高度可扩展的,多个 Broker 可以组成一个集群,共同处理大量的消息。
Topic(主题)
- Kafka 使用 topic 来组织消息。每个消息都会被写入一个 topic。
- 消费者可以订阅一个或多个 topic 来接收消息。
- 每个 topic 被分为多个 partition,每个 partition 可以分布在不同的 Kafka Broker 上,增加系统的并发处理能力和容错性。
Partition(分区)
- 每个 topic 可以被分成多个 partition,每个 partition 存储消息的一部分。
- 分区是 Kafka 的分布式特性,提供了消息并行处理的能力。
- 每个消息都会在一个 partition 中按顺序排列,并且每个 partition 可以有多个消费者并发读取。
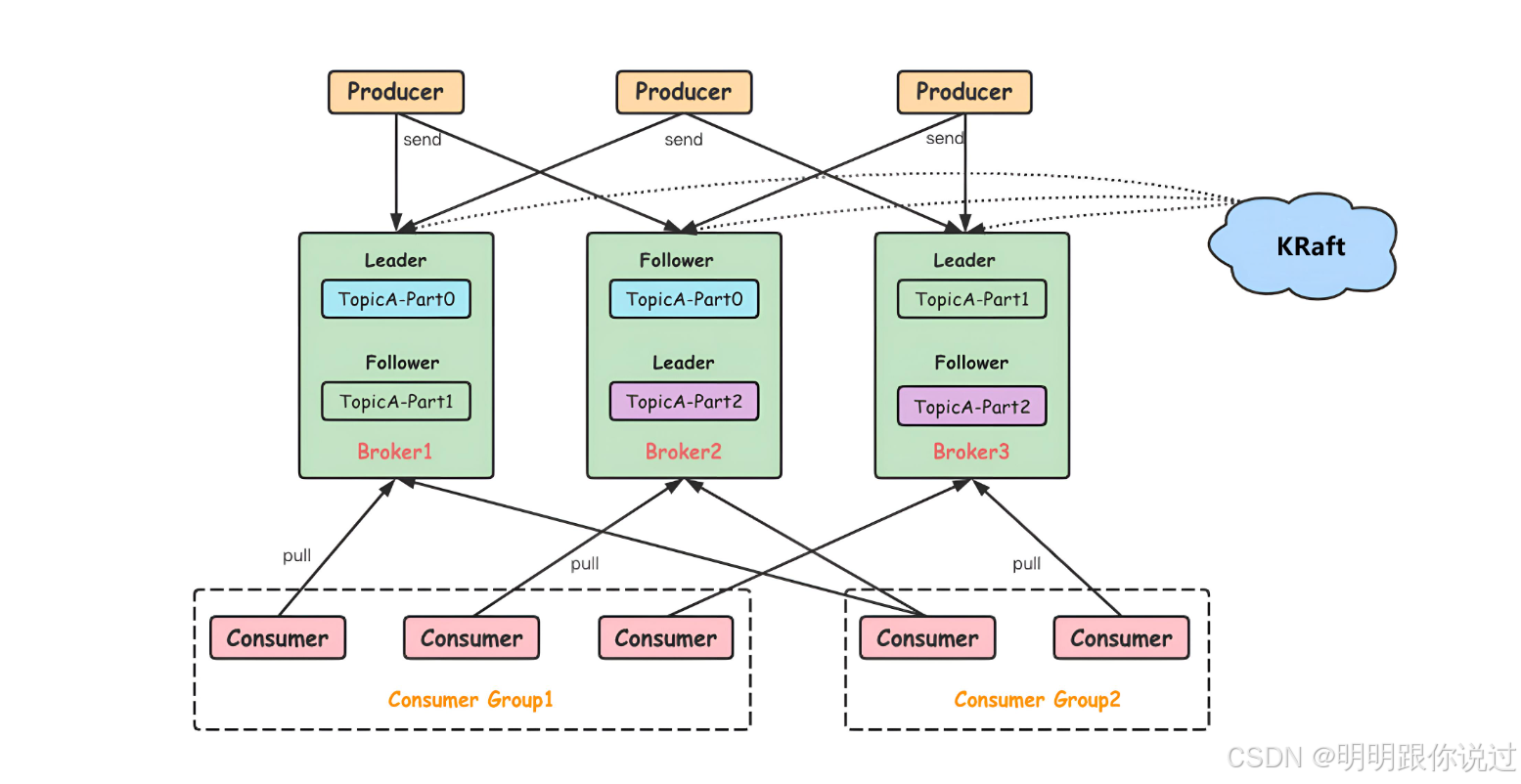
Consumer Group(消费者组)
- Kafka 通过 Consumer Group 来协调多个消费者的工作。每个消费者组内的消费者消费某个 topic 的不同 partition。
- 这样可以实现并发消费,提高数据处理效率。
- 如果同一个 Consumer Group 中有多个消费者,它们会共同消费该组下的所有 topic 分区,但每个分区只会被一个消费者读取。
Zookeeper(协调服务)
- Kafka 之前依赖 Zookeeper 来管理集群的元数据、配置信息、leader 选举等。
- Zookeeper 用于保持 Kafka 集群的状态和协调集群内的节点,确保 Kafka 系统的一致性和高可用性。
- Kafka 2.8.0 之后,Kafka 可以选择不使用 Zookeeper,逐步向 Kafka 自身的元数据管理系统迁移。
Producer-Consumer 模型
- Kafka 实现了 消息发布-订阅模型,即 Producer 生产消息到 Kafka,Consumer 从 Kafka 消费消息。
- 每个 Consumer 订阅一个或多个 topic,处理实时流式数据。
- 支持高吞吐量、低延迟的数据流传输。
1.2 Kafka 的特性
高吞吐量
- Kafka 通过高效的消息压缩、批量发送和顺序写入,能够处理数百万级别的消息传递。
- Kafka 适合用于高吞吐量的应用,如日志收集、实时数据分析等。
分布式架构
- Kafka 具有分布式架构,能够横向扩展。
- 消息可以在多个节点之间分布存储和传输,提供高可用性和容错性。
高可用性
- Kafka 提供数据副本机制,可以设置每个 partition 的副本数。
- 即使某些节点出现故障,系统仍然可以从其他副本节点恢复数据,保证系统的高可用性。
持久化存储
- Kafka 提供可靠的持久化机制,所有的消息都被写入磁盘进行持久化。
- 消息存储的时间由配置决定,可以通过配置文件设置消息在 Kafka 中保留的时间。
消息顺序性
- Kafka 确保同一个 partition 中的消息按顺序存储,并按照这个顺序提供给消费者。
- 这对于需要严格消息顺序的应用场景非常重要。
容错性
- Kafka 的每个 partition 可以设置多个副本,支持多副本机制来防止数据丢失。
- 在节点故障的情况下,Kafka 会自动从其他副本节点中恢复数据,确保系统不会出现单点故障。
1.3 Kafka 的应用场景
日志收集和监控
- Kafka 可以用来收集日志数据,并实时地将其传递到监控系统进行处理。
- 由于 Kafka 能处理高吞吐量的消息,它非常适合用于日志收集和大规模日志处理。
流处理和实时分析
- Kafka 与流处理框架(如 Apache Flink、Apache Spark)结合,能够实现对实时数据流的分析和处理。
- Kafka 提供强大的数据传输能力,而流处理框架则用于对数据进行实时计算和分析。
事件驱动架构
- Kafka 可以作为事件总线,支持面向事件的架构。它可以将事件数据流式传递给不同的消费者,使得各个系统之间解耦。
消息队列
- Kafka 作为消息队列,可以提供高可靠性、低延迟的消息传递服务,尤其在需要高并发的分布式系统中,Kafka 是一个理想的消息队列解决方案。
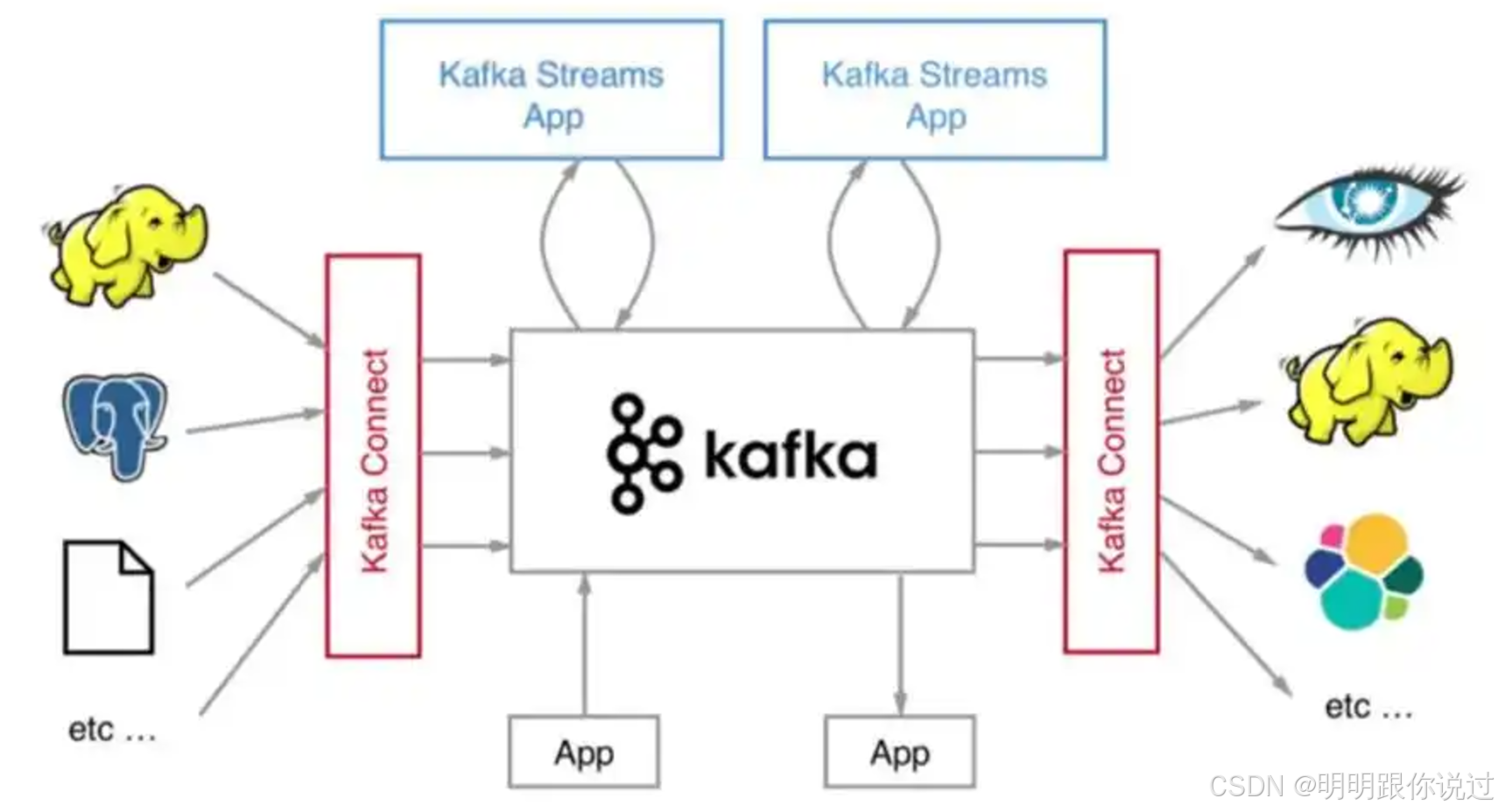
数据集成
- Kafka 作为数据流平台,能够在不同的数据源和目标系统之间提供流式数据的集成。
- 数据从多个生产者源流入 Kafka,然后被不同的消费者应用进行处理和存储。
2、Elasticsearch简介
2.1 Elasticsearch 的核心特性
全文搜索
- Elasticsearch 基于 Apache Lucene,能够提供强大的全文搜索功能。
- 支持 反向索引,允许对大量文本数据进行快速检索,支持复杂的查询、词法分析、分词等功能。
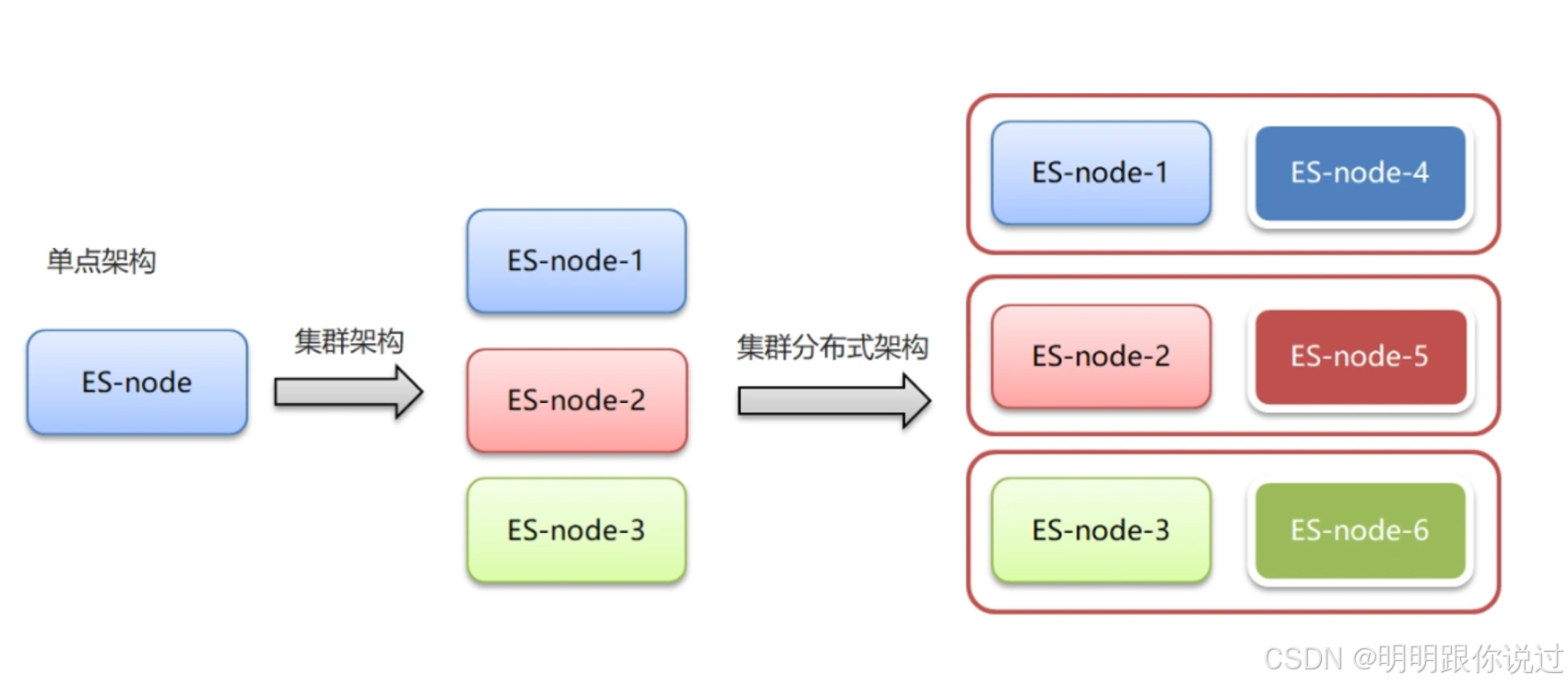
分布式架构
- Elasticsearch 是一个分布式系统,能够横向扩展以应对大规模数据存储和查询需求。
- 数据被分为多个 shard(分片),每个 shard 可以有多个副本 replica,这些分片和副本分布在集群中的不同节点上。
实时数据处理
- Elasticsearch 设计上具有低延迟,允许实时索引和查询数据。
- 数据在索引时几乎即时可查询,适用于需要快速响应和分析的大数据环境。
高可用性与容错性
- 由于采用了分布式架构,Elasticsearch 在集群中多个节点间复制数据,提供高可用性和容错性。
- 如果一个节点宕机,数据副本会确保数据不丢失,并能继续提供服务。
RESTful API
- Elasticsearch 提供了丰富的 RESTful API,通过 HTTP 请求与 Elasticsearch 进行交互。
- 用户可以通过简单的 JSON 格式的请求发送索引、查询、删除、更新等操作,易于与其他系统进行集成。
灵活的数据模型
- Elasticsearch 允许存储 结构化 和 非结构化 数据,包括 JSON 格式的数据。
- 每个数据记录被索引为文档(Document),文档按字段(Field)存储,支持多种数据类型,如文本、日期、数字、地理位置等。
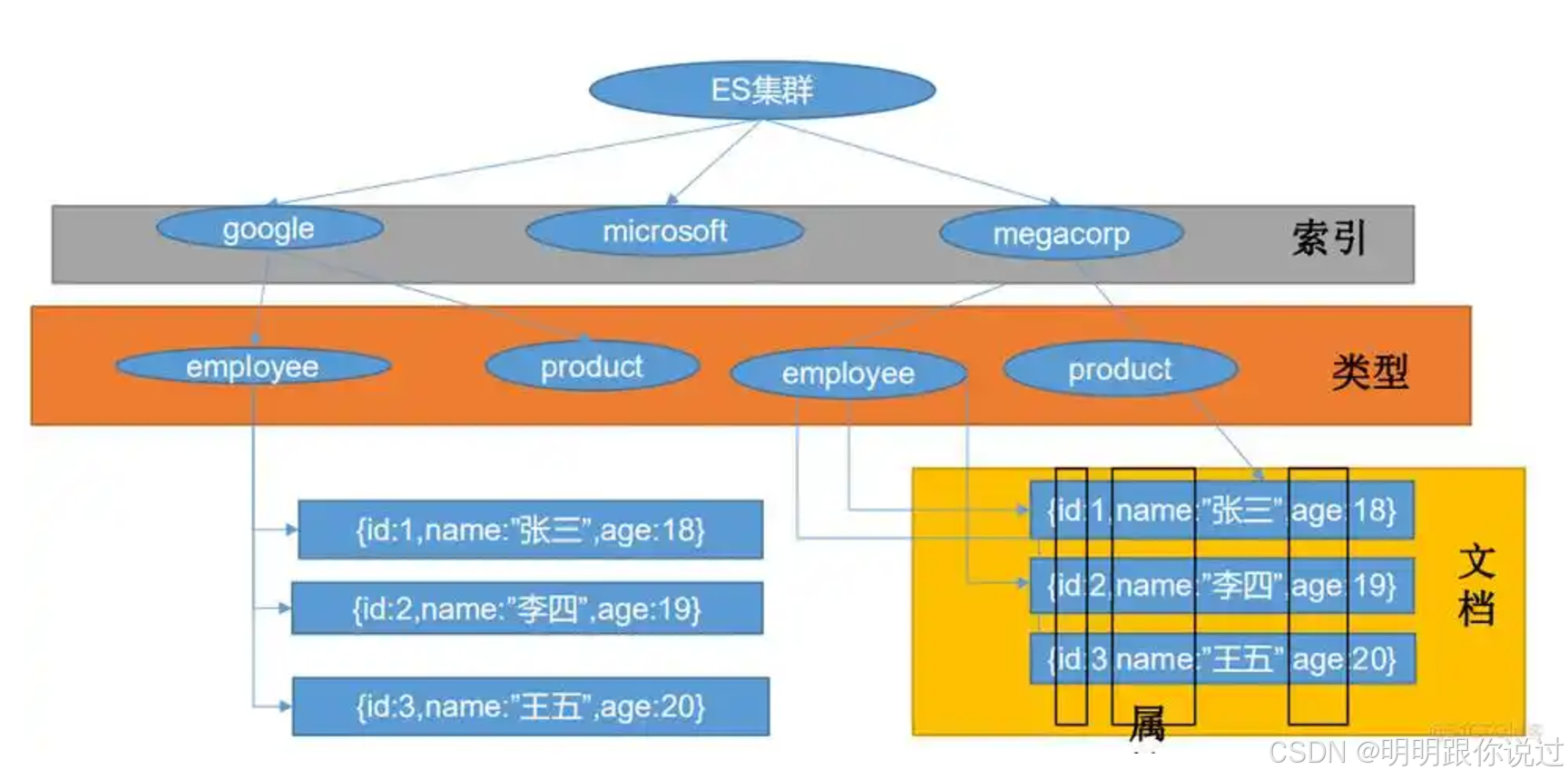
聚合功能
- Elasticsearch 支持强大的 聚合 功能,使得它可以处理统计分析、数据分组、计数、最大值、最小值等操作,适合做数据分析。
- 聚合查询可以对大量数据进行汇总和分析,帮助用户快速获得有用的信息。
水平扩展性
- Elasticsearch 能够通过增加节点和分片,进行水平扩展,处理更多的数据。
- 其分布式设计允许集群扩展,支持数PB级别的数据存储和处理。
全文搜索与分析能力
- Elasticsearch 提供强大的文本分析功能,支持 分词器、过滤器 等多种工具,用于文本数据的分析。
- 支持 高亮显示、布尔查询、通配符查询、模糊查询 等多种查询类型,满足不同业务需求。
支持多种数据源
- Elasticsearch 可以从不同的来源(如日志文件、数据库、消息队列等)实时获取数据进行索引。
- 通常与 Logstash 和 Beats 配合使用,能够对数据进行提取、处理和传输,适用于日志分析、监控等场景。

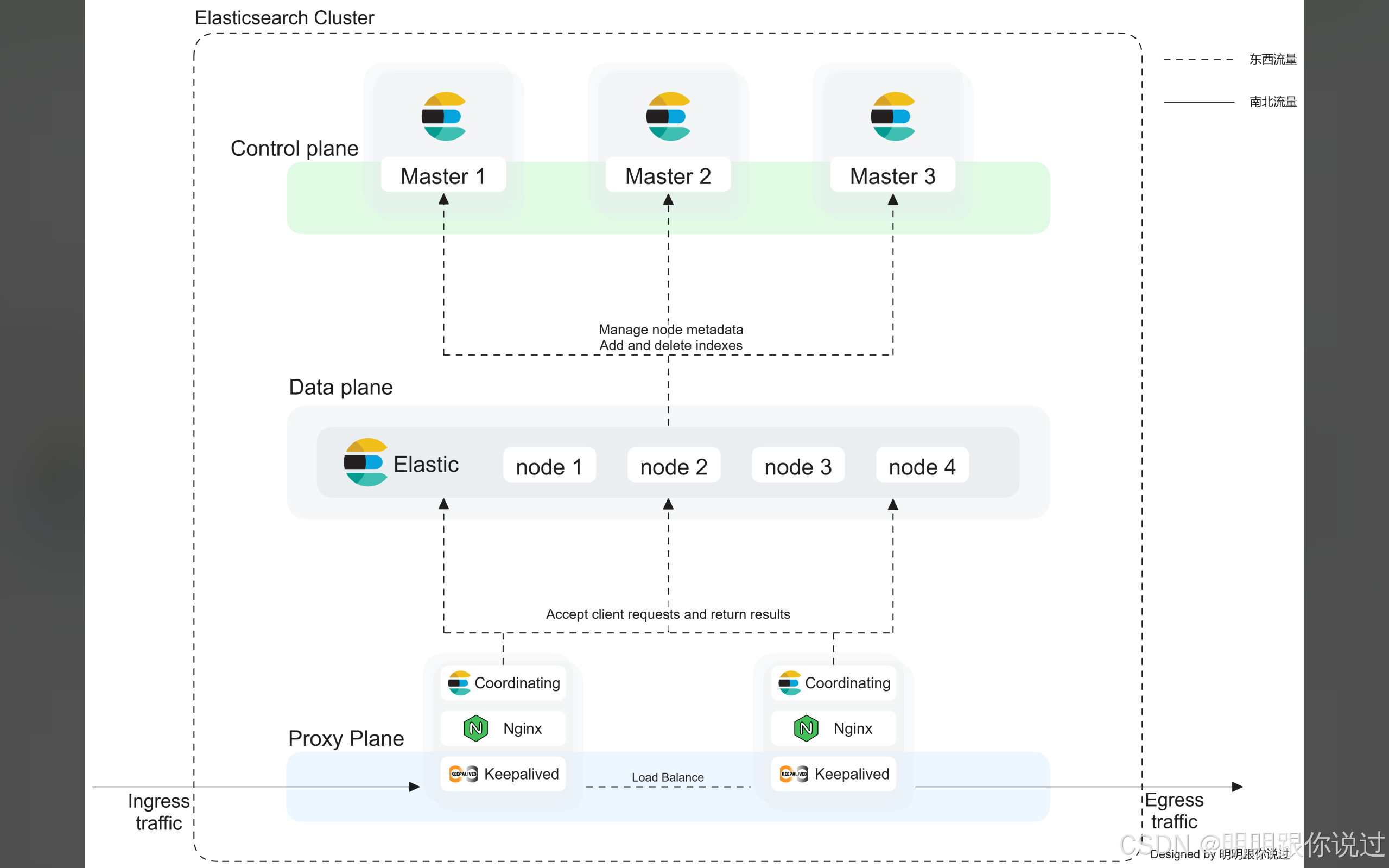
2.2 Elasticsearch 的架构组件
节点(Node)
- 一个 Elasticsearch 节点 是一个运行 Elasticsearch 服务的实例。
- 每个节点都是集群的一部分,可以单独运行,也可以是集群中的一个工作节点。
集群(Cluster)
- 一个 集群 是由一个或多个 Elasticsearch 节点组成的集合。
- 集群中的节点通过网络连接,协同工作以提供索引和搜索服务。
- 每个集群都有一个唯一的名字,一个集群可以包含多个节点,支持横向扩展。
分片(Shard)
- Sharding 是 Elasticsearch 的分布式设计的核心概念。
- 每个索引被分成多个 primary shard(主分片),这些分片存储实际的数据。
- 分片是 Elasticsearch 存储和查询的基本单位。
副本(Replica)
- Replica 是分片的副本,用于提供数据冗余和提高查询性能。
- 每个分片可以有一个或多个副本,副本存储在集群中的不同节点上。
- 副本的作用是提高容错性和并发查询性能。
索引(Index)
- 一个 索引 是对一类数据的逻辑划分,用于存储和组织文档数据。
- 在 Elasticsearch 中,索引类似于关系型数据库中的数据库。
- 每个索引包含多个文档,文档通过字段进行组织。
2.3 Elasticsearch 的使用场景
日志分析
- Elasticsearch 在日志收集、存储和分析方面有广泛应用。通过与 Logstash 和 Kibana 配合使用,可以构建一个强大的日志处理平台(ELK Stack)。
- 适用于实时日志分析、故障排除、应用性能监控等场景。
全文搜索引擎
- Elasticsearch 提供高效的全文搜索能力,适用于网站、应用程序中的搜索功能。
- 支持多语言的全文搜索、模糊搜索、建议搜索等复杂的查询需求。
实时数据分析
- Elasticsearch 支持高效的实时数据查询和分析,可以实时处理和展示数据。
- 适合用于社交媒体、金融、电商等行业的实时数据分析需求。
数据可视化
- 通过与 Kibana 配合,Elasticsearch 能够将数据可视化,生成图表、仪表盘等,帮助用户理解数据。
- 在 数据监控、业务分析 等场景下非常有用。
推荐系统
- Elasticsearch 的高效查询和聚合能力,适用于实现商品推荐、广告推荐等基于内容的推荐系统。
地理位置查询
- Elasticsearch 支持地理位置数据存储与查询,可以用于地理位置相关的应用,如商店位置查询、路径分析等。
三、Kafka与Elasticsearch集成原理
1、集成需求分析
日志或信息等数据以消息形式存于kafka中,需要将kafka中的消息发送到elasticsearch中,以便于存储和检索,Kafka作为elasticsearch的前置代理,还可以作为缓冲和消峰,避免较大的访问和写入造成elasticsearch的繁忙和阻塞
2、集成方式概述
本次实验以将Kafka中的消息发送到elasticsearch中为目的,使用 logstash 作为中间传输介质,logstash 本身并不存储数据,只是作为中间传输的媒介
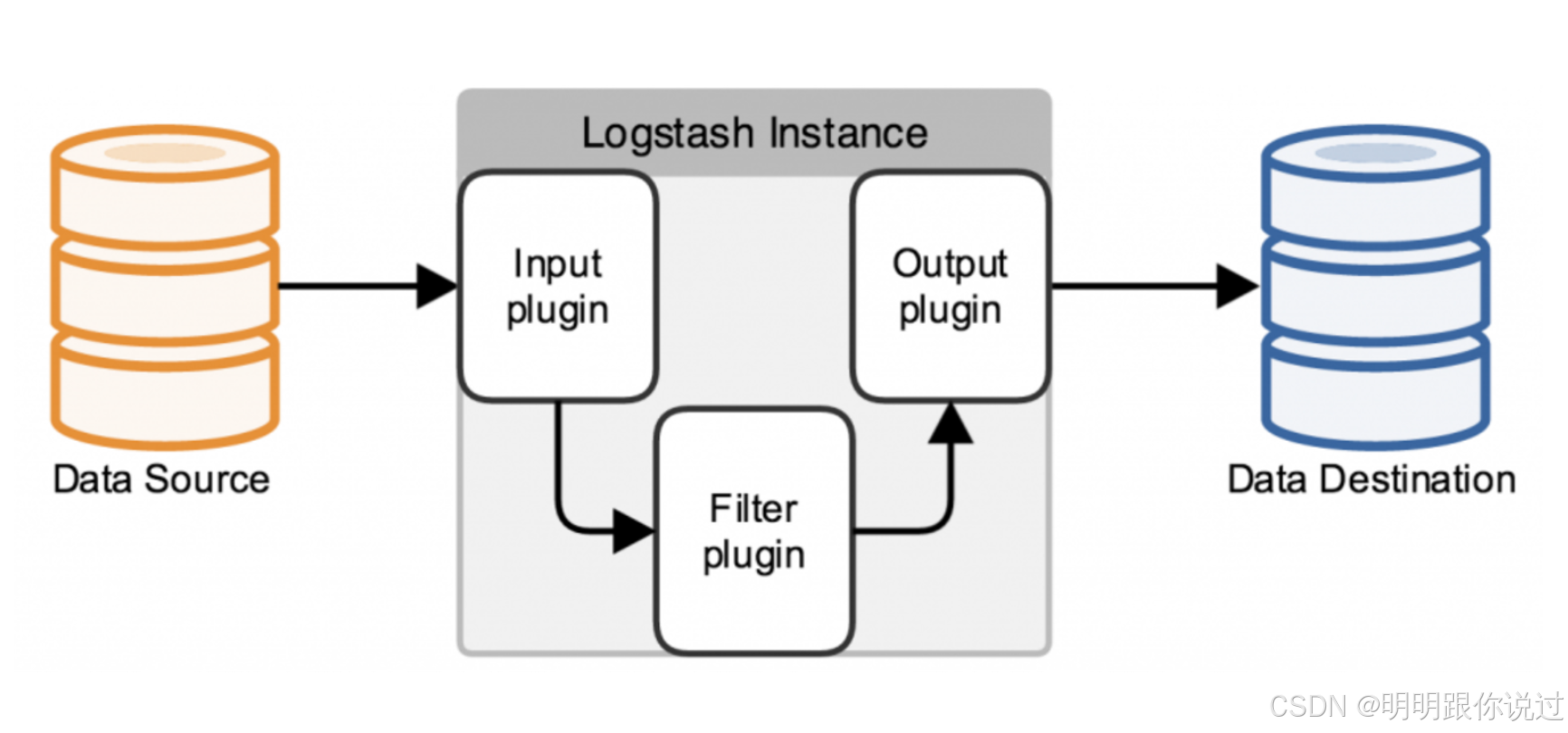
具体的传输流程类似于下面这样:
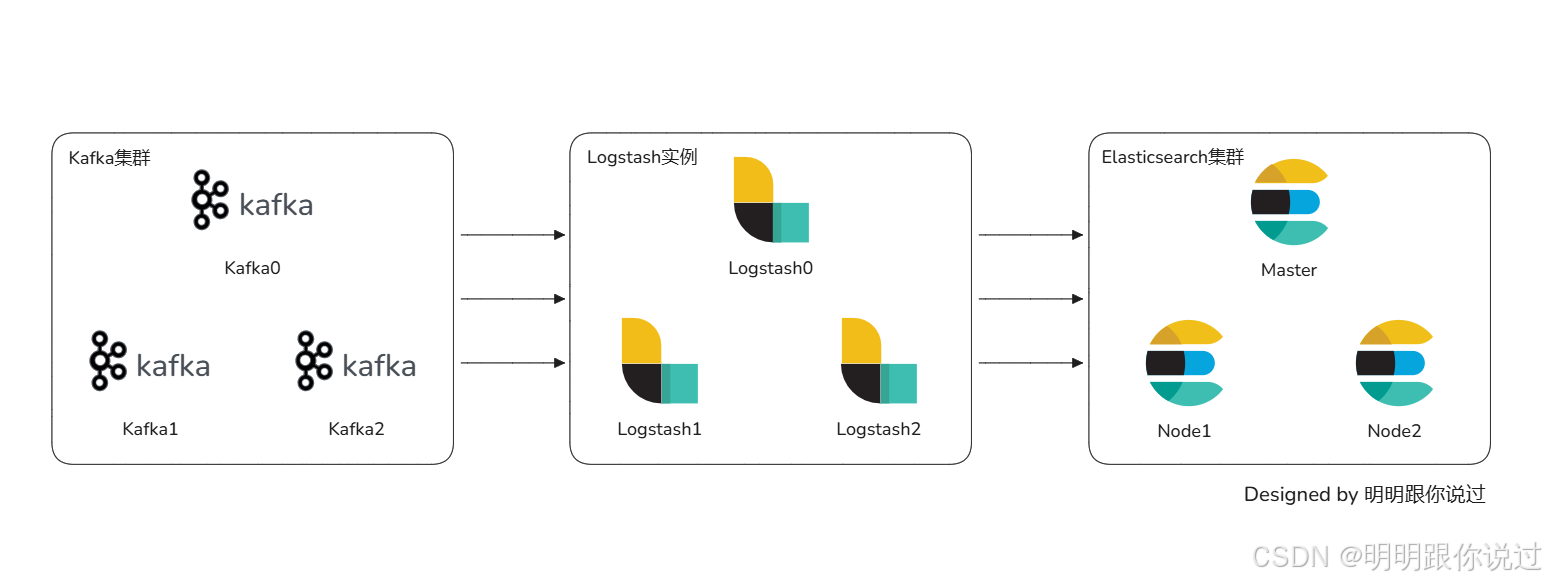
3、数据流动过程详解
1. 数据采集(Input):
- Logstash 使用 Kafka 输入插件 连接到 Kafka 集群,订阅特定的 Kafka 主题(topic)。
- Kafka 输入插件不断从 Kafka 主题中获取消息,这些消息通常是 JSON 格式或者日志格式的数据。
2. 数据处理(Filter)(可选):
- 在接收到 Kafka 中的数据后,Logstash 会通过 过滤器插件 对数据进行处理。这些操作可以是解析、转换、格式化或者添加额外的信息。
- 过滤器插件将原始数据转换为符合预期格式的数据。例如,通过 grok 插件解析复杂的日志格式,或者使用 mutate 插件更改字段名称。
3. 数据输出(Output):
- 在数据经过处理后,Logstash 使用 Elasticsearch 输出插件 将数据发送到 Elasticsearch。
- 这个过程包括将数据索引到特定的 Elasticsearch 索引中。通常根据时间(如 logstash-%{+YYYY.MM.dd})为数据指定动态索引,以便实现按时间分割的索引策略。
- Elasticsearch 将接收的数据存储到相应的索引中,利用其强大的搜索和分析功能提供实时查询能力。
四、案例实施步骤
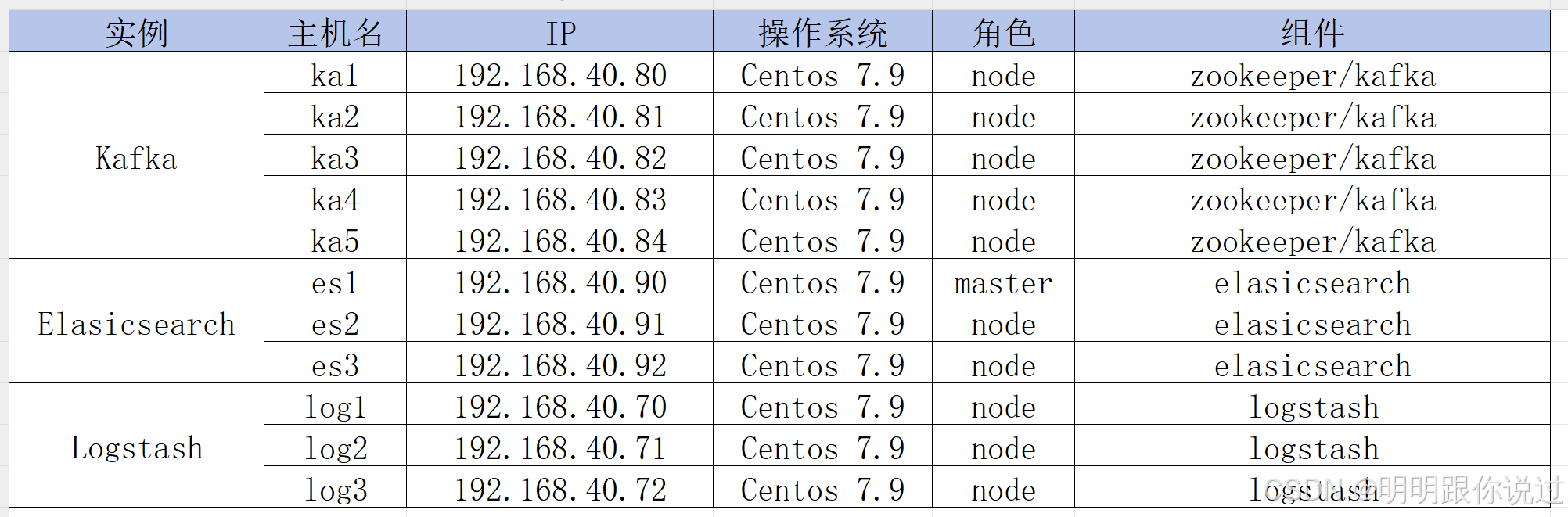
1、资源准备
1.1 服务器准备
1.2 Elasticsearch集群搭建
本次搭建使用的版本为elasticsearch-7.17.18-1.x86_64,如果还未搭建Elasticsearch集群,请参考
《CentOS上Elasticsearch安装全攻略:YUM、二进制与Docker任选》这篇文章
1.3 Kafka集群搭建
笔者使用的版本为kafka_2.13-3.1.0,集群搭建参考《Linux平台Kafka高可用集群部署全攻略》这篇文章
1.4 Logstash资源包准备
下载Logstash资源包并上传至三台服务器上,下载地址: Past Releases of Elastic Stack Software | Elastic
2、Logstash资源配置
登录到logstash服务器,下面的操作在3台上面都要执行,如果只有一台logstash服务器也是可以的,这里我们搭建的是高可用的logstash,避免单点故障
解压压缩包
tar zxvf logstash-7.17.18-linux-x86_64.tar.gz -C /opt编辑配置文件
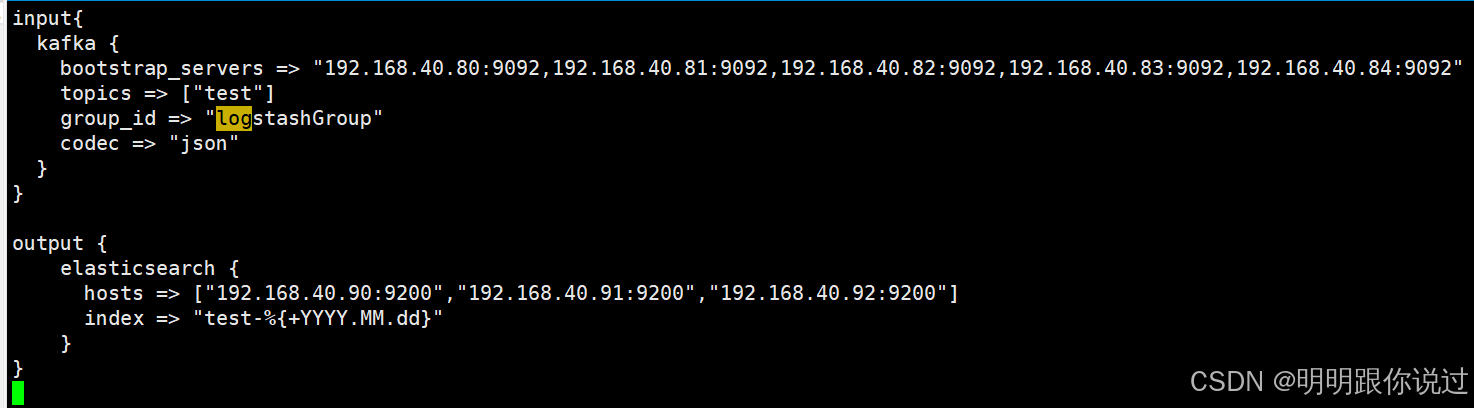
vim /opt/logstash/config/test.conf添加如下内容
input{
kafka {
bootstrap_servers => "192.168.40.80:9092,192.168.40.81:9092,192.168.40.82:9092,192.168.40.83:9092,192.168.40.84:9092"
topics => ["test"]
group_id => "logstashGroup"
codec => "json"
}
}output {
elasticsearch {
hosts => ["192.168.40.90:9200","192.168.40.91:9200","192.168.40.92:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
输入插件(Kafka 输入)
- bootstrap_servers: 定义了 Kafka 集群中可用的 Kafka 节点的 IP 地址和端口(9092 是 Kafka 默认端口)。这里列出了多个 Kafka 节点,用于保证连接的高可用性。
- topics: 指定了 Kafka 中要读取的主题(topic),这里是 test 主题。Logstash 会从这个主题中获取消息。
- group_id: 定义 Kafka 消费者组的 ID。Logstash 作为 Kafka 消费者参与数据的读取,并且每个消费者都属于一个消费者组。
- codec: 设置消息的解码方式,json 表示消息是 JSON 格式,Logstash 会自动解析消息体中的 JSON 格式数据。
输出插件(Elasticsearch 输出)
- hosts: 指定 Elasticsearch 集群的地址列表。这里列出了三个 Elasticsearch 节点的地址,9200 是 Elasticsearch 默认的端口。Logstash 将把处理后的数据发送到这些 Elasticsearch 节点。
- index: 指定 Elasticsearch 中的数据存储的索引名。这里使用了时间格式化(%{+YYYY.MM.dd}),意味着 Logstash 会每天创建一个新的索引,名称类似 test-2024.11.20(具体日期根据事件的时间生成)。这种按日期分割索引的策略有助于管理和查询大量数据。
修改 hosts
vim /etc/hosts添加如下内容
192.168.40.80 ka1
192.168.40.81 ka2
192.168.40.82 ka3
192.168.40.83 ka4
192.168.40.84 ka5
192.168.40.90 es1
192.168.40.91 es2
192.168.40.92 es3
3、启动logstash
cd /opt/logstash/bin/
./logstash -f /opt/logstash/config/test.conf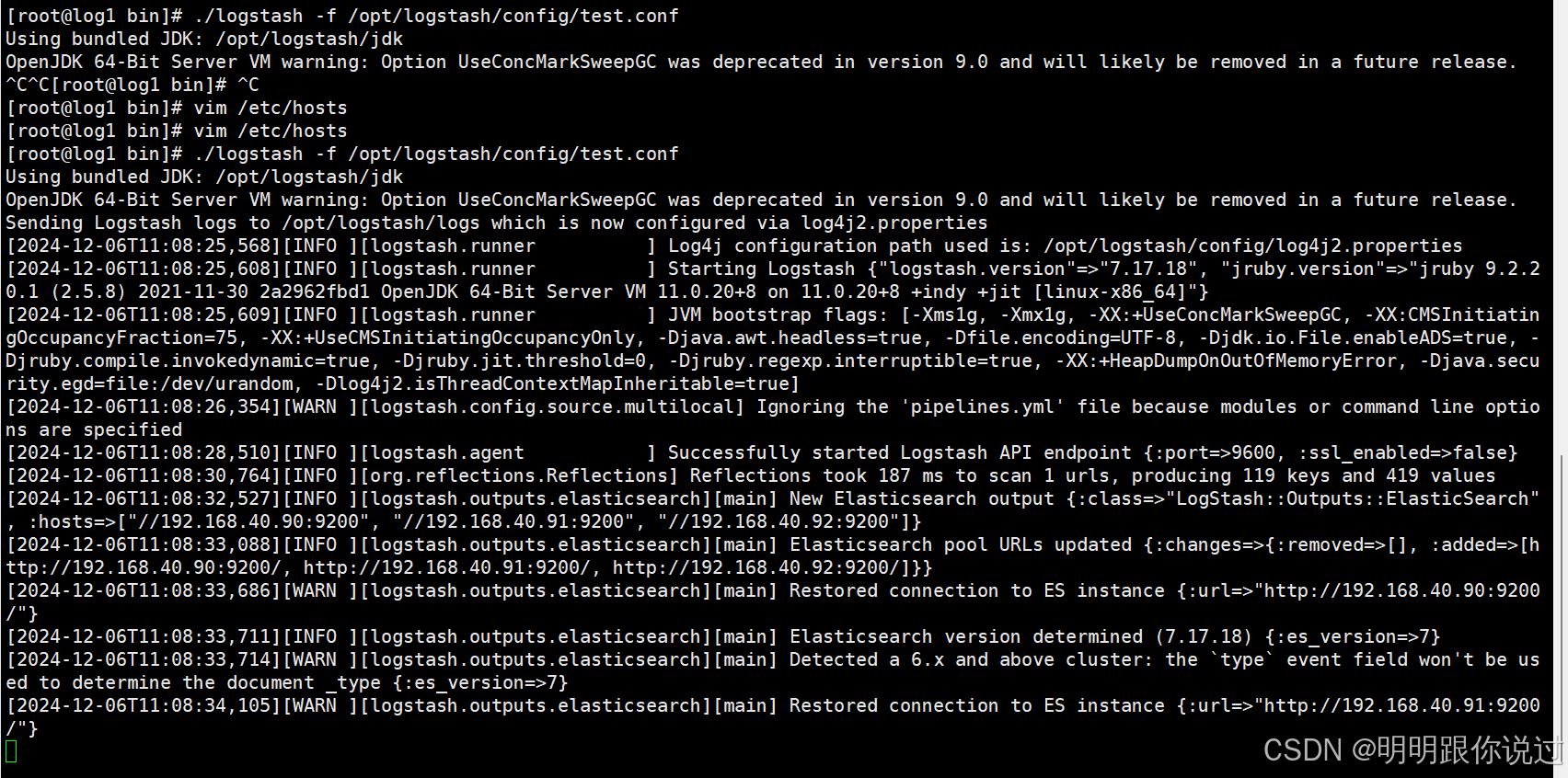
如果想要后台执行,可以使用:
nohup ./logstash -f /opt/logstash/config/test.conf &4、验证测试
4.1 生产日志
登录到Kafka任一一台服务器,执行下面的命令,生产几条测试日志
[root@ka1 bin]# cd /root/kafka_2.13-3.1.0/bin/
[root@ka1 bin]# ./kafka-console-producer.sh --bootstrap-server=192.168.40.80:9092 --topic test随便写入几条日志
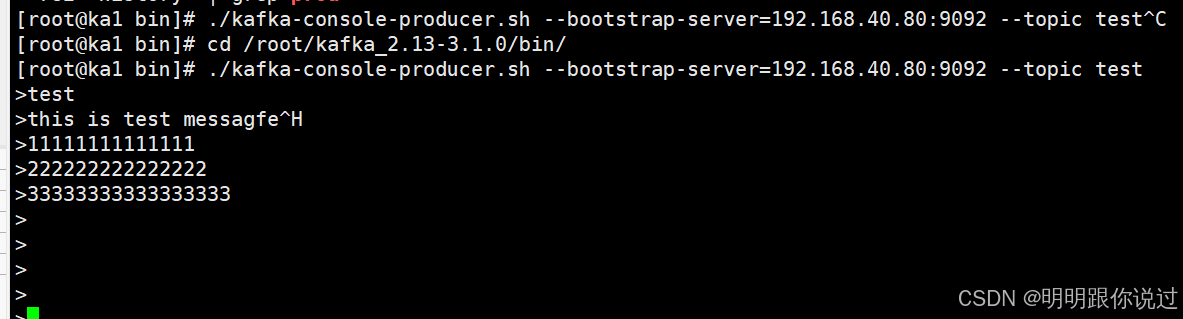
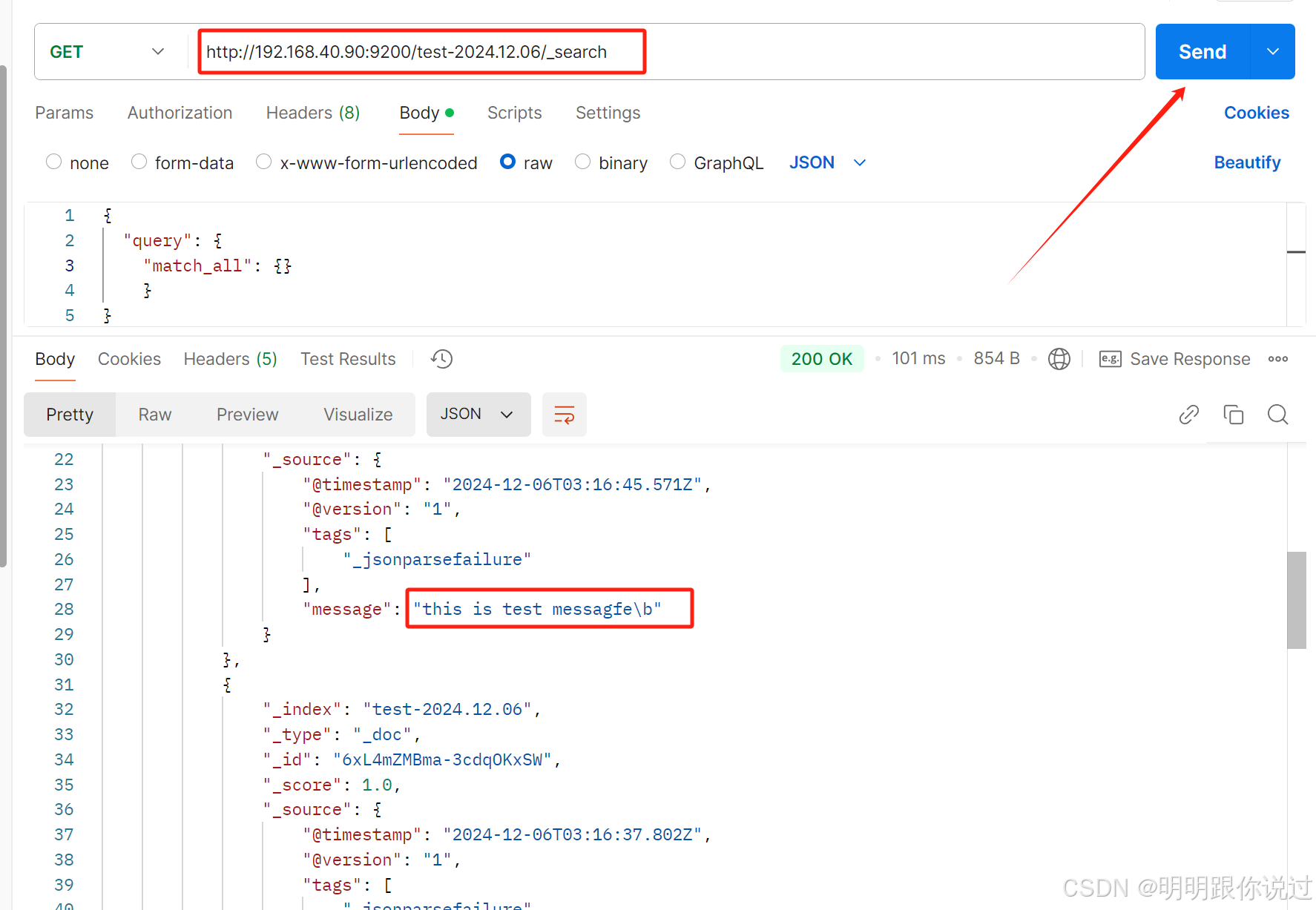
4.2 消费日志
打开postman,发送请求,如果可以获取到,证明使用logstash从kafka中获取日志并发送到elasticsearch中成功
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些关于大数据的文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
© 版权声明
文章版权归作者所有,未经允许请勿转载。