
Z-Image LoRA 训练整合包及使用教程:使用ai-toolkit的最全面的 z-image-turbo lora训练实战教程
Z-Image LoRA 训练整合包及使用教程:使用ai-toolkit的最全面的 z-image-turbo lora训练实战教程
Z-Image LoRA训练 z-image-turbo 微调教程 AI绘画 模型微调 训练器部署 数据标注
这篇文章从头到尾、手把手带你完成一套真正能用的 Z-Image LoRA(以 z-image-turbo 为基础)训练流程。文章按实操步骤拆成十部分,内容尽量贴近日常操作和命令,让你能一步步复刻。

👇️👇️教程所需的z-image lora训练整合包下载
z-image lora整合包下载地址
https://pan.quark.cn/s/c3da18507004
目录
- 概览与准备
- 训练集准备(图片来源与数量)
- 标注(生成训练提示词)
- 训练器选择与本地部署(lto-kate / l2t / toolket)
- 上传训练集到训练器并创建数据集
- 训练器参数设置(关键参数详解)
- 测试提示词编写与每250步测试策略
- 启动训练与监控(中断/恢复/日志)
- 导出/部署 LoRA 到 Z-Image 工作流测试
- 常见问题与优化建议
最后:结论与延伸阅读
1. 概览与准备
本次实战以 z-image-turbo(俗称 Image Turbo)为底模进行 LoRA 微调,目标是训练出“角色一致性好、细节稳定、泛化能力强”的 LoRA 模型,最终在 Z-Image 工作流中跑图验证效果。
- 要求环境:有一台支持 GPU 的机器(NVIDIA),显存 12–24GB 可用;若显存 12–16GB,开启 low_vram/优化选项。
- 建议工具:训练器(本文示范使用开源工具包作者 ostrich 的 ai-toolkit 一键包),本地浏览器用于 UI 操作,Python 虚拟环境已打包。
- 数据规模:15–30 张图片(单角色 IP 推荐 15 张即可);训练步数 2500–3000 步常用,节省时间可 2500 步试验。
2. 训练集准备(图片选择策略)
目标:保证角度、表情、服装和光线的多样性,同时维持角色一致性。
建议:
- 图片数量:15–30(演示用 15 张节省时间)
- 类型:正面、侧面、背面、45°、俯视、仰视、不同动作、近景、半身、全身
- 分辨率:建议 1024×1024 或 768×1024,根据底模和训练器要求调整
- 文件命名:
0001.jpg、0002.jpg… 与对应标签文件名一一对应(很重要)
文件夹结构示例:
/datasets/furilian/
images/
0001.jpg
0002.jpg
...
txts/
0001.txt
0002.txt
...
3. 标注(用大语言模型自动生成提示词)

我推荐把图片拖到大语言模型(如 claude、ChatGPT、Bard 等)会话中,让其按统一规则为每张图片生成一条训练用的提示词(txt),格式尽量简洁且包含以下信息:
- 角色代号(例如:
<lora:furilian:0.8>在最终测试时可手动添加) - 角色描述(发色、眼色、耳朵、种族/特征)
- 服装、配件
- 动作/姿态
- 画风或绘画风格(可选)
- 负面提示(可放在单独文件或统一管理)
示例(0001.txt):
白发精灵 Furilian, long white hair, blue-green eyes, pointed ears, elf, wearing ornate blue-white robe, standing three-quarter view, soft cinematic lighting, intricate embroidery, high detail, sharp focus
操作流程(我常用的快捷法):
- 在会话里一次性拖入所有图片(或分批)。
- 指令示例:
帮我为这些图片生成训练用的 prompt,每张输出一个 .txt 内容,格式保持简洁,包含角色特征、服装和姿势。最后把所有 txt 打包成 zip 供下载。 - 下载后解压,将 txt 放回对应 images 文件夹,保证文件名一一对应。
提示:如果训练器支持反推 prompt(很多训练器可以),可以省略这步。但为了角色一致性、我强烈建议提前生成并校对每条 prompt。
4. 训练器选择与本地部署
本文使用开源训练器ai-toolkit打包。你也可以使用其他训练器(如 LoRA Trainer、DreamBooth-variant 等),但 UI 步骤类似。
安装教程参考:Z-image LoRA 训练整合包下载与使用教程(详细图文教程)
5. 上传训练集到训练器并创建数据集
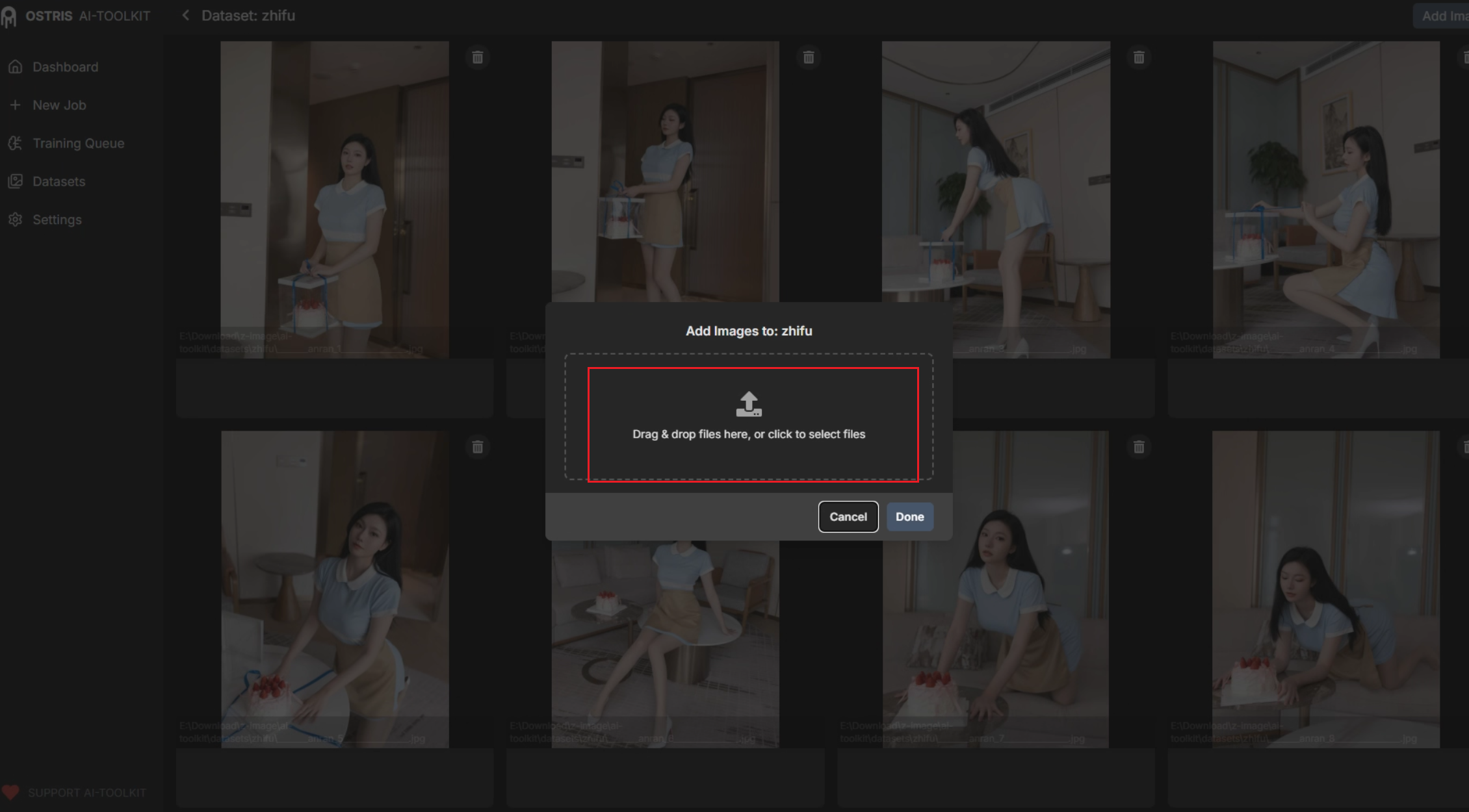
在训练器 UI:
- 点击 “训练集” ->
New Data Set-> 输入名称(示例:furilian_dataset)。 - 拖入
images/和txts/(或已将 txt 命名为和图片一致的方式)。 - 确认图片与txt一一对应,UI 通常会显示文件对齐结果。
出现问题时:
- 若提示词和图片未匹配,说明文件名或格式不一致,按命名规范调整后重试。
6. 训练器参数设置(关键参数详解)
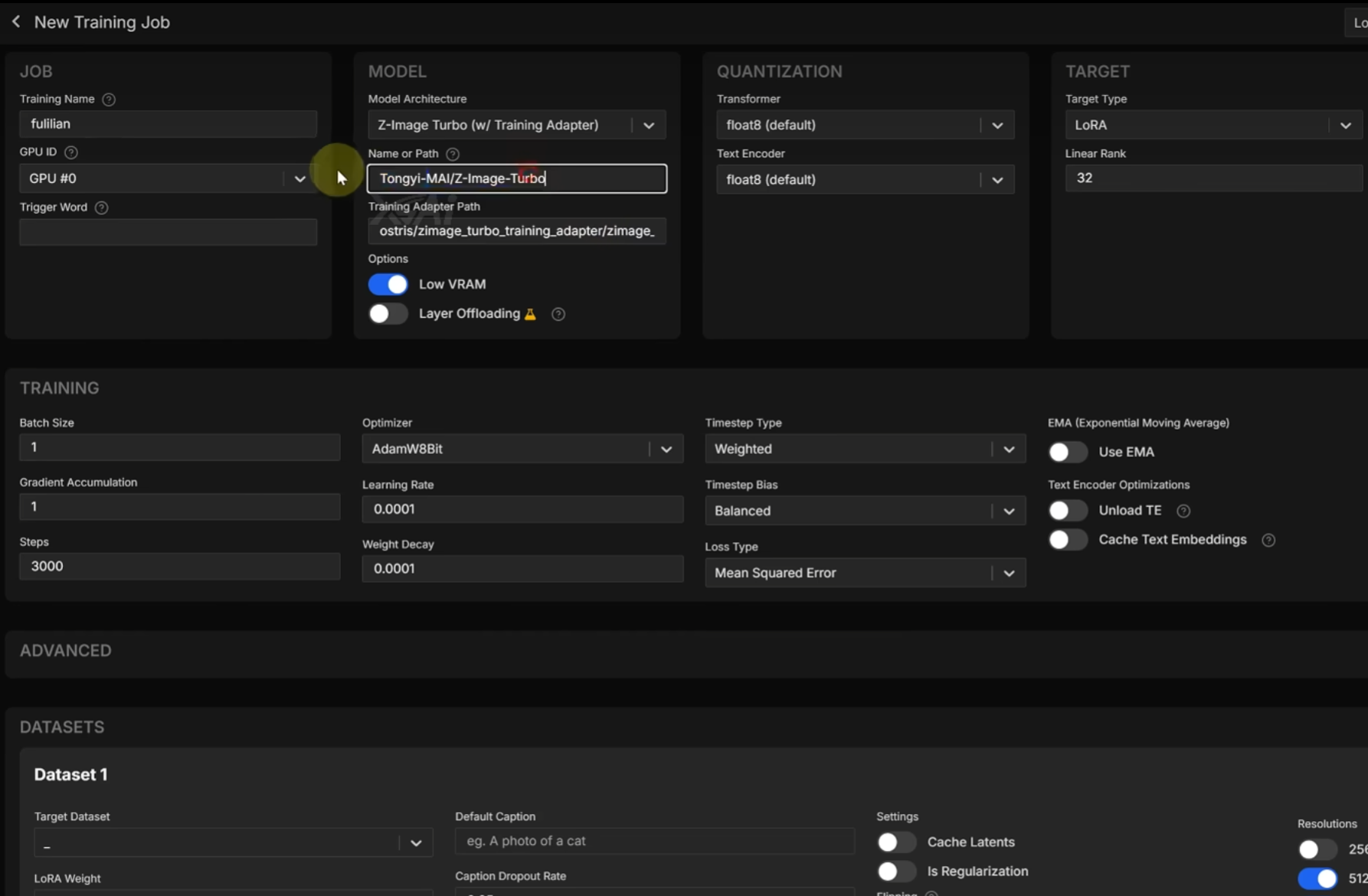
在新建任务界面(Training Name、Model Architecture 等):
关键字段与推荐值(针对 z-image-turbo):
-
Model architecture:选择z-image-turbotraining adapter(或界面中damage turbo training adapter) -
Base model path:保持默认(或指定本地底模) -
Low VRAM:如果显存 12–16GB,开启;显存 ≥24GB 可关闭获得更快训练 -
Save every:建议250(每 250 步保存并生成一次测试样本) -
Training steps:默认3000,若时间有限可用2500(示范用 2500) -
Batch size/Gradient accumulation:根据显存设置,UI 会自动推荐 -
Learning rate:常见范围1e-4~5e-4,可用2e-4作为起点 -
Precision:fp16或bf16(若硬件支持) -
Target dataset:选择已上传的furilian_dataset - 其他:保持默认或按界面提示
7. 测试提示词编写与每250步测试策略
测试提示词(Prompt) 用来每 save every(本文 250 步)生成样例,检验模型拟合情况。
如何生成测试提示词:
- 回到大语言模型,指令示例:
请为 Furilian 角色生成 10 条用于模型验证的测试提示词,包含不同姿态、表情、背景与场景。每条不超过 30 个词。 - 将生成的 10 条复制,粘贴到训练器的
Validation prompts区域。
示例测试 prompt(10 条):
Furilian, three-quarter view, looking at camera, soft smile, blue-white robe, forest background
Furilian, full-body action pose, leaping, flowing hair, dynamic lighting
Furilian, close up portrait, blue-green eyes, intricate ear jewelry, soft rim light
...
每 250 步查看 sample 图像,判断模型的角色稳定性、服装细节、光影、是否出现畸形、泛化能力。
8. 启动训练与监控(包含中断/恢复)
启动:
- 点击
Create Task-> 点击训练队列中的三角形(开始)。
监控要点:
- 观察 loss 曲线、生成样本(每 250 步),检查是否过拟合或欠拟合。
- 若样本在早期就很崩坏:可能 LR 太高或 batch 设置不当,适当降低 learning rate 或开启更强正则。
- 若模型太拟合(早期样本极其集中复制训练集样式):可加入更多负样本、增加数据多样性、或降低训练步数。
中断/恢复:
- UI 一般支持暂停/恢复。训练器会在
save every步保存 checkpoint,恢复时选择最新 checkpoint 即可。
9. 导出 LoRA 并在 Z-Image 工作流测试
训练完成后:
- 在训练器右侧或模型列表中找到
outputs或models文件夹,下载最后生成的 LoRA 文件(通常为.safetensors或.pt带权重格式,训练器会给出标准化文件名)。 - 将文件放入 Z-Image 的
configs/models/loras/(或 CONFI 根目录models/loras/)文件夹。
Z-Image 中调用示例 Prompt:
<lora:furilian:0.8> Furilian, portrait, soft cinematic lighting, high detail
- 在 Z-Image 中跑图,观察多张场景下的稳定性。好的 LoRA 应能在不同 prompt 与背景下保持角色关键特征(白发、耳朵、眼色、服装元素)。
10. 常见问题与优化建议
问题:训练后人物崩坏 / 畸形
- 可能原因:训练步数过多、learning rate 太高、训练集不足或多样性不足。
- 解决:减少步数、降低 LR、加入更多正面/侧面样本;增加正负面提示词。
问题:角色识别模糊或泛化差
- 可能原因:训练集风格不统一或标签不够明确。
- 解决:统一风格(尽量同一画风、光线),细化 prompt(角色专有描述优先)。
提升技巧:
- 若显存紧张,使用
low_vram、降低 batch 或使用 gradient accumulation。 - 使用多组测试 prompt,覆盖动作、表情、全身近景等,检验泛化。
- 在训练中期(如 1000、1500、2500 步)导出样本观察微调方向,再决定是否继续训练或微调超参。
总结
到这里,整套从素材准备、标注、训练器部署、参数调优到导出并在 Z-Image 中跑图的流程都讲完了。重点回顾如下:
- 单角色 LoRA:15–30 张高质量、角度分布均匀的图片 + 精确的文本标签,效果优秀且训练成本低。
- 使用大语言模型自动标注能极大提高效率,但一定要校对命名与一致性。
- 每 250 步保存并生成样本,便于判断训练走向并灵活中止或调整。
- 显存有限时开启 low_vram,适当降低 batch/使用 gradient accumulation。
- 最后的 LoRA 在 Z-Image 中验证,观察角色一致性、细节保持、泛化情况。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

