
大数据视角下的时序数据库选型:Apache IoTDB 核心竞争力拆解
前言
随着5G、物联网与工业互联网的深度融合,时序数据正以爆炸式速度增长——工业传感器的高频采集、智能电网的实时监测、车联网的动态反馈,每天都在产生PB级时序数据。据统计,2025年国内企业时序数据产生量同比增长超60%,这类数据具备的“三高两低”特性(高吞吐、高并发、高时序性、低价值密度、低查询复杂度),对数据库系统提出了严苛挑战。选择一款适配业务场景的时序数据库,直接决定了企业数据存储效率、分析成本与业务响应速度。本文将从大数据视角出发,拆解时序数据库选型的核心逻辑,通过对比国内外主流产品,深度解析Apache IoTDB的技术优势,为企业提供可落地的选型参考。

一、大数据场景下,时序数据库选型的6大核心维度
时序数据库的选型绝非“唯性能论”,在大数据视角下,需综合考量以下6个核心维度,才能匹配企业长期发展需求:
1. 海量数据写入性能
大数据场景下,每秒十万级甚至百万级的写入是常态,工业物联网中单集群每秒需处理千万条设备数据。数据库的写入吞吐量、端到端延迟直接决定业务能否实时采集数据,高基数场景下的性能稳定性尤为关键——若设备数量突破百万级后写入性能断崖式下跌,将直接导致数据丢失。
2. 存储成本控制
PB级时序数据是大数据场景的标配,存储成本已成为企业重要开支。压缩率、冷热数据分离能力直接影响总成本:同等数据量下,压缩率每提升10%,年存储成本可降低数万元。优秀的时序数据库需通过针对性压缩算法和分层存储策略,在保证数据完整性的前提下最大化降低存储开销。
3. 查询与分析效率
时序数据的高频查询场景集中在多维度聚合、时间范围筛选、降采样分析,需支持高效的聚合函数、设备级索引,且能快速响应复杂关联分析。大数据场景下,既要满足毫秒级实时查询(如金融交易监控),也要支撑TB级离线分析(如生产工艺优化),查询引擎的适配性至关重要。
4. 大数据生态兼容性
企业现有大数据架构(Hadoop、Spark、Flink、Hive)是既定基础,时序数据库需无缝融入现有体系,避免重复搭建数据链路。理想的解决方案应支持批流一体处理,实现实时流处理与离线批处理的全链路闭环,无需额外开发数据同步中间件。
5. 国产化与可控性
在政企类场景中,开源属性、社区活跃度、无厂商锁定成为关键诉求。需适配国产化软硬件体系,规避供应链风险,同时具备成熟的本土化技术支持,确保系统稳定运行。
6. 企业级特性
高可用、容灾备份、权限管理、监控告警等能力,是时序数据库从“测试环境”走向“生产环境”的核心门槛。大数据场景下,集群弹性扩展、数据分片迁移效率、故障自动恢复等特性,直接影响运维成本与系统稳定性。
二、国内外主流产品对决:IoTDB的差异化突围
目前海外主流时序数据库包括InfluxDB、TimescaleDB、Prometheus等,但在国内大数据场景下存在明显短板,而Apache IoTDB作为Apache顶级开源项目,针对性解决了这些痛点,其差异化优势体现在以下关键维度:
| 选型维度 | 海外主流产品(InfluxDB/TimescaleDB) | Apache IoTDB |
|---|---|---|
| 写入性能 | 高基数场景下吞吐量骤降,百万级设备接入时性能衰减明显 | 百万级/秒写入,设备级索引无性能衰减,支持200万条/秒单集群写入(电力行业实测) |
| 存储压缩率 | 平均压缩率10:1左右,存储成本较高 | 自研TsFile格式+多层编码,压缩率达20:1,较海外产品存储成本降低50%以上 |
| 大数据生态适配 | 对Flink/Spark适配不友好,需额外开发集成插件 | 原生支持批流一体,无缝接入Hadoop生态,内置Sink/Source插件集成Spark/Flink |
| 部署运维 | 集群部署复杂,边缘端适配性差,运维成本高 | 轻量化部署,支持单机/集群/边缘端多形态,集群扩容时数据迁移不中断业务 |
| 国产化支持 | 无本土化技术支持,适配国内软硬件体系成本高 | Apache顶级开源项目+Timecho企业级保障,完全适配国产化环境,提供中文文档与技术支持 |
IoTDB的核心竞争力在于“场景精准适配”——专为物联网、工业互联网等大数据场景设计,而非通用型时序数据库。其极致性能、成本优势与生态友好性的组合,完美契合了国内企业在大数据时序处理中的核心诉求。
三、IoTDB核心技术解密:为何能适配大数据选型需求
Apache IoTDB的技术优势并非单点突破,而是通过架构设计、存储格式、核心算法的全方位优化,系统性解决大数据时序处理痛点。
1. 树形数据模型:破解高基数场景难题

工业、车联网等场景中,设备通常具有严格的层级关系(集团→工厂→车间→设备→测点)。海外产品采用的Tag-Value模型易产生“基数爆炸”,而IoTDB独创的树形Schema将设备层级直接映射为路径(如root.ln.wf01.wt01.temperature),路径本身即为索引,前缀匹配查询效率极高,完美规避了Tag组合产生的笛卡尔积问题。元数据管理层基于B+树实现索引,缓存命中率达95%以上,即便管理千万级设备元数据也无性能瓶颈。
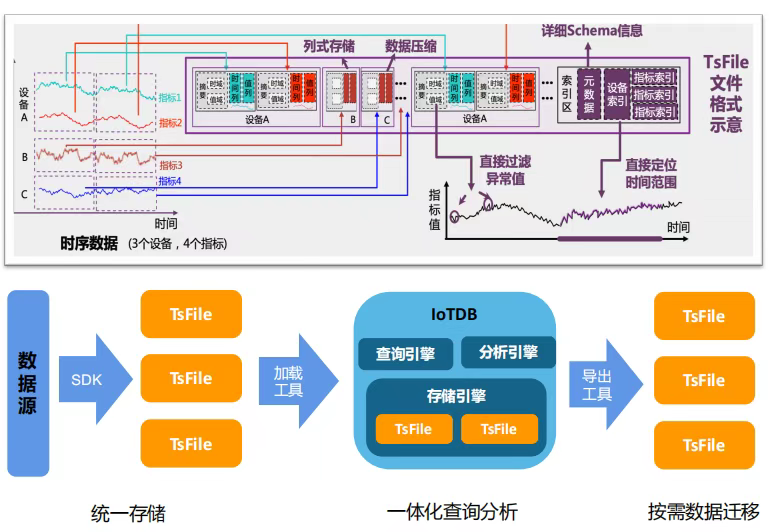
2. TsFile存储格式:极致压缩与高效查询的基石

IoTDB专属的TsFile时序文件格式是其核心竞争力之一,采用“文件头-数据区-索引区-尾部”结构,通过列式存储+多级索引优化读写性能:
- 列式存储按指标维度组织数据,大幅提升压缩效率与聚合查询性能;
- 支持LZ4/Snappy/Gzip/ZSTD四种Page级压缩算法,可按数据类型动态选择,工业传感器数据压缩比达10:1~20:1;
- 设备、时间、指标三级索引联动,查询时精准定位数据,实现毫秒级响应。

更重要的是,TsFile作为独立文件格式,Spark、Flink等大数据引擎可直接读取,无需经过数据库查询层,消除了ETL过程中的序列化开销,实现“一份数据,多处计算”。
3. 写入与存储优化:平衡高吞吐与低成本
IoTDB采用LSM-Tree写入模型,通过“WAL预写日志+内存MemTable+持久化SSTable”三级写入架构,支持写前数据预聚合(SUM/AVG等),降低持久化压力。在存储策略上,支持时间分区(按天/小时)与设备分区混合策略,热数据存储于SSD保障查询速度,冷数据自动迁移至HDFS/对象存储降低成本,迁移过程采用Copy-On-Write机制,不影响读写性能。某省级电力公司采用IoTDB后,3年50TB原始数据压缩后仅8TB,存储成本降低84%。
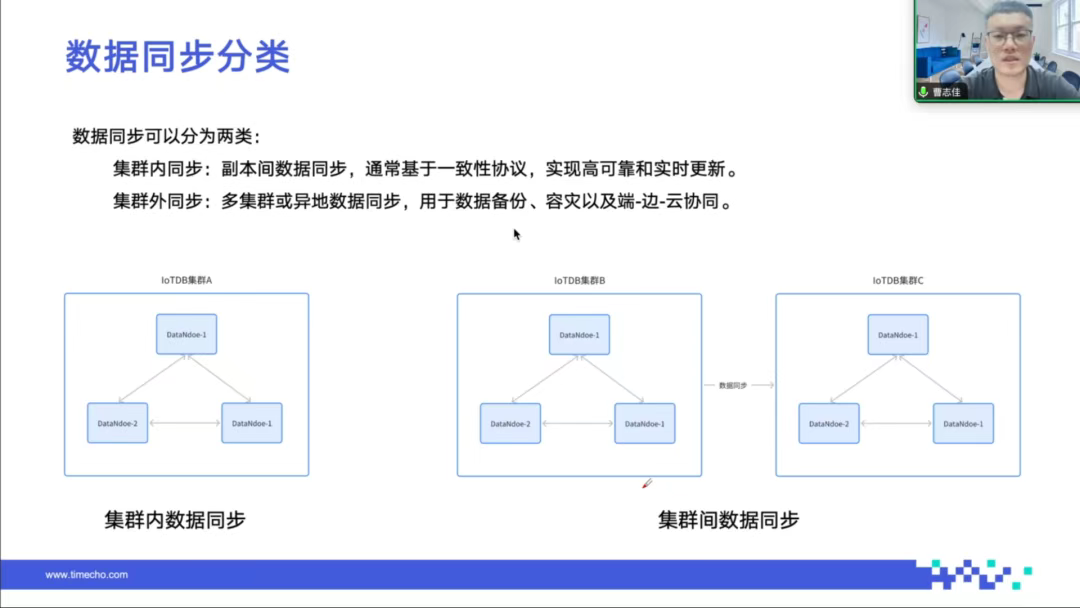
4. 端边云协同:解决边缘场景数据可靠性问题
工业现场网络环境不稳定是普遍痛点,IoTDB提供开箱即用的数据同步框架(IoTDB-Pipe/Sync),实现端边云协同:边缘端部署轻量级IoTDB Edge版,数据先本地落盘保证安全,再通过断点续传机制异步同步至云端。网络中断时自动记录传输进度,恢复后从断点续传,彻底解决了弱网环境下的数据丢失问题,这一特性是海外主流产品所不具备的。
5. 生态无缝集成:复用现有大数据架构
IoTDB深度适配国内主流大数据技术栈,支持Spark/Flink作为计算引擎,实现实时流处理与离线批处理的全链路闭环;兼容Hive/HBase,可直接读取HDFS上的冷数据;提供Grafana/Tableau插件实现可视化;支持标准SQL与JDBC接口,降低开发迁移成本。在智能制造场景中,IoTDB与Flink集成实现设备数据实时清洗,与Spark集成进行故障预测模型训练,设备故障率降低35%。
四、快速落地:IoTDB实操极简指南
为帮助企业快速落地,以下提供IoTDB的核心实操步骤,覆盖安装、基础操作与生产级代码示例:
1. 环境准备与安装
- 依赖环境:JDK 8/11(推荐JDK 8),测试环境4GB内存,生产环境16GB+内存;
- 下载安装:访问Apache IoTDB官方下载地址,选择稳定版binary安装包,Linux环境可通过
wget https://archive.apache.org/dist/iotdb/1.1.0/iotdb-1.1.0-bin.zip下载; - 启动服务:解压后执行
./sbin/start-server.sh启动服务端,./sbin/start-cli.sh启动客户端,成功后显示“IoTDB>”提示符。
2. 核心基础操作(CLI命令行)
-- 创建存储组(按业务维度划分)
CREATE STORAGE GROUP root.manufacture;
-- 创建时间序列(设备测点)
CREATE TIMESERIES root.manufacture.machine001.temperature WITH DATATYPE=FLOAT, ENCODING=GZIP;
-- 批量插入数据
INSERT INTO root.manufacture.machine001(timestamp, temperature) VALUES
(1735622400000, 25.6),
(1735622460000, 25.8),
(1735622520000, 26.0);
-- 5分钟粒度聚合查询
SELECT AVG(temperature) FROM root.manufacture.machine001
WHERE time >= 1735622400000 AND time <= 1735622700000
GROUP BY TIME(5m);
3. 生产级Java代码示例(批量写入)
import com.alibaba.druid.pool.DruidDataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
public class IoTDBBatchInsert {
private static DruidDataSource dataSource;
static {
dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:iotdb://localhost:6667/");
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setMaxActive(20);
}
public static void batchInsert(String deviceId, long baseTime, int dataCount) throws Exception {
String sql = String.format(
"INSERT INTO root.manufacture.%s(timestamp, temperature) VALUES (?, ?)", deviceId
);
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
for (int i = 0; i < dataCount; i++) {
pstmt.setLong(1, baseTime + i * 60000);
pstmt.setFloat(2, 25.0f + (float) (Math.random() * 5));
pstmt.addBatch();
if ((i + 1) % 1000 == 0) {
pstmt.executeBatch();
pstmt.clearBatch();
}
}
pstmt.executeBatch();
System.out.printf("插入%d条数据完成%n", dataCount);
}
}
public static void main(String[] args) throws Exception {
batchInsert("machine002", 1735622400000L, 10000);
dataSource.close();
}
}
4. 生产环境关键配置
- 集群部署:建议3副本集群,修改
conf/iotdb-cluster.properties配置节点信息; - 性能优化:开启内存表缓存(
enable_mem_table=true),按天分区; - 数据清理:通过TTL策略自动删除过期数据(
ALTER TIMESERIES ... SET TTL=2592000s,即30天); - 监控运维:接入Prometheus+Grafana,或使用Timecho企业版可视化监控面板。
五、企业级落地场景与选型建议
1. 场景化选型建议
- 边缘端/单机场景(如小型工厂、边缘网关):采用IoTDB单机版,搭配Timecho企业级监控工具,轻量化部署,降低运维成本;
- 中大规模大数据场景(如省级电力、智慧城市):部署IoTDB集群+Flink实时计算+Spark离线分析,构建批流一体时序数据平台,适配PB级数据存储;
- 弱网场景(如偏远地区设备监控):利用IoTDB端边云协同能力,边缘端本地存储,云端异步同步,保障数据完整性。
2. 成本优化技巧
- 冷热数据分离:近7天热数据存储于SSD,历史冷数据迁移至HDFS/S3,存储成本降低60%以上;
- 按需选择压缩算法:数值型数据用GZIP/ZSTD,字符串型用字典编码+LZ4,平衡压缩率与解压速度;
- 合理设置预聚合粒度:针对高频查询场景,预计算1min/5min/1h粒度的聚合值,提升查询效率。
六、总结
在大数据时代,时序数据库选型的核心是“技术适配场景”。Apache IoTDB作为国产开源时序数据库的标杆,通过树形数据模型、TsFile存储格式、LSM-Tree写入架构、端边云协同等核心技术创新,系统性解决了高吞吐写入、高效存储、实时分析等大数据场景下的关键痛点。其在电力、智能制造、智慧交通等领域的规模化落地案例,充分验证了技术架构的稳定性与扩展性——某汽车零部件制造商接入2000+台生产设备,单车间写入吞吐量达50万条/秒,设备故障率降低35%;某一线城市智慧交通项目接入10万+车载终端,高峰通行效率提升20%。
与海外主流产品相比,IoTDB不仅在性能与成本上具备显著优势,更深度适配国内大数据生态与国产化需求,无厂商锁定风险。对于追求自主可控、高性能、低成本的企业而言,Apache IoTDB无疑是大数据场景下时序数据库的优选方案。
相关资源通道:
-
⬇️ 开源版下载(Apache 官方):
https://iotdb.apache.org/zh/Download/
(提示:建议下载包含 Cluster 的版本,单机和集群都能用) -
🏢 企业版官网(天谋科技 Timecho):
https://timecho.com
© 版权声明
文章版权归作者所有,未经允许请勿转载。