AI 编码进化论:从 Vibe Coding 到 SDD 规格驱动开发
大家好,我是玄姐。
核心摘要:
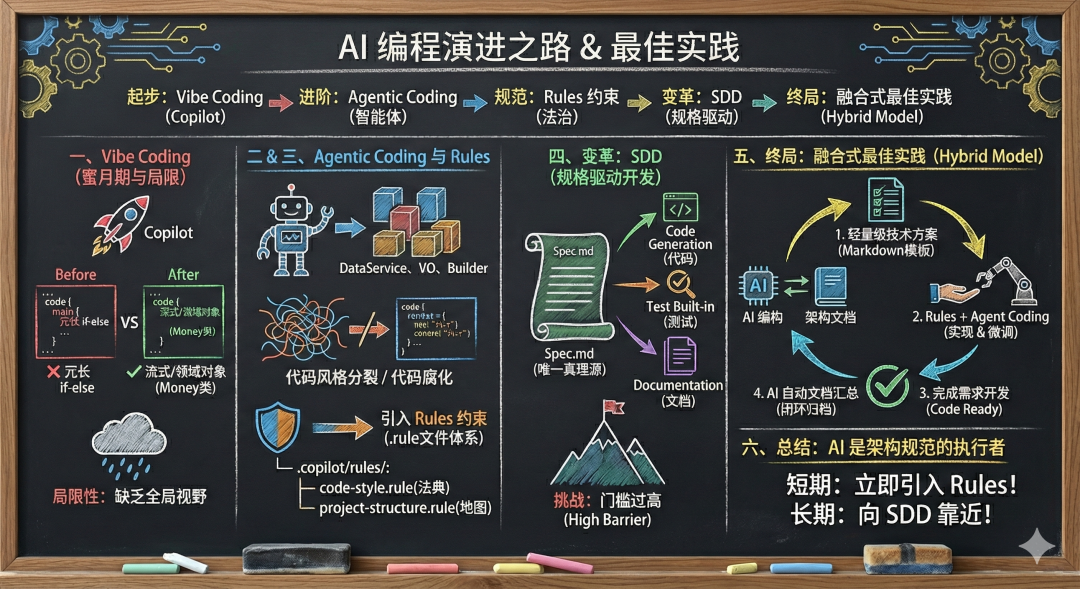
AI 极大地提升了编码速度,但也带来了代码风格不一、维护困难等新挑战。本文复盘了 Vibe Coding 到 SDD 演进历程:
初级阶段:使用 Copilot 进行简单代码补全(Vibe Coding)。
中级阶段:Agentic Coding 单次生成完整模块,但遭遇“代码腐化”。
高级阶段:引入 Rules 约束,建立 AI 的“项目法治”。
探索阶段:尝试 SDD(Specification Driven Development),以自然语言规格为唯一真理源。
最佳实践:最终确立了“轻量级技术方案 + Rules 约束 + Agent 实现 + AI 自动归档”的融合开发模式。
一、 起点:代码智能补全 (The Era of Copilot)
在引入 AI 的初期,团队主要使用 Copilot 进行代码补全和单方法重构。这是 AI 编程的“蜜月期”,门槛低,收益直观。

1.1 典型场景
-
消除机械劳动:自动补全 DTO 转换、数据组装代码。
-
单方法重构:将冗长的 if-else 逻辑重构为优雅的流式处理或领域对象方法。
重构案例对比:
// ❌ 原始代码:冗长、易读性差public String getDiscountText(Long finalPrice, Long nnPrice) { if (finalPrice == null || nnPrice == null) return ""; if (finalPrice <= nnPrice) return ""; Long discount = finalPrice - nnPrice; if (discount <= 0) return ""; String discountYuan = String.valueOf(discount / 100.0); return discountYuan + "元";}
// ✅ AI重构后:语义清晰、防御性强public String getDiscountText(Long finalPrice, Long nnPrice) { if (finalPrice == null || nnPrice == null || finalPrice <= nnPrice) { return ""; } // AI引入了Money类处理金额,避免精度问题 Money discount = Money.ofFen(finalPrice).subtract(Money.ofFen(nnPrice)); return discount.getCent() <= 0 ? "" : String.format("%s元", discount.getYuan());}1.2 局限性
虽然键盘敲击次数减少了70%,但我们很快触到了天花板:AI 缺乏全局视野。它只能优化局部代码,无法理解复杂的业务上下文,也无法保证跨文件的逻辑一致性。
二、 进阶:Agentic Coding (智能体编程)
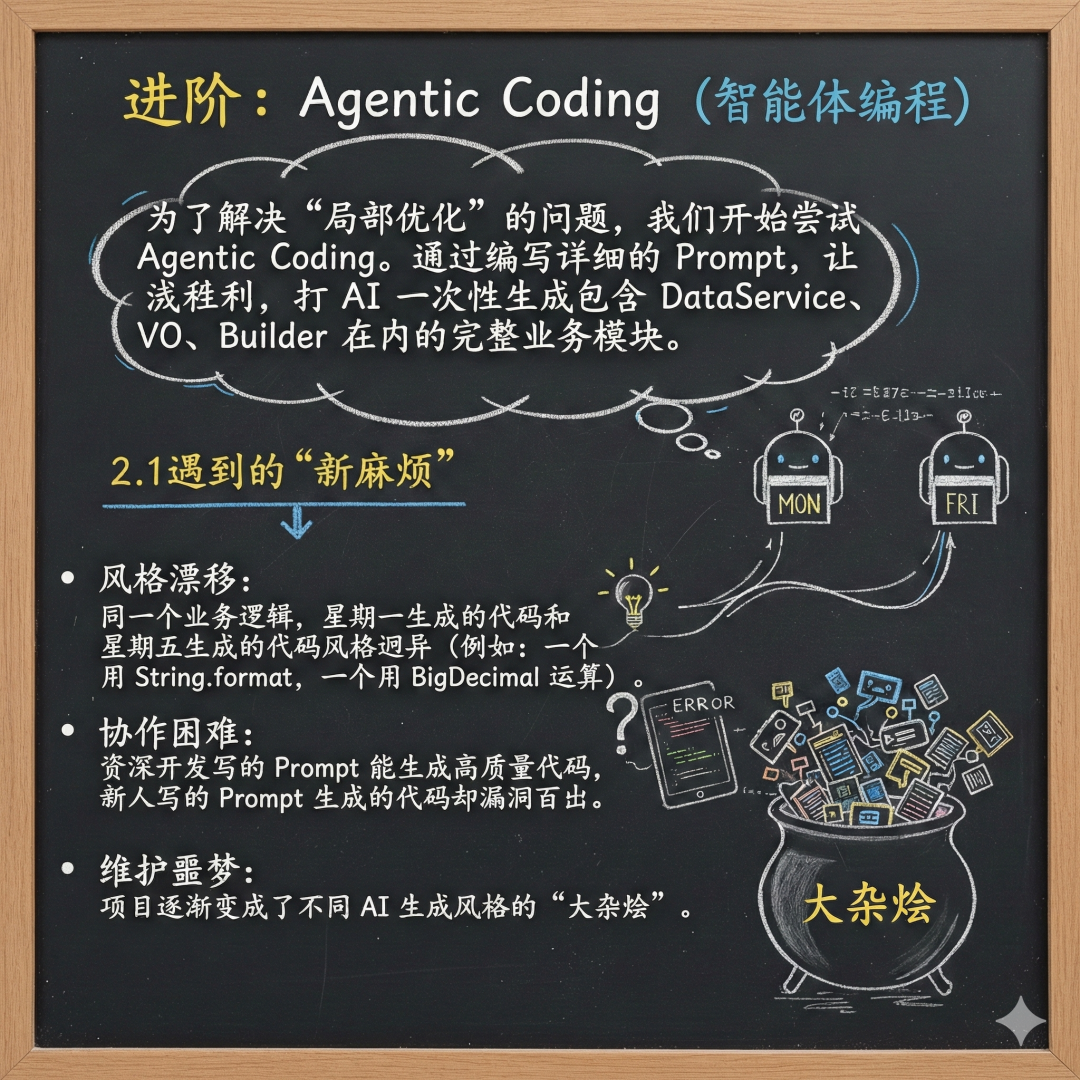
为了解决“局部优化”的问题,我们开始尝试 Agentic Coding。通过编写详细的 Prompt,让 AI 一次性生成包含 DataService、VO、Builder 在内的完整业务模块。
2.1 遇到的“新麻烦”
虽然开发效率进一步提升,但“代码风格分裂”的问题随之而来:
-
风格漂移:同一个业务逻辑,星期一生成的代码和星期五生成的代码风格迥异(例如:一个用 String.format,一个用 BigDecimal 运算)。
-
协作困难:资深开发写的 Prompt 能生成高质量代码,新人写的 Prompt 生成的代码却漏洞百出。
-
维护噩梦:项目逐渐变成了不同 AI 生成风格的“大杂烩”。
三、 规范化:引入 Rules 约束
为了解决风格分裂,我们意识到必须给 AI 立“规矩”。我们引入了 .rule 文件体系,将项目规范固化为 AI 必须遵守的准则。
3.1 Rules 体系结构
我们建立了一个 .copilot/rules/ 目录,包含以下核心约束:
-
code-style.rule(法典):规定命名法(大驼峰/小驼峰)、空值判断工具类(统一用 CollectionUtils)、日志格式等。
-
project-structure.rule(地图):定义包结构(module, domain, dataservice)和分层规范。
-
features.rule(工艺):规定 DataService 必须实现特定接口,Builder 必须继承特定基类。
3.2 效果与不足
引入 Rules 后,代码一致性大幅提升,Review 效率提高了 50%。但痛点依然存在:文档滞后。代码改了,技术方案文档往往来不及更新,导致文档与代码脱节。
四、 变革:SDD 规格驱动开发 (Specification Driven Development)
为了彻底解决“文档脱节”和“逻辑一致性”问题,我们开始探索 SDD。
4.1 SDD 的核心理念
-
Single Source of Truth:自然语言编写的规格书(spec.md)是唯一的真理。
-
Code Generation:代码、测试用例、文档全部由规格书自动生成。
-
Test Built-in:规格即测试,保证可测试性内建。
4.2 实践流程 (基于 Spec Kit)
-
制定宪章 (constitution.md):确立全局设计原则(如模块化、安全性、开发规范)。
## 核心原则宪章 (精简版)
### 1. 架构与设计原则* **模块化设计**:严守高内聚、低耦合、单一职责原则;禁止循环依赖。* **分层架构**:代码必须严格归属于以下 9 层: 1. **接入层** (请求处理) 2. **解决方案层** (入口) 3. **子解决方案层** (细粒度业务) 4. **模块构建层** (ModuleBuilder) 5. **数据服务层** (DataService) 6. **外部服务层** (Provider) 7. **领域模型层** (Domain/DTO) 8. **基础设施层** (基础组件) 9. **通用模块层** (Common)
### 2. 开发与代码规范* **编码标准**:严格遵循《阿里巴巴Java开发手册》及安全标准(鉴权、数据脱敏)。* **代码风格**:保持统一格式,合并前必须通过静态分析。* **语言要求**:所有 Speckit 相关文档、Spec 文件、配置均**强制使用中文**。
### 3. 质量保证* **测试强制**:全链路测试(单元/集成/契约)。* **核心指标**:核心业务路径代码覆盖率 **≥ 80%**。* **兼容性**:所有变更必须向后兼容。
### 4. 工作流与治理* **分支策略**:**不要创建新分支**,直接在当前分支进行操作。* **生成约束**:代码生成必须遵循 `code-generation-prompt.aonerule`。* **最高效力**:本宪章是最高准则,所有 PR 必须符合上述原则。-
编写规格 (spec.md):用自然语言详细描述功能需求(FR)、非功能需求(NFR)和测试用例(TC)。
# XX 红包模块规格说明
## 1. 功能概述在 XX 频道页面展示经过过滤和排序的用户可用红包列表。
## 2. 功能需求 (FR)
### 2.1 核心逻辑* **数据源**: 调用 `FpProvider.queryUserFundBuyPoolId`。* **输入参数**: `userId`, `fundPoolIds` (配置), `customRuleId` (配置), `securityCode` (配置)。* **过滤规则** (必须全部满足): 1. `payStatus == 2` (状态可用) 2. `startTime <= now <= endTime` (有效期内) 3. `threshold <= amountThreshold` (门槛 <= 配置值,默认20元)* **异常处理**: 用户未登录或 Provider 调用失败 -> 返回空列表。
### 2.2 组装逻辑* **空处理**: 若过滤后列表为空 -> 返回 `null` (不展示模块)。* **VO构建**: * `redPacketList`: 转换为 `RedPacketItem` 列表。 * `totalAmount`: 所有可用红包金额求和。 * `expandText`: 读取配置文案。
## 3. 非功能需求 (NFR)* **SLA**: 接口超时 **500ms**,超时即降级返回空,严禁阻断页面加载。* **配置**: 需支持 `fundPoolIds` 和 `amountThreshold` 的动态配置。
## 4. 核心测试用例 (TC)* **TC-1 (正常场景)** * **输入**: 红包A(5元, 门槛15), 红包B(10元, 门槛25)。 * **预期**: VO非空,`totalAmount`="15.00",列表按门槛排序(A在前)。* **TC-2 (边界过滤)** * **输入**: 红包C(门槛25元),配置限制 `amountThreshold`=20元。 * **预期**: 返回 `null` (因门槛超限被过滤)。-
自动生成:AI 读取规格,生成完备的 DataService、ModuleBuilder 实现以及100% 覆盖的单元测试。
4.3 SDD 的红与黑
-
红(收益):
-
-
极致的一致性:产品、开发、测试基于同一份文档沟通。
-
文档永不过期:修改逻辑必须先改规格,文档即代码。
-
高质量交付:自动生成的测试用例覆盖了大量边界条件。
-
-
黑(挑战):
-
-
门槛过高:写出一份完美的规格书比写代码还难,特别是对于逻辑复杂的业务。
-
工具链不成熟:AI 对长文本规格的理解偶有偏差,且增量更新困难。
-
历史包袱:老旧代码库难以切换到 SDD 模式。
-
五、 终局:融合式最佳实践 (The Hybrid Model)
鉴于 SDD 的高门槛,团队并未全盘切换,而是总结出了一套兼顾效率与规范的融合打法。这是我们当前推荐的最佳实践。
5.1 核心公式
最佳实践 = 轻量级技术方案 + Rules 约束 + Agent Coding + AI 自动归档
5.2 具体执行步骤
步骤 1:轻量级技术方案(输入)
不再追求完美无缺的 SDD 规格,而是填写一份结构化的 Markdown 模板。聚焦于“定义数据”和“核心逻辑”,而非实现细节。
轻量级技术方案模板参考如下:
# [需求名称]-技术方案## 业务定义[简要描述业务背景和目标,1-2句话]## 业务领域对象[如果需要新增/修改 BO 或 DTO,在此说明]## 模块领域对象[需要新增/修改的VO对象]| 对象含义 | 实现方案 | 属性及类型 ||---------|---------|-----------|| [对象名] | 新增/修改 | 1. 字段1:类型 - 说明<br>2. 字段2:类型 - 说明 |## 数据服务层[需要新增/修改的数据服务]| 数据服务定义 | 实现方案 | execute 逻辑 ||------------|---------|-----------|| [服务名] | 新增/复用 | 1. 步骤1<br>2. 步骤2 |## 模块构建器[需要新增/修改的模块构建器]| 模块构建器定义 | 实现方案 | doBuild 逻辑 ||--------------|---------|-------------|| [构建器名] | 新增/修改 | 1. 获取数据<br>2. 处理逻辑<br>3. 构建VO |-
耗时:从 2小时 缩减至 30分钟。
步骤 2:Rules + Agent Coding(实现)
AI 读取技术方案和项目 Rules,快速生成代码。开发者进行少量的微调(Human-in-the-loop)。
步骤 3:AI 自动文档汇总(闭环)
完成需求开发 → 提交 AI:"将本次代码逻辑汇总到汇总文档" → AI 分析代码 → AI更 新文档这是最关键的一步。开发完成后,将代码反向投喂给 AI,指令如下:
“我刚完成了 NN 红包模块,请分析代码,将业务逻辑、数据流转、关键规则汇总到《架构逻辑总览.md》中。”
要求 AI 汇总的架构文档结构设计如下:
# XX 业务整体架构与逻辑文档## 一、业务概述[业务背景、目标、核心价值]## 二、整体架构### 2.1 技术架构[分层架构图、技术栈]### 2.2 模块组成[各个模块的功能和关系]## 三、核心模块详解### 3.1 XX Feeds模块#### 3.1.1 功能说明[模块的核心功能]#### 3.1.2 数据流转[数据从哪里来,经过哪些处理,最终输出什么]#### 3.1.3 关键逻辑[重要的业务规则、计算逻辑、判断条件]#### 3.1.4 代码位置[对应的类和方法]### 3.2 XX 红包模块[类似结构]### 3.3 XX吊钩层模块[类似结构]## 四、数据服务层[各个数据服务的功能和依赖]## 五、关键流程[重要的业务流程时序图]## 六、配置说明[配置项说明]## 七、扩展点[未来可能的扩展方向]5.3 自动生成的架构文档示例
AI 会自动生成包含以下维度的文档,确保文档永远反映代码的最新状态:
-
功能说明:业务价值是什么。
-
数据流转:User -> Service -> Filtering -> VO 的全链路。
-
关键逻辑:提取代码中的核心 if-else 规则(如红包过滤门槛、排序权重)。
-
代码地图:类文件的物理位置索引。
六、 总结与展望
从 Vibe Coding 的随性,到 SDD 的严谨,再到融合模式的务实,团队的 AI 编程之路表明:AI 不仅仅是代码生成工具,更是架构规范的执行者。
-
短期建议:立即在项目中引入 Rules 文件,统一团队的 AI 生成规范。
-
长期方向:随着工具链的成熟,向“自然语言编程”的 SDD 模式靠近,让代码成为实现的细节,而规格成为核心资产。
好了,这就是我今天想分享的内容。如果你对构建企业级 AI 原生应用新架构设计和落地实践感兴趣,别忘了点赞、关注噢~
—1—
加我微信
扫码加我👇有很多不方便公开发公众号的我会直接分享在朋友圈,欢迎你扫码加我个人微信来看👇

加星标★,不错过每一次更新!
⬇戳”阅读原文“,立即预约!
© 版权声明
文章版权归作者所有,未经允许请勿转载。