kafka重平衡问题-golang
这里只讨论"github.com/IBM/sarama"的用法
这里将会从触发重平衡的原因,影响重平衡的因素去介绍重平衡
1. 重平衡带来的问题
重平衡设计原意是帮助开发者,实现动态负载均衡,节点异常管理的好方法。但实际使用过程中,因为却带来了大量了的问题。kafka设计之初是为了实现海量数据下的低延迟(毫秒)处理能力,所以默认参数也都是为了做低延迟保障。所以如果对kafka进行优雅调参和正确心跳变得非常重要。
大家可能遇到问题:
- 少量任务执行慢,但导致全部分区都重新分配。
- 大量任务处理慢,一直循环重平衡,导致重平衡期间,消费者会处于闲置状态,无法处理任务,任务积压。对已经拿到重平衡后结果的消费者已经执行完的任务时,重平衡变量,导致自己提交失败。
- 同时启动多个消费者时,能正常消费,一旦扩缩容,就会一直重平衡,很难稳定下来。
2. 触发重平衡的原因
1. 消费组中新增消费者
因为消费者一旦启动,就会请求broker,所以消费者新增会立即被kakfa识别到,立即触发重平衡(需要和消费者离开的场景区分开)
2. 消费者主动离开
例如,对机器缩容的时候,关闭掉了消费者。这里不会立即触发重平衡,因为kafka判断消费者的存活机制是心跳上报,消费者上报有间隔的上报心跳(config.Consumer.Group.Heartbeat.Interval),kafka在一段时间内发现有心跳上报(Consumer.Group.Session.Timeout),就认为消费者仍然存活。
所以当消费者离开后,broker等待一个Session.Timeout时间,发现没有上报,才会触发重平衡。
所以触发缩容的时候,会可能导致消息大于 Session.Timeout的延迟。
3. 消费者无心跳
这里golang的java是client实现略有不同
1. java有两种识别方式:
1.认为节点死亡: config.Consumer.Group.Heartbeat.Interval和Consumer.Group.Session.Timeout
2. 认为节点处理速度过慢:max.poll.interval.ms,当消费者会拉取一批数据cache到本地(ChannelBufferSize),一遍执行一遍拉数据,当cache满了,且就会停止拉新数据,直到缓冲区空出新的位置。当某个消费者执行时间过长,导致缓冲区填满且长时间无法空闲出来去容纳新数据,就停止拉数据。当通知拉数据时间>max.poll.interval.ms会认为这个节点处理能力不行,从而触发重平衡,把分配给这个消费者的分区分给其他消费者
2.golang:
主要依赖于 config.Consumer.Group.Heartbeat.Interval和Consumer.Group.Session.Timeout。然而心跳上报和消费执行时绑定在一起的,互相堵塞,即执行完任务才会上报心跳。所以一旦执行时间大于Session.Timeout,就会导致心跳超时,被踢出消费组
3. 影响重平衡因素
1. 心跳检测
-
config.Consumer.Group.Heartbeat.Interval和Consumer.Group.Session.Timeout
前面讲到了心跳检测失败,就会触发重平衡,所以根据任务时间调整这两个任务,就能不符合预期的重平衡事件。
Consumer.Group.Session.Timeout>单个消息执行时间
config.Consumer.Group.Heartbeat.Interval如果任务时间较长,配置为一批任务时间的1/3
当前这个参数受控于client端和broker端,client端需要配置在broker允许的范围呢
这对应broker上的group.min.session.timeout.msandgroup.max.session.timeout.ms,一般默认min是6s,max是30min。最终值参见broker配置。这俩参数也是可以配置修改的,可以根据实际业务场景去配置。
不过不建议配置过长,意义不是很大。对于耗时较长的任务,例如一次执行要1h或者5h,那这种任务更重要的是减少任务恢复代价,不建议仅仅通过offset去简单从一个任务从头重启。而需要引入第三方db去记录任务状态
2. 缓冲区消息数量
-
config.ChannelBufferSize这个参数决定了任务的数量,一批消息的执行时间=单个消息*config.ChannelBufferSize 。如果任务执行很慢,建议参数配置足够小,避免重平衡后导致大量的消息提交失败。
3. 重平衡超时时间
config.Consumer.Group.Rebalance.Timeout,看到1后,是否任务只要把任务超时时间配置足够大就可以了呢?例如任务执行一次小于5min,Consumer.Group.Session.Timeout=6min,config.Consumer.Group.Heartbeat.Interval=3s。那是否足够安全呢?大部分场景是正常。但是如果所有节点正在处理数据中,这时出现了节点扩缩容,或者出现了节点异常被踢出消费组,就会出现循环重平衡。默认重平衡超时时间是1min。重平衡期间任务中的消费者将无法发送心跳去join消费组,导致被丢弃。当任务执行完,发送心跳时,broker又以检测到新消费者再次重平衡。
完整流程如下:
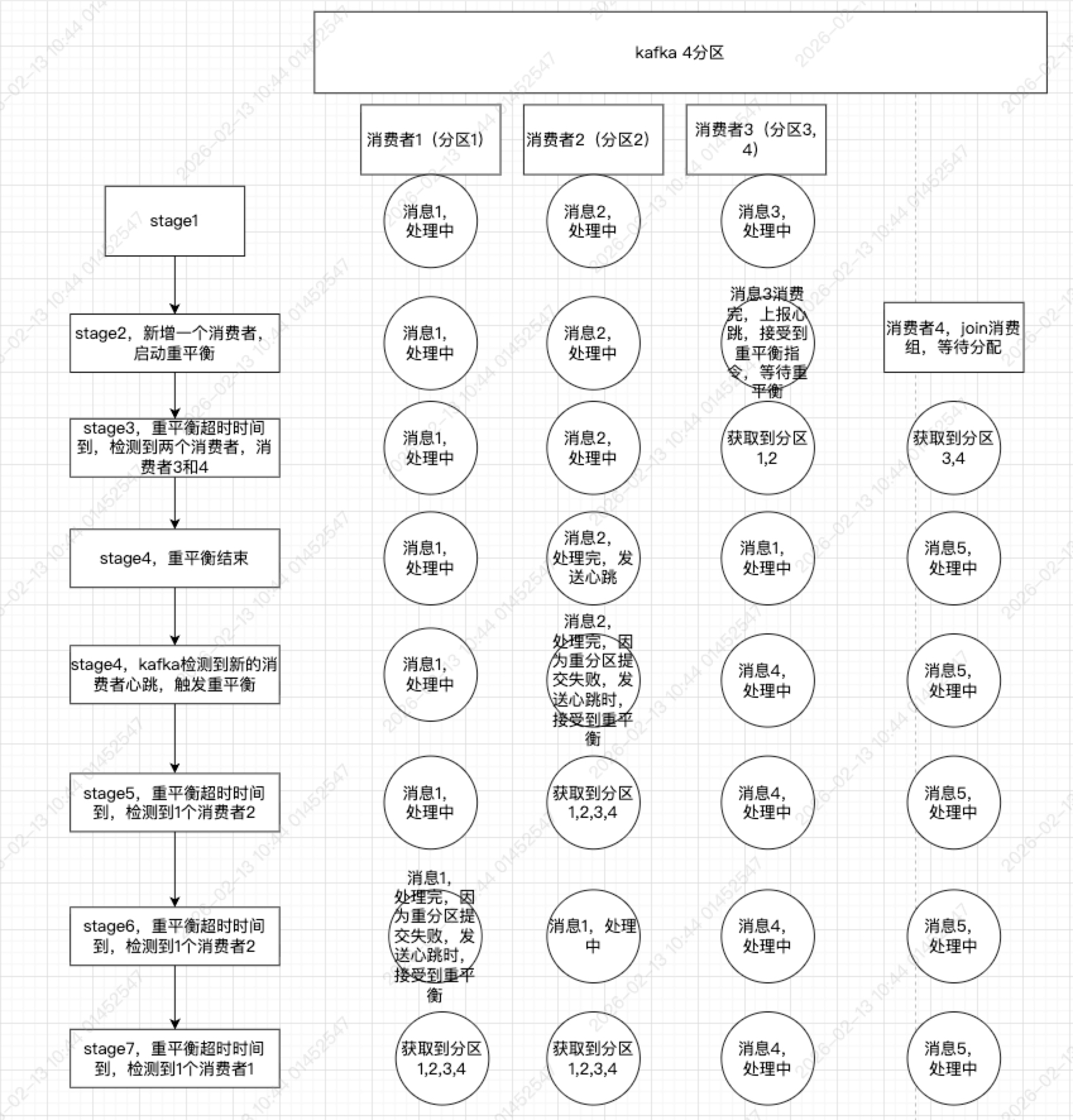
所以如果想要规避这种情况有两个方案
- 重平衡时间>任务执行时间,触发重平衡时,每个消费者都可以有一次机会去发出心跳
- 任务执行和kafka重平衡检测并行,一但检测到重平衡,则立即中断任务,发出心跳给broker。
4. 重平衡检测
重平衡期间,消费者处于闲置状态不再处理任何数据,直到任务结束。如果不愿意接受闲置时间过长,可以使用通过将任务处理协程异步出去,主流程一边等任务执行,一边等待kafka检测当前的session状态,当重平衡时session.Context().Done()
会接收到消息。这里直接结束,发出心跳。
func (h *Handler) handle(session sarama.ConsumerGroupSession, msg *sarama.ConsumerMessage) (err error) {
defer func() {
if recovererr := recover(); recovererr != nil {
errstack := errpkg.GetErrStack()
err = errors.Errorf("handle panic,recovererr:%v,errstack:%v", recovererr, errstack)
slog.Error("handle failed", "err", err)
}
}()
signal := make(chan error)
go func() {
err := h.handleSigle(session, msg)
signal <- err
}()
for {
select {
case err := <-signal:
slog.Error("handleSigle failed", "err", err)
return nil
case <-session.Context().Done():
slog.Info("end hanle ,session is done")
return nil
}
}
}
完整代码
package kafka
import (
"fmt"
"log/slog"
"sync"
"github.com/IBM/sarama"
"github.com/pkg/errors"
errpkg "inc-nlp-llm-clue-dispatch-online/err"
)
type MessageHandler interface {
Handle(name string, topic string, partition int32, offset int64, key string, value string) error
}
type Handler struct {
name string
mermberID string
handler MessageHandler
processingLock sync.Mutex // 限制单个消费者实例的并行度
}
// Setup 在消费组会话开始前运行一次
func (h *Handler) Setup(session sarama.ConsumerGroupSession) error {
h.mermberID = session.MemberID()
slog.Info("Consumer Setup", "name", h.name,
"mermberID", h.mermberID,
"generationID", session.GenerationID(),
"partion", session.Claims(),
"h", fmt.Sprintf("%p", h),
)
return nil
}
// Cleanup 在消费组会话结束后运行一次
func (h *Handler) Cleanup(session sarama.ConsumerGroupSession) error {
slog.Info("Consumer Cleanup", "name", h.name,
"mermberID", h.mermberID,
"generationID", session.GenerationID(),
"partion", session.Claims(),
)
return nil
}
// ConsumeClaim 从 Kafka 的分区中拉取消息并处理
func (h *Handler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for {
select {
case msg := <-claim.Messages():
err := h.handle(session, msg)
if err != nil {
slog.Error("ConsumeClaim failed", "err", err)
}
case <-session.Context().Done():
return nil
}
}
}
func (h *Handler) handle(session sarama.ConsumerGroupSession, msg *sarama.ConsumerMessage) (err error) {
defer func() {
if recovererr := recover(); recovererr != nil {
errstack := errpkg.GetErrStack()
err = errors.Errorf("handle panic,recovererr:%v,errstack:%v", recovererr, errstack)
slog.Error("handle failed", "err", err)
}
}()
signal := make(chan error)
go func() {
err := h.handleSigle(session, msg)
signal <- err
}()
for {
select {
case err := <-signal:
slog.Error("handleSigle failed", "err", err)
return nil
case <-session.Context().Done():
slog.Info("end hanle ,session is done")
return nil
}
}
}
func (h *Handler) handleSigle(session sarama.ConsumerGroupSession, msg *sarama.ConsumerMessage) error {
// 串行处理该消费者实例的所有分区消息
h.processingLock.Lock()
defer h.processingLock.Unlock()
err := h.handler.Handle(h.name, msg.Topic, msg.Partition, msg.Offset, string(msg.Key), string(msg.Value))
if err != nil {
slog.Error("Message handle failed", "err", err)
} else {
slog.Info("Message handle finish",
"topic", msg.Topic,
"partition", msg.Partition,
"offset", msg.Offset,
"key", string(msg.Key))
}
session.MarkMessage(msg, "")
session.Commit()
return nil
}
5. 重平衡策略
-
config.Consumer.Group.Rebalance.Strategykafka重平衡策略 - kafka提供了三种重平衡策略,range,roundrobin,sticky.
如果是为了维持任务稳定性,减少任务重平衡带来的开销,这里建议使用sticky,他会最大限度,尽量少的修改分区分配的变动,例如4分区,4消费者。新增1个,最终不会调整分区分配。
5. 如何解决
到这里,主要触发重平衡问题的原因就是
1. 任务原本执行时间长,
没有合理地配置心跳超时时间和重平衡时间
- 用sticky,最小限度地调整分区分配情况
- 增大Consumer.Group.Session.Timeout为略大于最大任务执行时间,config.Consumer.Group.Heartbeat.Interval=Consumer.Group.Session.Timeout/3
- 选择增大config.Consumer.Group.Rebalance.Timeout,或者通过session检测去监控重平衡触发,及时上报心跳
2. 异常的任务耗时,突发的延时过长
- 机器节点异常了,如果节点的网络,cpu,内存问题,应当触发重平衡,直到该节点状态恢复
- io延迟超预期,合理控制所有的io超时限制,避免完全不可控的任务执行时间。
5. 应用场景
所有产品都是为对应的应用场景所设计的,kafka原本设计是为了海量低延迟。快速重平衡也是为了对节点异常下的快速切流保障。
但kafka也保留了开发者自由调整参数的空间,去适配不同的应用场景。
最后,可以适配不同场景不等于所有场景,对于超长延时的任务,如果小时级别的任务,建议还是加上任务恢复机制,不纯依赖kafka进行任务恢复
6. 其他
最后kafka是为流式场景设计,如果kafka有这些问题,为啥很多流式场景在用呢
- 常见的使用还是海量数据,低延迟的为主
- flink的流式使用帮忙解决了这些问题,flink是for流式的大数据任务处理,天然就有任务长,数据大的特性。
为了保证任务稳定和可恢复性强,引入了checkpoint机制,定时为整个数据流做快照,记录下此时的任务状态(包含计算状态),这里也会记录kafka的消费情况。所以就算任务执行时间长,flink自己做了状态管理,不受限预任务的任务时间,避免kafka反复重平衡。
如果有问题,欢迎指出交流哈,也可以在go的git仓库里去查找或者提出issues
https://github.com/IBM/sarama/issues
© 版权声明
文章版权归作者所有,未经允许请勿转载。