
Spark sql之distinct优化
distinct物理执行计划
为更好地了解spar sql的distinct执行原理,我们先从实际工作中常用到的几种distinct 案例入手,看看distinct物理执行计划然后再进行总结归纳。
没有distinct
执行语句
计算实验id、搜索精准类型维度下的资源曝光量
select exp_id
,exp_name
,server_is_intention_accurate_app
,sum(expose_nums) expose_nums
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and expose_nums > 0
group by exp_id
,exp_name
,server_is_intention_accurate_app
物理执行计划
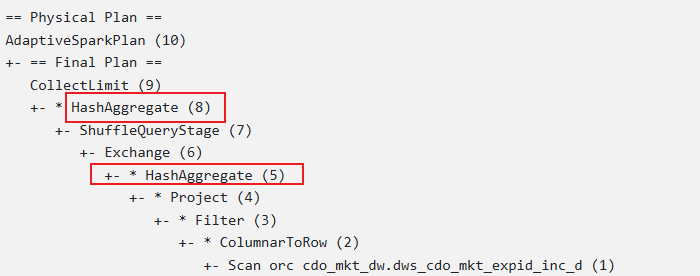
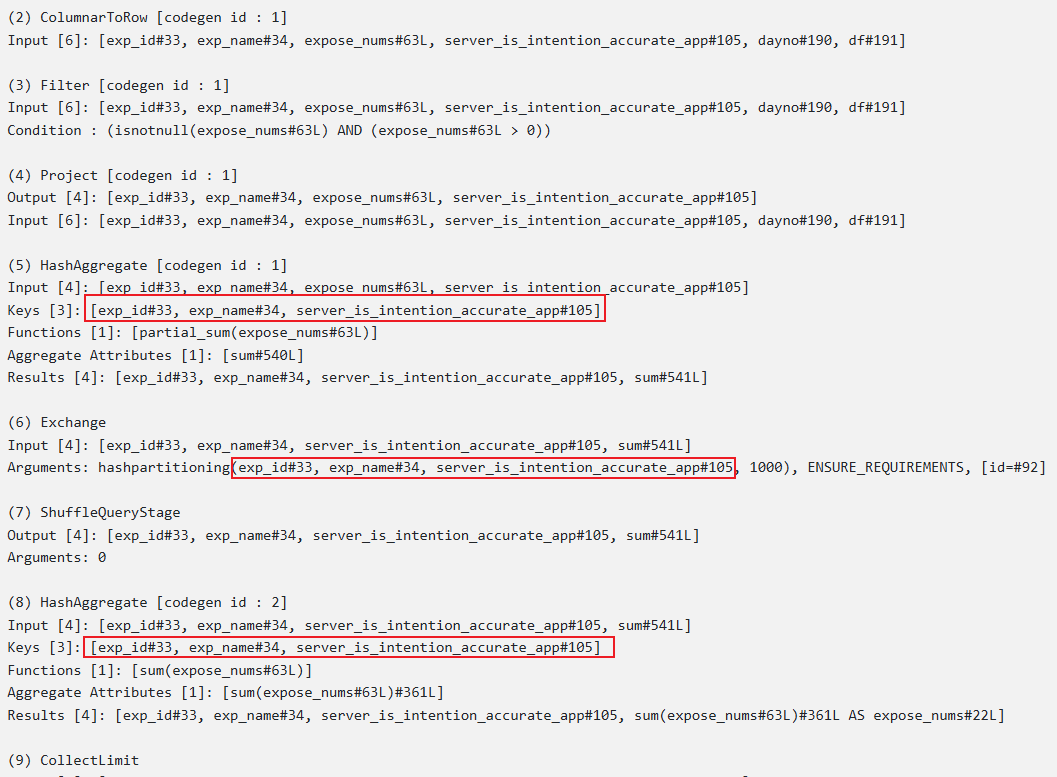
一个distinct
执行语句
计算实验id、搜索精准类型维度下的资源曝光量和uv
select exp_id,exp_name,server_is_intention_accurate_app
,sum(expose_nums) expose_nums
,count(distinct imei) users
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and expose_nums > 0
group by exp_id,exp_name,server_is_intention_accurate_app
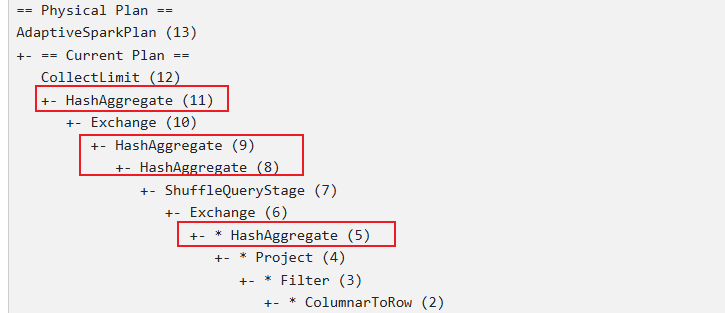
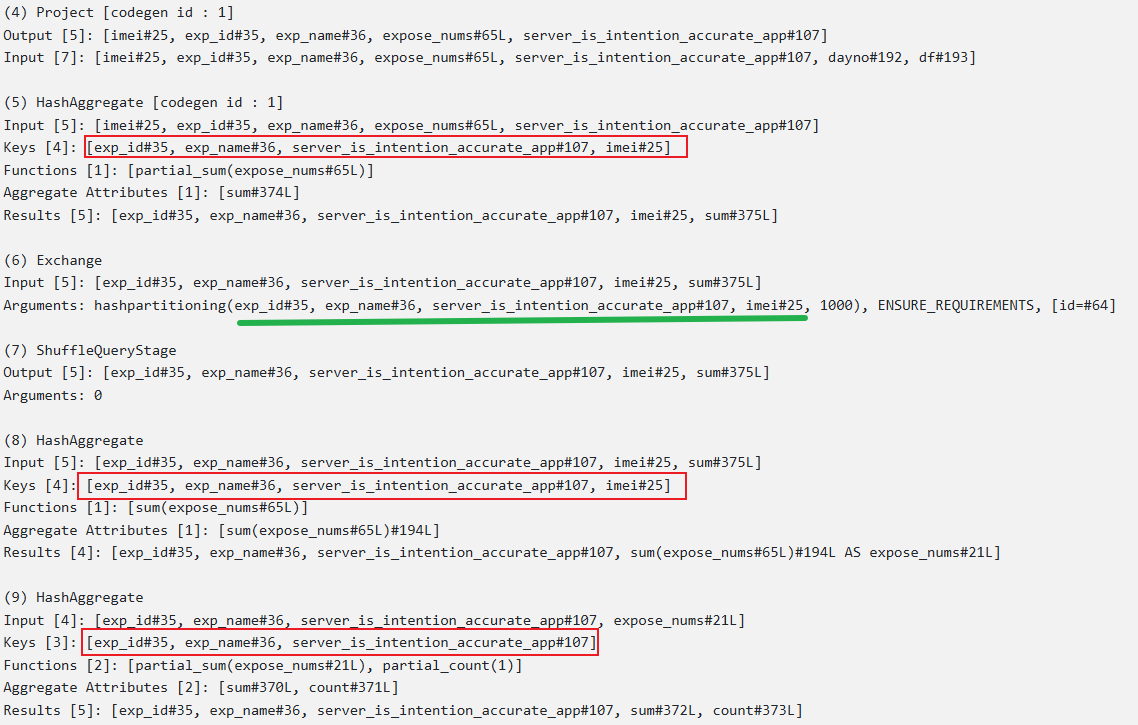
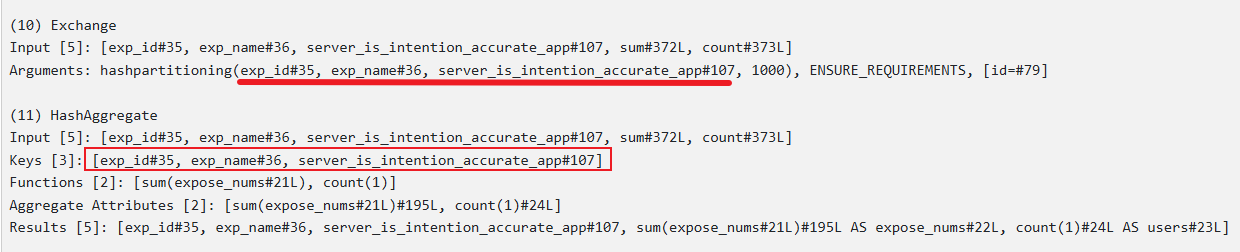
物理执行计划
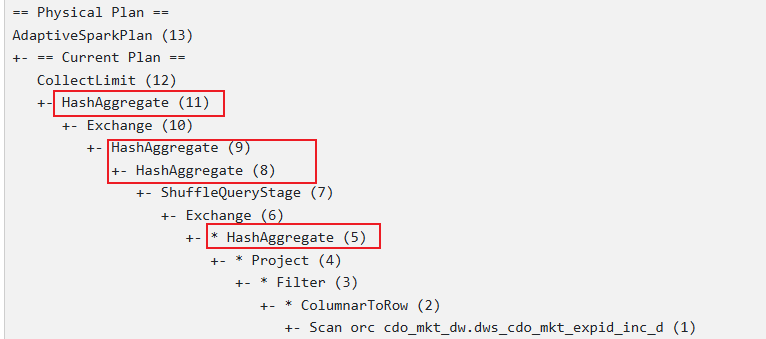
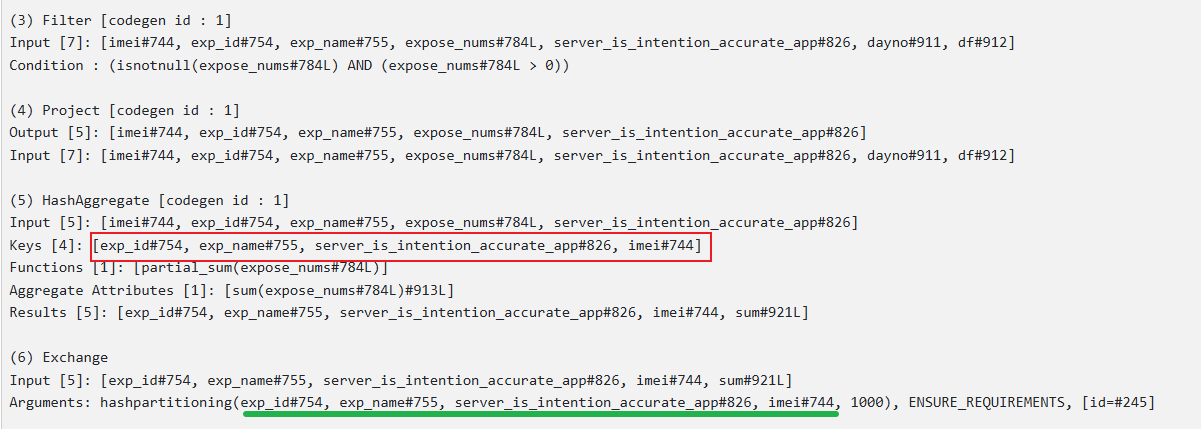

从物理执行计划可知当有一个distinct时,底层是通过两阶段聚合实现的,与下列语句的执行计划是一样的:
select exp_id,exp_name,server_is_intention_accurate_app
,sum(expose_nums) expose_nums
,count(1) users
from(
select exp_id,exp_name,server_is_intention_accurate_app
,imei
,sum(expose_nums) expose_nums
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and expose_nums > 0
group by exp_id,exp_name,server_is_intention_accurate_app
,imei
)t
group by exp_id,exp_name,server_is_intention_accurate_app
物理执行计划
多个distinct(对同一字段distinct,但条件不同)
执行语句
计算实验id、搜索精准类型维度下的资源曝光量、曝光uv、下载uv等
select exp_id
,exp_name
,server_is_intention_accurate_app
,sum(expose_nums) expose_nums
,count(distinct case when expose_nums > 0 then imei else null end) expose_uv
,count(distinct case when down_nums > 0 then imei else null end) down_uv
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and (expose_nums > 0 or down_nums > 0)
group by exp_id
,exp_name
,server_is_intention_accurate_app
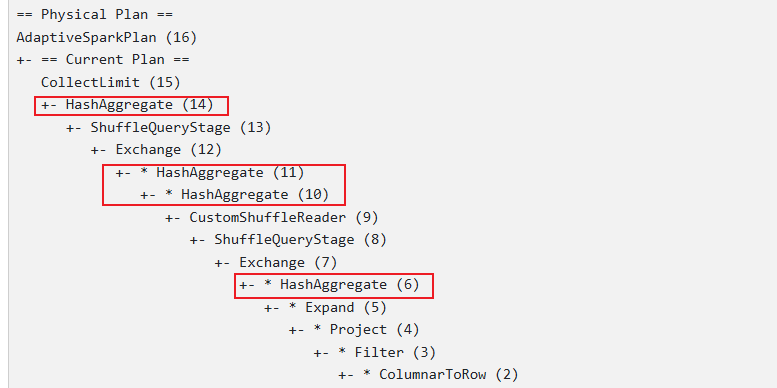
物理执行计划
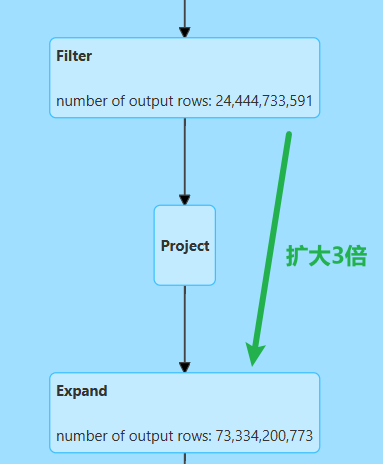
[ArrayBuffer(exp_id#824, exp_name#825, server_is_intention_accurate_app#896, null, null, 0, expose_nums#854L),
ArrayBuffer(exp_id#824, exp_name#825, server_is_intention_accurate_app#896, CASE WHEN (down_nums#856L > 0) THEN imei#814 ELSE null END, null, 1, null),
ArrayBuffer(exp_id#824, exp_name#825, server_is_intention_accurate_app#896, null, CASE WHEN (expose_nums#854L > 0) THEN imei#814 ELSE null END, 2, null)]
从上述物理执行计划可知当对不同条件单同一字段distinct时,底层也是通过两阶段聚合实现的,与下列语句的执行近似等效:
select exp_id,exp_name,server_is_intention_accurate_app
,sum(if(gid=0,expose_nums,0)) expose_nums
,count(if(gid=1,expose_imei,null)) expose_uv
,count(if(gid=2,down_imei,null)) down_uv
from(
select exp_id,exp_name,server_is_intention_accurate_app,expose_imei
,down_imei,gid,sum(expose_nums) expose_nums
from(
select exp_id,exp_name,server_is_intention_accurate_app
,expose_nums
,null expose_imei
,null down_imei
,0 gid
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and (expose_nums > 0 or down_nums > 0)
union all
select exp_id,exp_name,server_is_intention_accurate_app
,0 expose_nums
,if(expose_nums >0,imei,null) expose_imei
,null down_imei
,1 gid
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and (expose_nums > 0 or down_nums > 0)
union all
select exp_id,exp_name,server_is_intention_accurate_app
,0 expose_nums
,null expose_imei
,if(down_nums >0,imei,null) down_imei
,2 gid
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and (expose_nums > 0 or down_nums > 0)
)
group by exp_id,exp_name,server_is_intention_accurate_app,expose_imei,down_imei,gid
)t
group by exp_id,exp_name,server_is_intention_accurate_app
多个distinct(对不同字段 distinct)
执行语句
计算实验id、搜索精准类型维度下的资源曝光量、曝光uv、曝光请求数等
select exp_id,exp_name,server_is_intention_accurate_app
,sum(expose_nums) expose_nums
,count(distinct imei) users
,count(distinct req_id) req_uv
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and expose_nums > 0
group by exp_id,exp_name,server_is_intention_accurate_app
物理执行计划
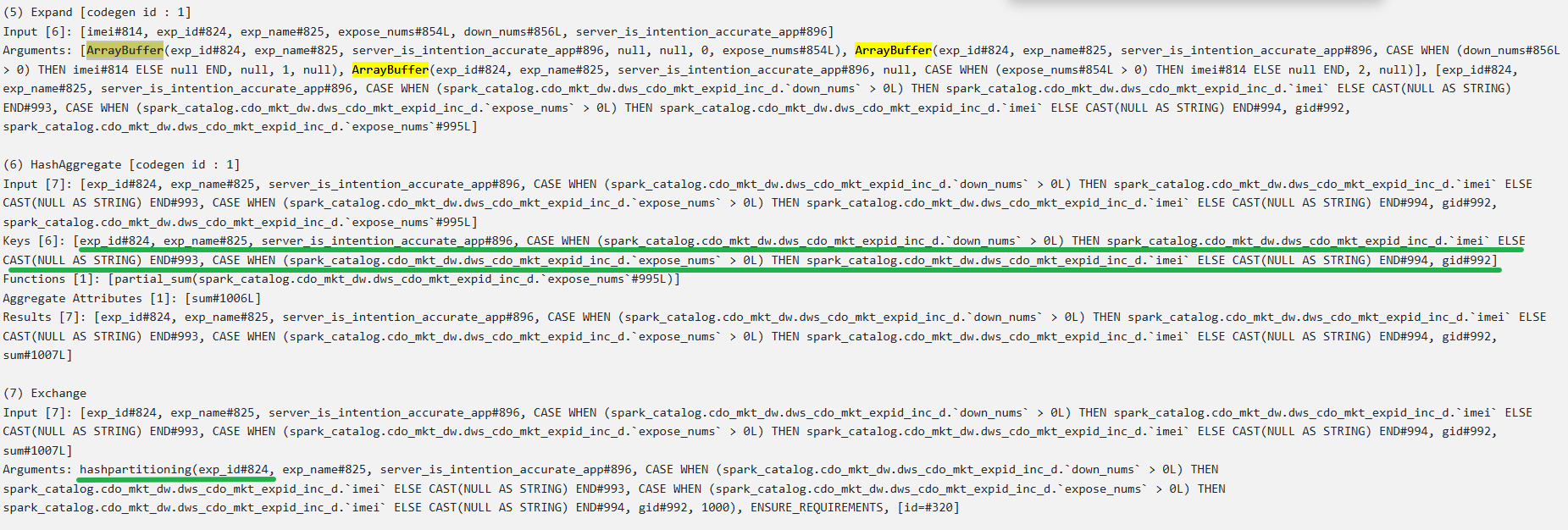
(5) Expand [codegen id : 1]
Input [6]: [imei#390, req_id#391, exp_id#400, exp_name#401, expose_nums#430L, server_is_intention_accurate_app#472]
Arguments: [ArrayBuffer(exp_id#400, exp_name#401, server_is_intention_accurate_app#472, null, null, 0, expose_nums#430L),
ArrayBuffer(exp_id#400, exp_name#401, server_is_intention_accurate_app#472, imei#390, null, 1, null),
ArrayBuffer(exp_id#400, exp_name#401, server_is_intention_accurate_app#472, null, req_id#391, 2, null)]
从物理执行计划可知当对不同字段distinct时,底层依旧是通过两阶段聚合实现的,与下列语句的执行近似等效:
select exp_id,exp_name,server_is_intention_accurate_app
,sum(if(gid=0,expose_nums,0)) expose_nums
,count(if(gid=1,imei,null)) users
,count(if(gid=2,req_id,null)) req_uv
from(
select exp_id,exp_name,server_is_intention_accurate_app,imei,req_id,gid,sum(expose_nums)
from(
select exp_id,exp_name,server_is_intention_accurate_app
, expose_nums
,null imei
,null req_id
,0 gid
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and expose_nums > 0
union all
select exp_id,exp_name,server_is_intention_accurate_app
,0 expose_nums
,imei
,null req_id
,1 gid
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and expose_nums > 0
union all
select exp_id,exp_name,server_is_intention_accurate_app
,0 expose_nums
,null imei
,req_id
,2 gid
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and expose_nums > 0
)
group by exp_id,exp_name,server_is_intention_accurate_app,imei,req_id,gid
)t
group by exp_id,exp_name,server_is_intention_accurate_app
distinct执行计划总结
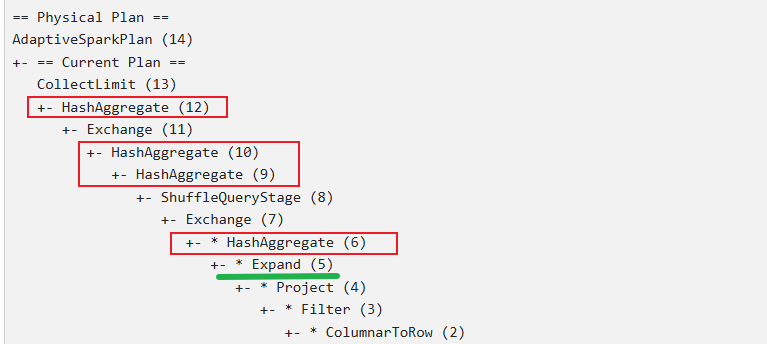
综上,通过分析各种不同distinct语句的物理执行计划,可知spark 对于多次distinct去重逻辑并没有制定专门的执行计划,而是巧妙地将每个distinct计算利用group by +count实现,最终整体通过两次shuffle达到去重目标。整个过程包含了四个核心步骤:
步骤一:Expand
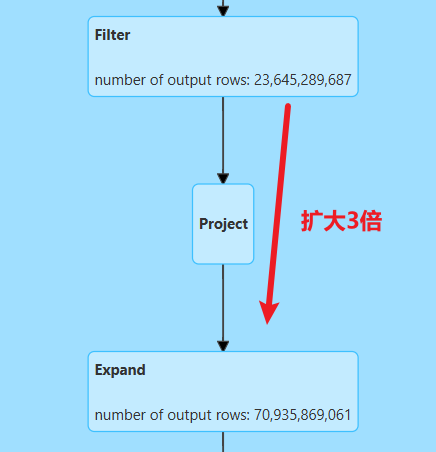
为了实现这个转换,spark首先会将原始数据进行Expand,即数据膨胀操作,膨胀的倍数=普通聚合数+distinct去重个数(1+N)。具体来说,会为所有的普通聚合生成一个副本,每一个distinct去重生成一个副本,并新增一个gid字段予以区分。
在上述统计曝光人数和曝光请求的例子中:
① gid=0:用于计算普通聚合sum(expose_nums)的副本;
② gid=1:用于计算count(distinct imei)的副本;
③ gid=2:用于计算count(distinct req_id)的副本;
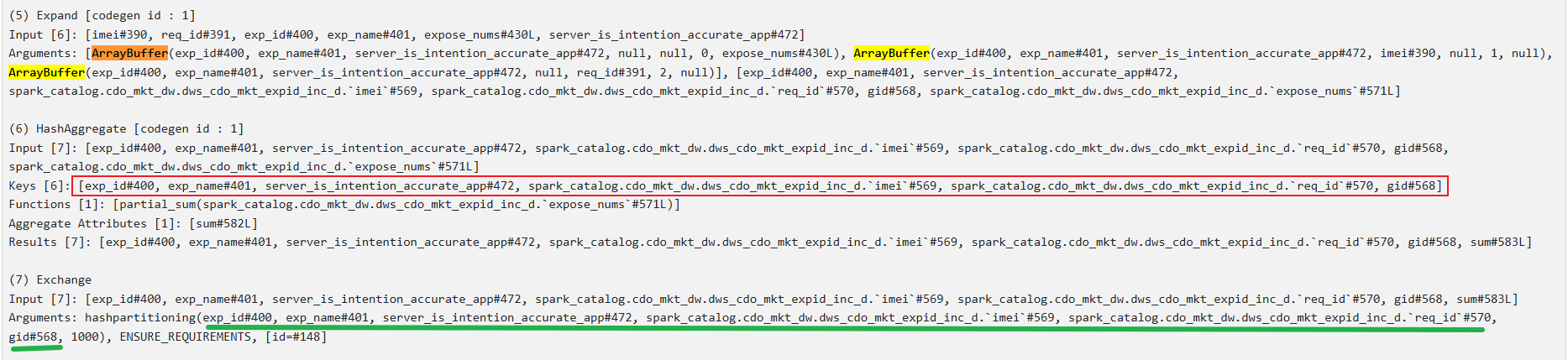
(5) Expand [codegen id : 1]
Input [6]: [imei#390, req_id#391, exp_id#400, exp_name#401, expose_nums#430L, server_is_intention_accurate_app#472]
Arguments: [ArrayBuffer(exp_id#400, exp_name#401, server_is_intention_accurate_app#472, null, null, 0, expose_nums#430L),
ArrayBuffer(exp_id#400, exp_name#401, server_is_intention_accurate_app#472, imei#390, null, 1, null),
ArrayBuffer(exp_id#400, exp_name#401, server_is_intention_accurate_app#472, null, req_id#391, 2, null)]
数据case如下:
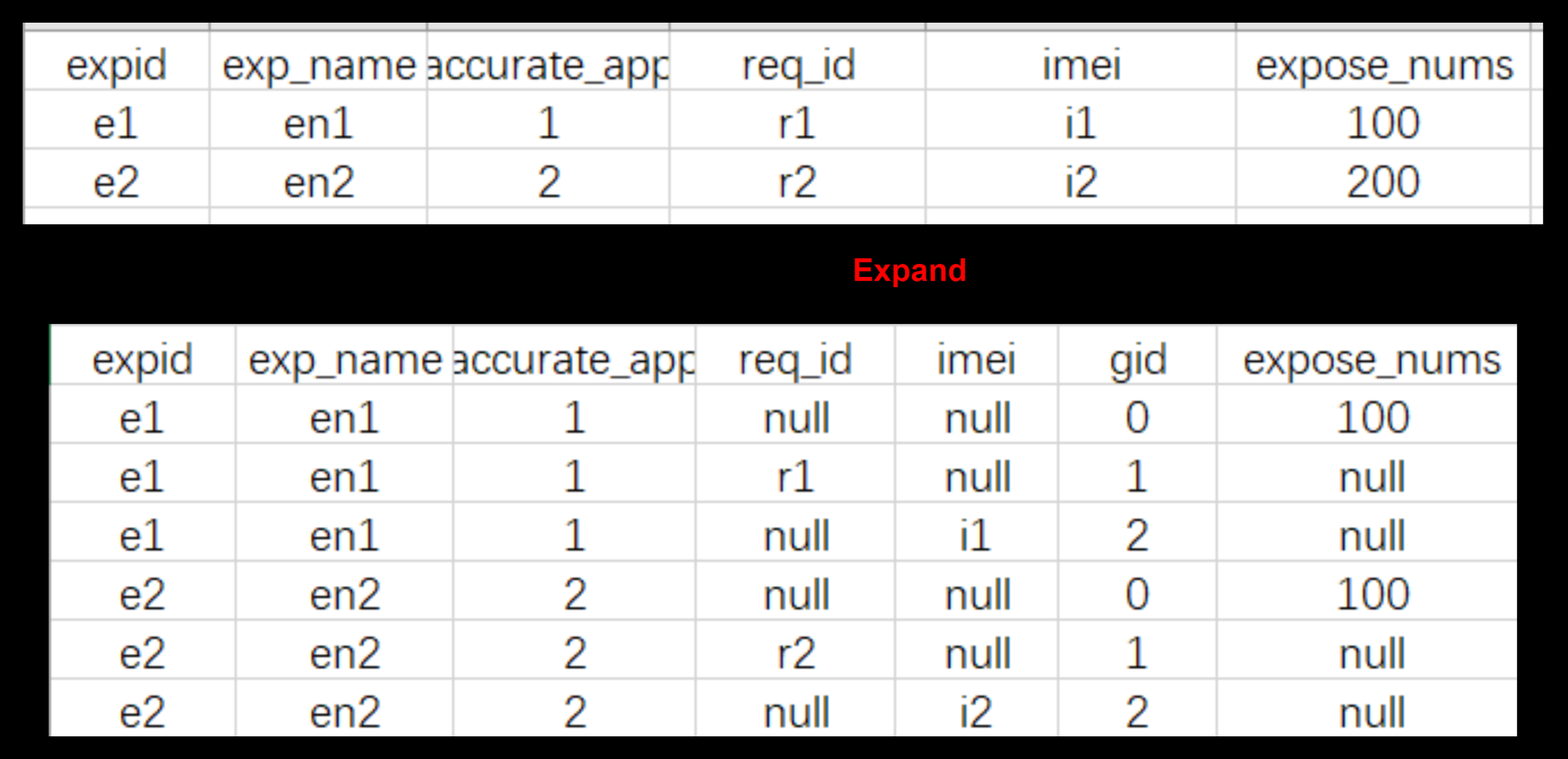
这样操作的目的是用空间换时间,将普通聚合计算与各distinct计算解耦到了不同的数据行上,这样后续每个distinct计算都能基于group by +count实现。
步骤二:本地预聚合
为减少shuffle数据量,使用聚合算子时spark会提前在Map端进行预聚合。
聚合的key是所有聚合维度、所有要distinct去重列以及gid,执行普通聚合函数(如sum、count、max等);这样可实现① 普通聚合的初步聚合;② 要去重数据的初步去重。
(6) HashAggregate [codegen id : 1]
Keys [6]: [exp_id#400, exp_name#401, server_is_intention_accurate_app#472, spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`imei`#569, spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`req_id`#570, gid#568]
Functions [1]: [partial_sum(spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`expose_nums`#571L)]
步骤三:首次Shuffle后两次聚合
根据上述聚合key(所有聚合维度、所有要distinct去重列以及gid)数据被重分区,确保相同的 Key 被发送到同一个 Executor
(7) Exchange
Input [7]: [exp_id#400, exp_name#401, server_is_intention_accurate_app#472, spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`imei`#569, spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`req_id`#570, gid#568, sum#583L]
Arguments: hashpartitioning(exp_id#400, exp_name#401, server_is_intention_accurate_app#472, spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`imei`#569, spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`req_id`#570, gid#568, 1000), ENSURE_REQUIREMENTS, [id=#148]
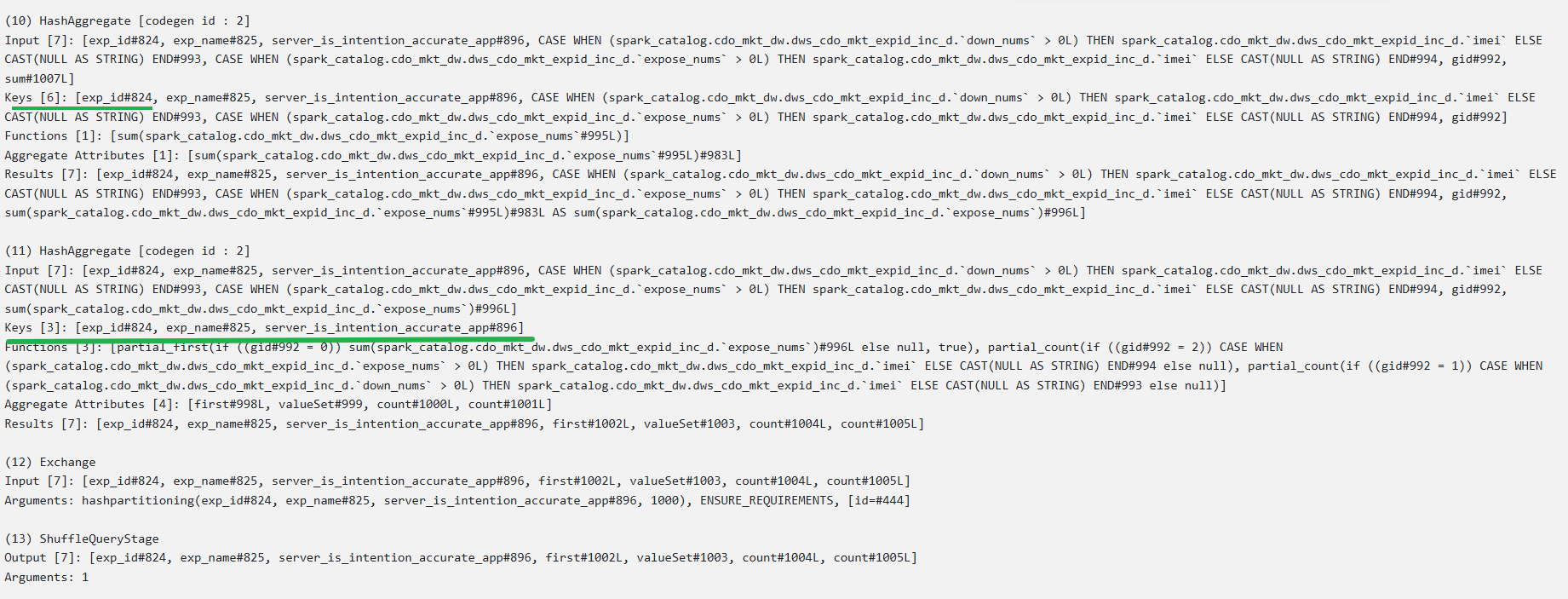
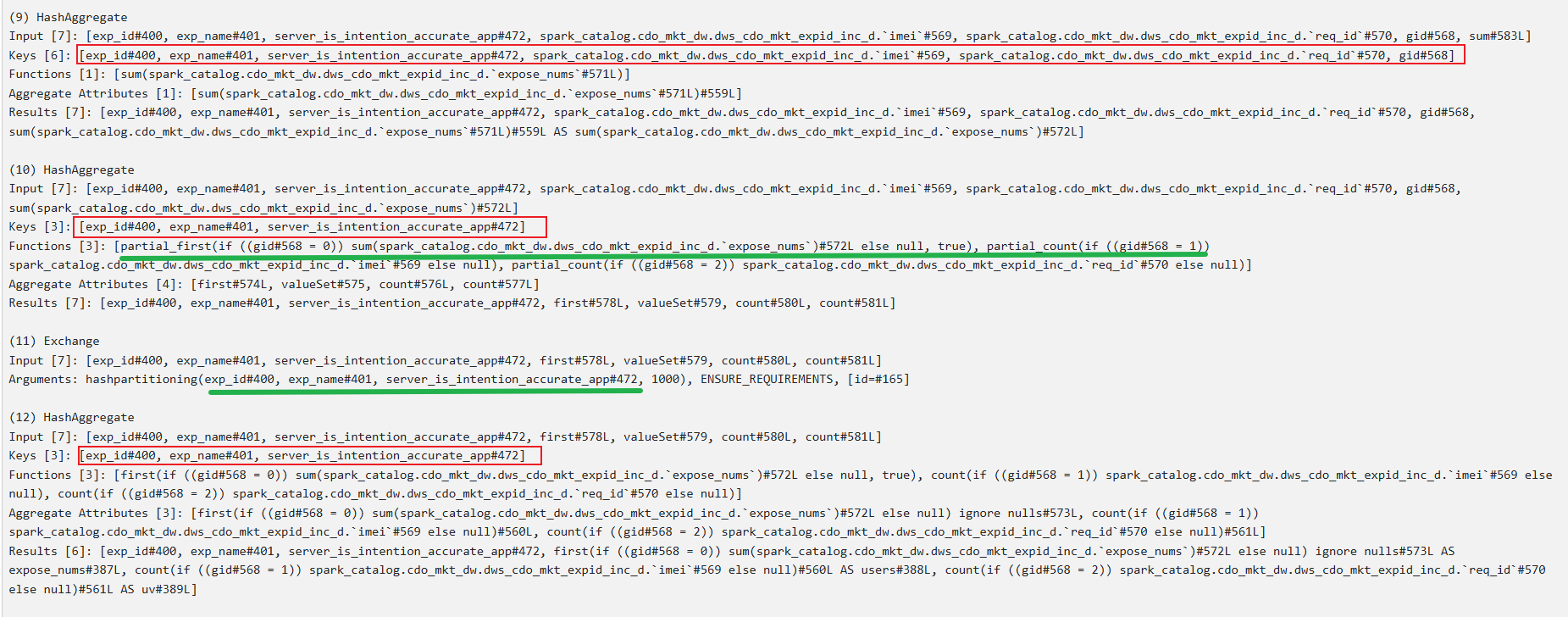
① 第一次聚合:同样以(所有聚合维度、所有要distinct去重列以及gid)为key进行聚合,对拉取的所有上游分区数据再次进行① 普通聚合;② 要去重数据的去重
Keys [6]: [exp_id#400, exp_name#401, server_is_intention_accurate_app#472, spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`imei`#569, spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`req_id`#570, gid#568]
Functions [1]: [sum(spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`expose_nums`#571L)]
② 第二次聚合:以要聚合维度为key,根据gid对相应要distinct去重的字段进行count计数;
Keys [3]: [exp_id#400, exp_name#401, server_is_intention_accurate_app#472]
Functions [3]: [partial_first(if ((gid#568 = 0)) sum(spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`expose_nums`)#572L else null, true), partial_count(if ((gid#568 = 1)) spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`imei`#569 else null), partial_count(if ((gid#568 = 2)) spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`req_id`#570 else null)]
步骤四:二次Shuffle最终聚合
经过前三步,各excutor的数据都已经被去重和预计算好了,最后只需将所有分区的结果进行收尾聚合。
(12) Exchange
Input [7]: [exp_id#400, exp_name#401, server_is_intention_accurate_app#472, first#578L, valueSet#579, count#580L, count#581L]
Arguments: hashpartitioning(exp_id#400, exp_name#401, server_is_intention_accurate_app#472, 1000), ENSURE_REQUIREMENTS, [id=#526]
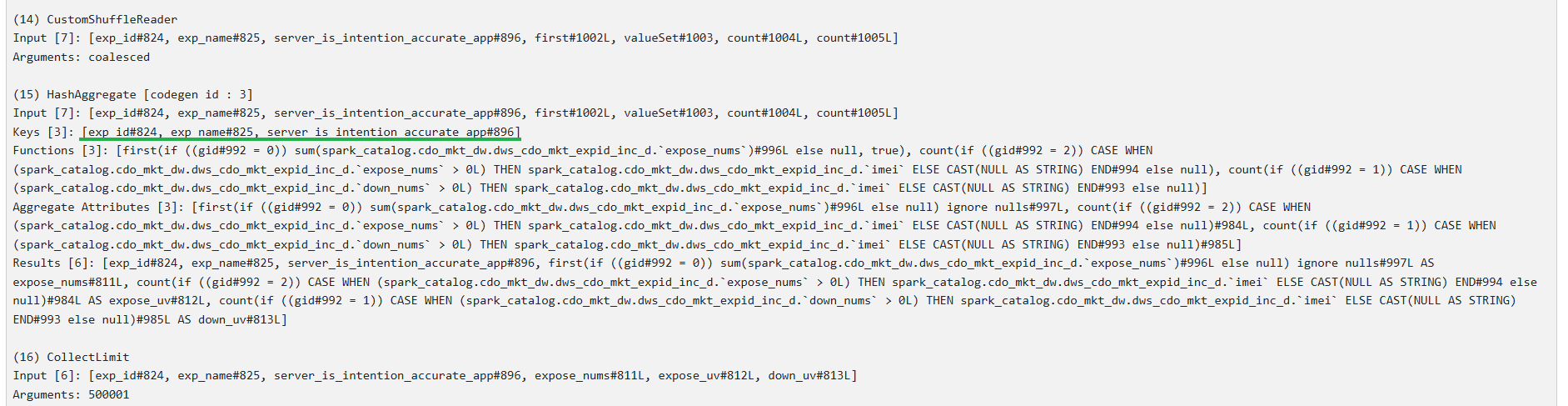
(15) HashAggregate [codegen id : 3]
Input [7]: [exp_id#400, exp_name#401, server_is_intention_accurate_app#472, first#578L, valueSet#579, count#580L, count#581L]
Keys [3]: [exp_id#400, exp_name#401, server_is_intention_accurate_app#472]
Functions [3]: [first(if ((gid#568 = 0)) sum(spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`expose_nums`)#572L else null, true), count(if ((gid#568 = 1)) spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`imei`#569 else null), count(if ((gid#568 = 2)) spark_catalog.cdo_mkt_dw.dws_cdo_mkt_expid_inc_d.`req_id`#570 else null)]
distinct性能总结
根据上述spark sql distinct底层的物理执行原理,可以发现影响性能的关键点:① distinct去重数;② 首次shuffle的数据量
1、distinct去重数(N)会直接导致数据量按照对应数据翻倍(N),task计算量也随之翻倍(N);
2、shuffle的数据量一方面会受distinct去重数影响,还会受去重字段的基数影响。
① 如果去重字段基数小(如应用一二三级分类等),可以在本地预聚合阶段合并大量数据,减少shuffle量;
② 如果去重字段基数大(如imei、请求id),在本地预聚合时合并效果微乎其微,shuffle量依旧很大,严重影响后续流程。
后续可从以上两个方向进行优化。
distinct优化方向
1、 减少数据量输入(根本)
不管对于何种场景,从源头减少数据的读取量,这是最高效的优化手段。
2、改写SQL(关键)
1、场景1:对同一字段distinct,但条件不同
基于这种场景的特性,优化方向是避免expand,手段是通过count+group by替换count distinct。优化原理是将增大为distinct个数的多条数据只用1条数据表示,大大减少数据量。
以上面的例子为例:
select exp_id,exp_name,server_is_intention_accurate_app
,sum(expose_nums) expose_nums
,count(distinct case when expose_nums > 0 then imei else null end) expose_uv
,count(distinct case when down_nums > 0 then imei else null end) down_uv
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and (expose_nums > 0 or down_nums > 0)
group by exp_id,exp_name,server_is_intention_accurate_app
– 改写后
select exp_id,exp_name,server_is_intention_accurate_app
,sum(expose_nums) expose_nums
,count(if(expose_flag > 0,imei,null)) expose_uv
,count(if(down_flag > 0,imei,null)) down_uv
from(
select exp_id,exp_name,server_is_intention_accurate_app
,imei
,sum(expose_nums) expose_nums
,sum(case when expose_nums > 0 then 1 else 0 end) expose_flag
,sum(case when down_nums > 0 then 1 else 0 end) down_flag
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and (expose_nums > 0 or down_nums > 0)
group by exp_id,exp_name,server_is_intention_accurate_app
,imei
)t
group by exp_id,exp_name,server_is_intention_accurate_app
case演示说明:
① 如果使用count(distinct),shuffle数据变为6条;
② 改写用group by +count,shuffle数据还是原来的2条;
由于源数据一定曝光>0的,但有曝光不一样有下载,因此减少的数据量含两部分:① 有下载的imei数据;② 聚合曝光的数据
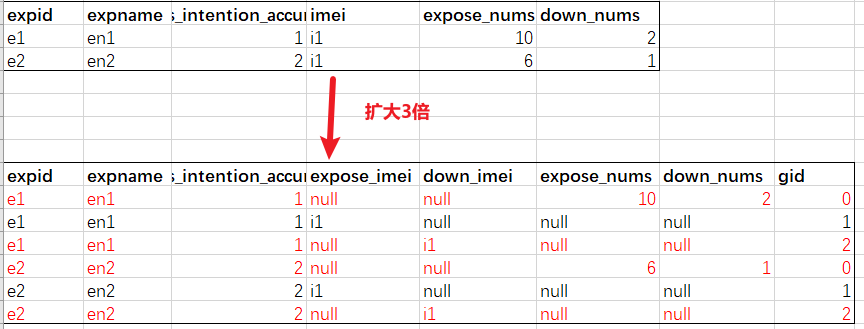
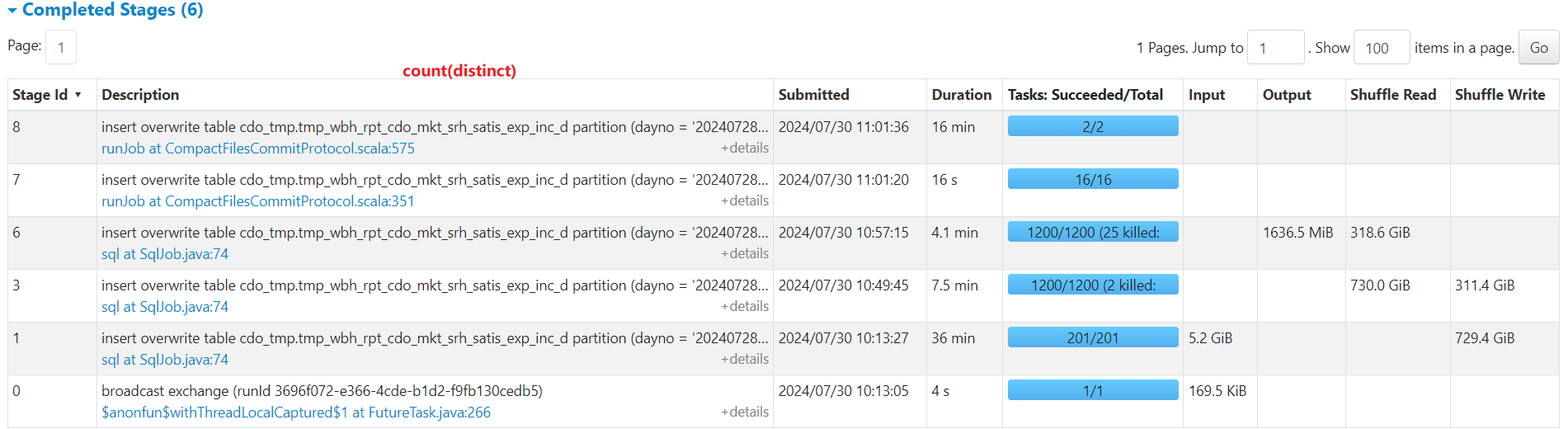
测试结果:配置参数相同情况下,改写后的shuffle量比count distinct的量少了3.3%,约7.6E,减少的量不多原因有两点:
① exp_id,exp_name,server_is_intention_accurate_app组合数较少,本地预聚合可以减少gid=0数据量;
② 有下载的imei数不多,即gid=2数量不多
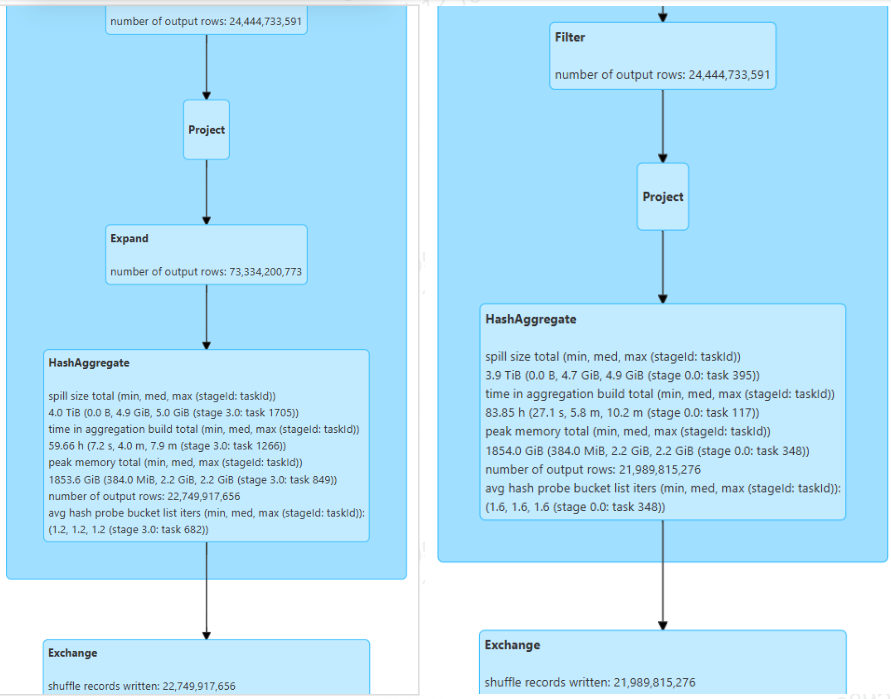
再看一个案例,对14种不同条件下的req_id去重,用count+group by 进行改写
,count(IF(direct_down_nums > 0,uniq_srh_req_id,null)) --有直接下载的搜索请求数
,count(IF(detail_down_nums > 0,uniq_srh_req_id,null)) --有详情下载的搜索请求数
,count(IF(open_nums > 0,uniq_srh_req_id,null)) --有打开应用的搜索请求数
...
对比结果:① shuffle数据量减少87.5%;① 任务总运行时间由原来的1个小时缩短到半小时。
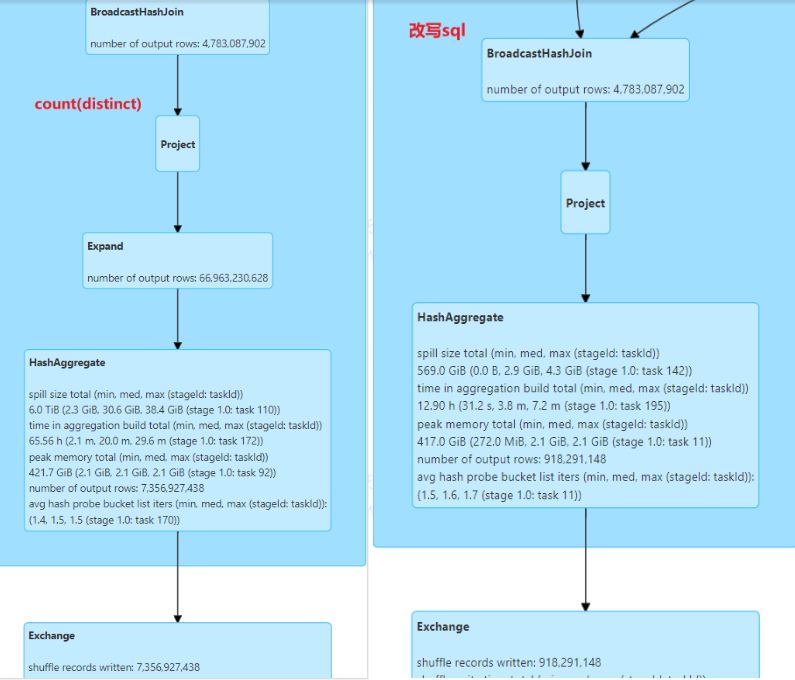
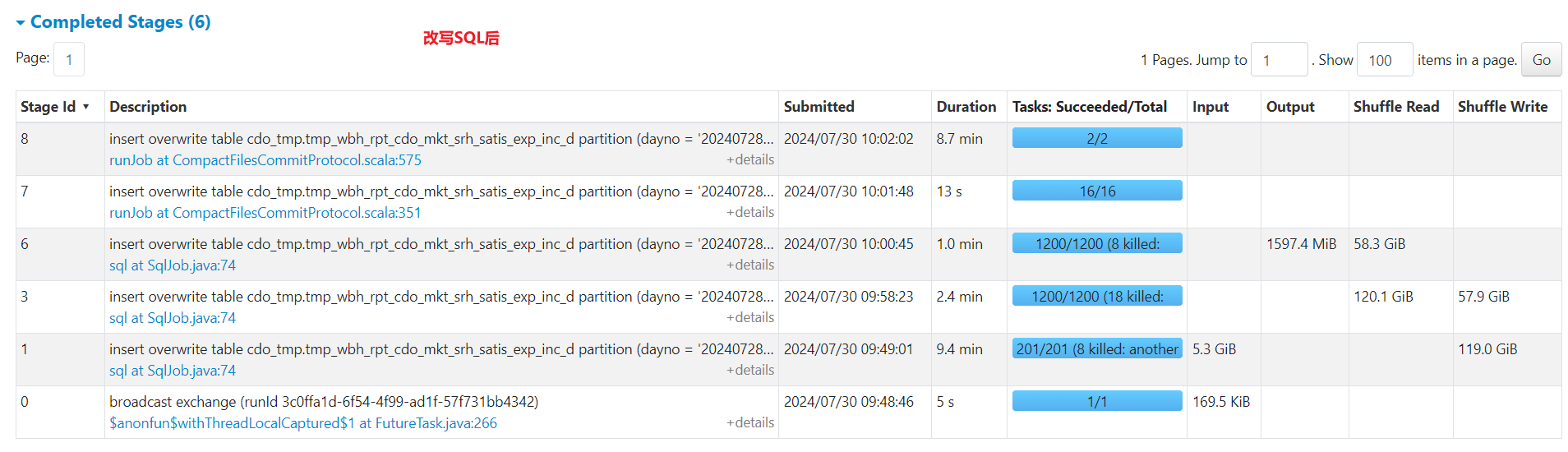
2、场景2:对不同字段distinct
优化思想:分而治之,使用union all或join方式
select exp_id,exp_name,server_is_intention_accurate_app
,sum(expose_nums) expose_nums
,count(distinct imei) users
,count(distinct req_id) req_uv
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and expose_nums > 0
group by exp_id,exp_name,server_is_intention_accurate_app
改写后
select exp_id,exp_name,server_is_intention_accurate_app
,sum(expose_nums) expose_nums
,count(if(flag='imei',distinct_col,null)) users
,count(if(flag='req_id',distinct_col,null)) req_uv
from(
select exp_id,exp_name,server_is_intention_accurate_app
,flag
,distinct_col
,sum(expose_nums) expose_nums
from(
select exp_id,exp_name,server_is_intention_accurate_app
,expose_nums
,'imei' flag
,imei distinct_col
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and expose_nums > 0
union all
select exp_id,exp_name,server_is_intention_accurate_app
,0 expose_nums
,'req_id' flag
,req_id distinct_col
from cdo_mkt_dw.dws_cdo_mkt_expid_inc_d
where dayno = '20251201'
and df = 'srh_mkt'
and expose_nums > 0
)t
group by exp_id,exp_name,server_is_intention_accurate_app,flag,distinct_col
)t1
group by exp_id,exp_name,server_is_intention_accurate_app
劣势:① 会多次扫描源表,扫描次数是去重字段数,IO开销会更大;② shuffle总数据量并不会比count distinct少;③ 若distinct个数过多,union all方式会使代码冗余。
优势:读取文件启动task数是count(distinct)的N倍(N代表去重字段数),本质就是将之前1个task要处理的数据量摊到N个task上,这样能减少每个Task的内存压力和GC时间,提高任务整体的稳定性。
当去重列基数较大时,count distinct执行语句每个task本地预聚合效果不会很好,内存压力会较大,可以尝试改写SQL方案对比两者性能差异。
3、设置参数(辅助)
在对不同字段distinct时,改写SQL可能并不会提升运行性能,这是可以设置一些参数提升性能:
① spark.sql.files.maxPartitionBytes。降低task读取源表数据量,生成更多 Task 来分担数据处理压力;
② spark.executor.memory。适当增加 Executor 的内存,有效避免 OOM。
③ spark.sql.shuffle.partitions。增加 Shuffle 的分区数,让更多 Task 来分担聚合压力;
④ spark.dynamicAllocation.maxExecutors。增加任务并发
设置参数的目的是启动更多task分担压力,但这会造成集群资源紧张,也会导致其它任务没有资源,不是最优解。
最后一句话总结:不要总是妄图调整参数进行调优,根据业务逻辑减少数据量才是根本,改写SQL是最有效措施。
参考
别再无脑用 COUNT DISTINCT 了!90%的 Spark 工程师都踩过这个坑
spark sql多维分析优化——细节是魔鬼
再来说说sparksql中count(distinct)原理和优化手段吧~
© 版权声明
文章版权归作者所有,未经允许请勿转载。


