
大数据时序数据库选型指南:架构设计、生态集成与实战案例
在大数据时代,时序数据已成为企业数据资产中的重要组成部分。据Gartner预测,到2027年,超过50%的企业将使用时序数据库来处理物联网和实时分析场景。面对市场上众多的时序数据库产品,如何选择成为技术决策者面临的重要挑战。本文将从架构设计、生态集成、性能指标等维度,深入探讨大数据环境下时序数据库的选型策略。
时序数据库在大数据架构中的核心地位
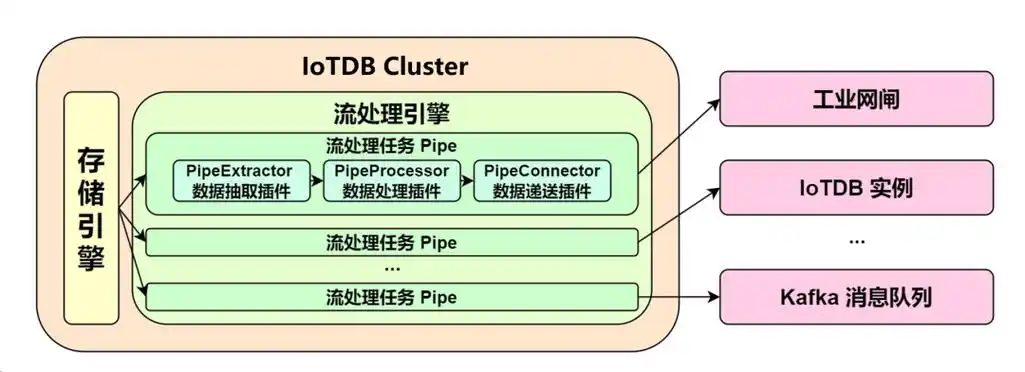
时序数据的爆发式增长
当前,全球每天产生超过50亿GB的时序数据,涵盖物联网设备监控、金融交易记录、业务运营指标等多个领域。这些数据具有鲜明的特点:数据量巨大、写入吞吐量高、时间相关性强的同时,还需要支持复杂的实时分析查询。
在大数据技术栈中,时序数据库承担着承上启下的关键作用:
[数据源] → [采集层] → [消息队列] → [时序数据库] → [分析引擎] → [应用层]大数据环境下的特殊挑战
数据规模挑战:某大型制造企业的物联网平台需要处理来自10万台设备的监控数据,每秒产生超过200万数据点,日增数据量达到TB级别。
查询复杂度挑战:金融风控场景需要在秒级内完成对数千个指标的时间窗口聚合分析,实时检测异常交易模式。
成本控制挑战:运营商网络监控系统需要保存18个月的历史数据以供合规审计,存储成本成为重要考量因素。
时序数据库架构设计深度解析

存储引擎架构对比
现代时序数据库的存储引擎主要分为以下几种架构:
LSM树架构:
-
优点:高写入吞吐,适合写多读少场景
-
缺点:读放大问题,压缩过程影响性能
-
适用场景:高频写入,批量查询
B+树架构:
-
优点:读性能稳定,支持复杂查询
-
缺点:写入性能有瓶颈
-
适用场景:读写均衡,事务要求高
列式存储架构:
-
优点:高压缩比,分析查询性能好
-
缺点:点查询性能较差
-
适用场景:批量分析,历史数据查询
以下是基于IoTDB的混合存储架构示例,结合了多种存储引擎的优势:
// 配置多级存储策略
StorageEngineConfig config = new StorageEngineConfig.Builder()
.setStorageGroup("root.industrial")
.setTtl(365 * 24 * 60 * 60 * 1000L) // 1年保留期
.setCompactionStrategy(CompactionStrategy.LEVELED)
.setMemoryTableSize(256 * 1024 * 1024) // 256MB内存表
.setBatchSize(10000) // 批量写入大小
.build();
// 创建时间序列时指定存储参数
String createSql = "CREATE TIMESERIES root.factory.machine1.temperature " +
"WITH DATATYPE=FLOAT, ENCODING=GORILLA, COMPRESSION=SNAPPY, " +
"STORAGE_GROUP=root.industrial";
session.executeNonQueryStatement(createSql);分布式架构设计
分布式时序数据库需要解决数据分片、负载均衡、一致性等核心问题。优秀的分片策略应该考虑以下因素:
-
时间范围分片:按时间区间划分数据,便于数据生命周期管理
-
设备维度分片:按设备ID哈希分片,保证设备数据局部性
-
混合分片策略:结合时间和设备维度,实现最优查询性能
以下是一个分布式IoTDB集群的配置示例:
# cluster-config.yml
cluster:
name: "iotdb-production"
replication_factor: 3
partition_interval: 7d # 按7天分片
data_replication:
strategy: "rack-aware"
default_replica_num: 3
node:
- id: "node1"
internal_ip: "192.168.1.101"
external_ip: "10.0.1.101"
data_dirs: ["/data1/iotdb", "/data2/iotdb"]
rack: "rack1"
- id: "node2"
internal_ip: "192.168.1.102"
external_ip: "10.0.1.102"
data_dirs: ["/data1/iotdb"]
rack: "rack2"数据模型设计最佳实践
合理的数据模型设计直接影响查询性能和存储效率。对于工业物联网场景,推荐使用层次化数据模型:
-- 创建设备层级结构
CREATE DATABASE root.factory.area1.production_line1;
-- 定义设备模板
CREATE DEVICE TEMPLATE motor_template (
temperature FLOAT encoding=GORILLA,
voltage FLOAT encoding=GORILLA,
current FLOAT encoding=GORILLA,
vibration FLOAT encoding=GORILLA,
status INT32 encoding=RLE
);
-- 应用模板到具体设备
SET DEVICE TEMPLATE motor_template TO root.factory.area1.production_line1.motor.*;
-- 插入数据时自动应用模板
INSERT INTO root.factory.area1.production_line1.motor001(timestamp, temperature, voltage)
VALUES (1635724800000, 75.5, 380.0);时序数据库生态集成能力评估
与大数据生态的深度集成
优秀的时序数据库应该能够无缝融入现有的大数据生态系统。以下是与主流大数据组件集成的示例:
与Apache Spark集成进行批量分析:
// 读取IoTDB数据创建DataFrame
val iotdbDF = spark.read
.format("org.apache.iotdb.spark.db")
.option("url", "jdbc:iotdb://127.0.0.1:6667/")
.option("sql", """
SELECT temperature, pressure, vibration
FROM root.factory.*
WHERE time > now() - 30d
""")
.load()
// 使用Spark ML进行设备故障预测
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.clustering.KMeans
val assembler = new VectorAssembler()
.setInputCols(Array("temperature", "pressure", "vibration"))
.setOutputCol("features")
val assembledData = assembler.transform(iotdbDF)
val kmeans = new KMeans().setK(3).setSeed(1L)
val model = kmeans.fit(assembledData)
// 保存预测结果回IoTDB
model.transform(assembledData)
.filter($"prediction" === 2) // 异常簇
.select($"timestamp", $"temperature", $"prediction")
.write
.format("org.apache.iotdb.spark.db")
.option("url", "jdbc:iotdb://127.0.0.1:6667/")
.option("device", "root.factory.anomaly")
.save()与Apache Flink集成实现流式处理:
public class IoTDBFlinkIntegration {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从Kafka读取设备数据
DataStream<SensorData> sensorStream = env
.addSource(new FlinkKafkaConsumer<>("sensor-data",
new SensorDataDeserializer(), properties))
.name("sensor-data-source");
// 实时计算设备健康指标
DataStream<DeviceHealth> healthStream = sensorStream
.keyBy(SensorData::getDeviceId)
.timeWindow(Time.minutes(5))
.process(new HealthScoreCalculator());
// 将健康指标写入IoTDB
healthStream.addSink(new IoTDBSink<>());
env.execute("Real-time Device Health Monitoring");
}
private static class HealthScoreCalculator
extends ProcessWindowFunction<SensorData, DeviceHealth, String, TimeWindow> {
@Override
public void process(String deviceId, Context context,
Iterable<SensorData> elements,
Collector<DeviceHealth> out) {
// 计算设备健康评分
double healthScore = calculateHealthScore(elements);
long windowEnd = context.window().getEnd();
out.collect(new DeviceHealth(deviceId, healthScore, windowEnd));
}
}
}可视化与监控集成
时序数据需要强大的可视化工具支持,以下是通过Grafana展示IoTDB数据的完整示例:
# docker-compose.yml 配置Grafana和IoTDB
version: '3.8'
services:
iotdb:
image: apache/iotdb:0.13.0
ports:
- "6667:6667"
- "8086:8086"
volumes:
- ./data/iotdb:/iotdb/data
grafana:
image: grafana/grafana:8.3.0
ports:
- "3000:3000"
environment:
- GF_INSTALL_PLUGINS=grafana-clock-panel,grafana-simple-json-datasource
volumes:
- ./grafana/provisioning:/etc/grafana/provisioning配置Grafana数据源:
{
"name": "IoTDB",
"type": "iotdb",
"url": "http://iotdb:8086",
"access": "proxy",
"isDefault": true,
"jsonData": {
"timeInterval": "10s",
"queryTimeout": "300s",
"maxSeries": 1000
}
}创建设备监控仪表板:
-- 设备实时状态查询
SELECT
temperature, pressure, vibration,
CASE WHEN temperature > 80 THEN '警告'
WHEN temperature > 90 THEN '危险'
ELSE '正常' END as status
FROM root.factory.area1.*
WHERE time > now() - 1h
LIMIT 1000
-- 设备健康趋势分析
SELECT
MOVING_AVERAGE(temperature, 10) as temp_trend,
DEVIATION(vibration, 60) as vib_stddev
FROM root.factory.area1.motor001
WHERE time > now() - 7d
GROUP BY(1h)性能基准测试与方法论
测试环境搭建
构建科学的性能测试环境需要考虑以下要素:
-
硬件配置:CPU、内存、存储类型(SSD/HDD)、网络带宽
-
数据特征:时间序列数量、数据点频率、数据类型分布
-
工作负载:写入模式、查询类型、并发用户数
以下是一个完整的基准测试框架示例:
# benchmark_framework.py
import time
import statistics
from concurrent.futures import ThreadPoolExecutor
from iotdb.Session import Session
from iotdb.utils.Tablet import Tablet
class IoTDBBenchmark:
def __init__(self, host, port, username, password):
self.session = Session(host, port, username, password)
self.session.open(False)
def write_throughput_test(self, device_count, points_per_device):
"""写入吞吐量测试"""
start_time = time.time()
with ThreadPoolExecutor(max_workers=10) as executor:
futures = []
for device_id in range(device_count):
future = executor.submit(self.write_device_data,
device_id, points_per_device)
futures.append(future)
# 等待所有写入完成
for future in futures:
future.result()
duration = time.time() - start_time
total_points = device_count * points_per_device
throughput = total_points / duration
return {
"total_points": total_points,
"duration": duration,
"throughput": throughput,
"points_per_second": throughput
}
def query_latency_test(self, query_templates, query_count):
"""查询延迟测试"""
latencies = []
for i in range(query_count):
template = query_templates[i % len(query_templates)]
query = template.format(offset=i)
start_time = time.time()
result = self.session.execute_query_statement(query)
# 遍历结果确保查询完成
while result.has_next():
result.next()
latency = (time.time() - start_time) * 1000 # 转毫秒
latencies.append(latency)
result.close()
return {
"avg_latency": statistics.mean(latencies),
"p95_latency": statistics.quantiles(latencies, n=20)[18],
"p99_latency": statistics.quantiles(latencies, n=100)[98],
"min_latency": min(latencies),
"max_latency": max(latencies)
}关键性能指标解读
写入性能指标:
-
单节点写入吞吐量:衡量系统处理实时数据的能力
-
批量写入延迟:影响数据可见性的关键指标
-
并发写入稳定性:高并发下的性能表现
查询性能指标:
-
点查询延迟:单个数据点的查询响应时间
-
范围查询吞吐量:时间窗口内的数据扫描能力
-
聚合查询性能:统计分析的执行效率
资源利用率指标:
-
CPU/内存使用率:系统资源消耗情况
-
存储压缩比:数据存储效率的体现
-
网络带宽占用:分布式环境下的关键指标
行业实战案例深度分析

智能制造时序数据平台
某大型汽车制造商构建了基于IoTDB的智能制造数据平台,实现了以下功能:
数据架构设计:
-- 工厂层级数据模型
CREATE DATABASE root.plant.body_shop.welding_line;
-- 设备监控时序定义
CREATE TIMESERIES root.plant.body_shop.welding_line.robot001.`welding-current`
WITH DATATYPE=FLOAT, ENCODING=GORILLA, COMPRESSION=SNAPPY;
CREATE TIMESERIES root.plant.body_shop.welding_line.robot001.`motor-temperature`
WITH DATATYPE=FLOAT, ENCODING=GORILLA, COMPRESSION=SNAPPY;实时质量控制分析:
public class QualityMonitor {
private Session session;
public void startRealTimeMonitoring() {
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
scheduler.scheduleAtFixedRate(this::checkWeldingQuality, 0, 1, TimeUnit.SECONDS);
}
private void checkWeldingQuality() {
String sql = "SELECT " +
"welding_current, motor_temperature, " +
"STATEFROMTEXT(welding_current, '正常状态:(-∞,200];异常状态:(200,+∞)') as current_state, " +
"TIMEDIFFERENCE(current_state) as state_duration " +
"FROM root.plant.body_shop.welding_line.robot001 " +
"WHERE time > now() - 5s";
try (SessionDataSet result = session.executeQueryStatement(sql)) {
while (result.hasNext()) {
RowRecord record = result.next();
float current = record.getFields().get(0).getFloatV();
float temperature = record.getFields().get(1).getFloatV();
String state = record.getFields().get(2).getBinaryV().toString();
long duration = record.getFields().get(3).getLongV();
if ("异常状态".equals(state) && duration > 3000) {
triggerAlarm("焊接电流异常持续超过3秒");
}
}
}
}
}实施效果:
-
数据点处理能力:500万点/秒
-
查询响应时间:<100毫秒(P95)
-
存储成本降低:68%
-
设备故障预测准确率:92%
智慧城市交通监控平台
某特大城市交通管理部门使用时序数据库构建交通流量分析平台:
-- 交通流量数据模型
CREATE DATABASE root.traffic.highway;
-- 创建交通检测器模板
CREATE DEVICE TEMPLATE traffic_detector (
vehicle_count INT64 encoding=TS_2DIFF,
avg_speed FLOAT encoding=GORILLA,
occupancy_rate FLOAT encoding=GORILLA,
vehicle_type MAP<STRING, INT64> encoding=PLAIN
);
SET DEVICE TEMPLATE traffic_detector TO root.traffic.highway.*.detector*;实时交通流分析:
# 交通拥堵检测算法
class TrafficCongestionDetector:
def __init__(self, session):
self.session = session
def detect_congestion(self, road_segment):
"""检测交通拥堵状态"""
sql = f"""
SELECT
vehicle_count,
avg_speed,
occupancy_rate,
ZSCORE(avg_speed, 300) over (RANGE 5m PRECEDING) as speed_zscore,
MOVING_AVERAGE(vehicle_count, 10) as traffic_trend
FROM root.traffic.highway.{road_segment}.detector001
WHERE time > now() - 10m
"""
result = self.session.execute_query_statement(sql)
congestion_levels = []
while result.has_next():
record = result.next()
speed = record.get_fields()[1].get_float_v()
occupancy = record.get_fields()[2].get_float_v()
zscore = record.get_fields()[3].get_float_v()
trend = record.get_fields()[4].get_float_v()
# 基于多指标的综合拥堵判断
level = self.calculate_congestion_level(speed, occupancy, zscore, trend)
congestion_levels.append(level)
return statistics.mode(congestion_levels) if congestion_levels else 0
def calculate_congestion_level(self, speed, occupancy, zscore, trend):
"""计算拥堵等级"""
score = 0
if speed < 20:
score += 3
elif speed < 40:
score += 2
elif speed < 60:
score += 1
if occupancy > 0.8:
score += 2
elif occupancy > 0.6:
score += 1
if zscore < -2:
score += 2
if trend > 1.5:
score += 1
return min(score // 2, 4) # 返回0-4的拥堵等级选型实施路径与最佳实践
四阶段选型方法论
阶段一:需求分析与技术评估
# 需求评估清单
requirements_checklist = {
"数据规模": {
"时间序列数量": "10万+",
"每日数据点": "10亿+",
"保留周期": "2年"
},
"性能要求": {
"写入吞吐量": "100万点/秒",
"查询延迟": "<100ms",
"并发用户": "500+"
},
"功能需求": {
"SQL支持": "是",
"聚合函数": "丰富",
"数据导出": "需要"
}
}阶段二:概念验证(PoC)实施
构建包含以下测试项目的PoC方案:
-
性能测试:写入吞吐量、查询延迟、并发能力
-
功能验证:SQL兼容性、数据模型支持、管理功能
-
生态集成:与现有大数据组件集成验证
阶段三:生产部署规划
# 生产环境部署规划
deployment_plan:
cluster_size: 6节点
replication: 3副本
storage_estimation: 100TB/年
backup_strategy:
full_backup: 每周
incremental_backup: 每日
retention: 1个月
monitoring:
metrics: [cpu, memory, disk, query_latency]
alert_rules:
- high_cpu_usage: ">80%持续5分钟"
- slow_queries: "P95>500ms"阶段四:迁移与上线
制定详细的数据迁移方案:
public class DataMigrationTool {
public void migrateFromLegacySystem(String sourceConfig, String targetConfig) {
// 1. 元数据迁移
migrateSchema(sourceConfig, targetConfig);
// 2. 历史数据迁移(分批进行)
migrateHistoricalData(sourceConfig, targetConfig,
LocalDateTime.of(2020, 1, 1, 0, 0),
LocalDateTime.now());
// 3. 双写过渡期
startDualWrite(sourceConfig, targetConfig, Duration.ofDays(7));
// 4. 流量切换
switchTrafficToNewSystem(targetConfig);
// 5. 数据一致性验证
validateDataConsistency(sourceConfig, targetConfig);
}
}运维监控体系构建
建立完善的监控体系是保证时序数据库稳定运行的关键:
# prometheus监控配置
scrape_configs:
- job_name: 'iotdb'
static_configs:
- targets: ['iotdb-node1:9091', 'iotdb-node2:9091']
metrics_path: '/metrics'
scrape_interval: 15s
- job_name: 'iotdb-cluster'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_app]
action: keep
regex: iotdb
# 告警规则配置
groups:
- name: iotdb-alerts
rules:
- alert: HighWriteLatency
expr: rate(iotdb_write_latency_seconds_sum[5m]) > 0.1
for: 5m
labels:
severity: warning
annotations:
summary: "写入延迟过高"
- alert: NodeDown
expr: up{job="iotdb"} == 0
for: 2m
labels:
severity: critical
annotations:
summary: "IoTDB节点宕机"总结与展望

时序数据库作为大数据生态中的重要组成部分,在物联网、金融科技、智能制造等领域发挥着越来越重要的作用。通过本文的深入分析,我们可以得出以下结论:
选型关键要点总结
-
架构匹配度:根据数据规模和访问模式选择合适的存储架构
-
性能可扩展性:确保系统能够随着业务增长线性扩展
-
生态完整性:评估与现有大数据技术的集成能力
-
运维成本:考虑系统维护难度和总体拥有成本
技术发展趋势
未来时序数据库技术将呈现以下发展趋势:
AI原生时序数据库:内置机器学习算法,支持实时异常检测和预测分析
云原生架构:基于Kubernetes的弹性扩缩容,Serverless计算模式
时序数据湖:统一批流处理,支持数据湖和数据库混合架构
边缘协同:更好的边缘计算支持,实现云边端一体化管理
实践建议
对于计划引入时序数据库的企业,建议采取以下实施路径:
-
从小规模试点开始,验证技术路线可行性
-
建立性能基准,为容量规划提供数据支持
-
培养内部专家,降低对外部支持的依赖
-
参与开源社区,获取最新的技术动态和支持
下载链接:Apache IoTDB下载页面
企业版官网链接:天谋科技Timecho官网

时序数据库选型是一个需要综合考虑技术、成本和生态的复杂决策过程。通过科学的评估方法和系统的实施路径,企业可以选择最适合自身需求的时序数据库解决方案,为数字化转型奠定坚实的数据基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


