计算机毕业设计hadoop+spark+hive游戏推荐系统 游戏可视化 大数据毕业设计(源码+文档+PPT+讲解) 本文介绍了基于Hadoop+Spark+Hive的游戏推荐系统设计方案。系统采用分布式架构处理TB级用户行为数据,通过Hive构建数据仓库,实现用户画像和游戏标签管理。核心技术包括两种推荐算法:基于用... 国内服务器 2个月前260
Spark企业级应用案例:电商用户行为分析实战 某电商平台日均产生5TB用户行为数据批处理慢:用Hive分析全量数据需4小时,无法支撑“上午出报表、下午做运营”的需求;实时性差:用Flink做流处理但批处理能力弱,无法统一批流逻辑,维护成本高;无法... 国内服务器 2个月前260
025、分布式计算实战:Spark Core与Spark SQL Spark用起来像开车——自动挡简单,但想开得快还得懂手动模式。别迷信DataFrame API就一定比RDD快,复杂的多阶段处理里,RDD的精细控制反而更有效。生产环境永远先跑小样本数据,看看执行计... 国内服务器 2个月前260
大数据浪潮下,解锁智算云平台实操密码 根据自己的需求定义模型训练流程是提升模型性能的重要一步。这其中,损失函数和优化器的选择与设置起着核心作用。损失函数,作为衡量模型预测值与真实值之间差异的指标,其选择直接影响模型的学习方向。在分类任务中... 国内服务器 2个月前260
RabbitMQ交换机与队列核心类型解析 交换机核心:Direct(精准)、Fanout(广播)、Topic(通配符)是主流,Headers 极少用;队列核心:仲裁队列(强一致、高可用)是核心业务首选,镜像队列逐步被替代,死信队列用于异常消息... 国内服务器 2个月前260
淘宝客APP数据湖架构:Iceberg + Flink实现的历史数据回溯与增量计算统一存储方案 面对每日亿级的流水记录、频繁的订单状态变更(如下单、付款、结算、失效)以及复杂的佣金追溯需求,传统的Hive数仓在ACID事务支持和实时性上显得捉襟见肘,而单纯的Kafka流处理又难以满足大规模历史数... 国内服务器 2个月前260
Kafka 基本架构深度解析:六大核心组件各司其职 组件一句话描述数量状态Producer消息的源头,负责发布数据多个无状态Consumer消息的归宿,负责拉取和处理多个无状态消费者组织单元,实现负载均衡多个有状态(Offset)Broker消息代理节... 国内服务器 2个月前260
云原生与边缘计算融合驱动下一代互联网架构创新探索实践【六十六】 云原生与边缘计算的结合,使互联网系统从“中心化”走向“分布式智能”。通过容器、微服务与轻量化集群技术,我们可以构建高性能、低延迟的现代应用架构。 国内服务器 2个月前260
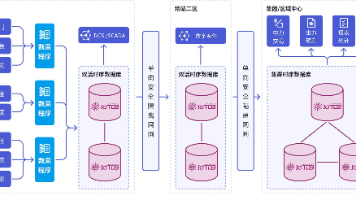
时序数据库选型指南:从大数据场景出发 在 2026 年再谈时序数据库选型,问题早已不只是“谁写得快、谁查得快”,而是能不能承接真实业务里的设备模型、边缘采集、海量写入、历史归档和生态接入。本文不做夸张宣传,也不走功能罗列,而是从大数据和工... 国内服务器 2个月前260
《Windows Internals》10.1.11 应用程序 Hive(Application hives):为什么 Windows 要允许应用拥有“只对自己可见”的私有注册表? Windows 7引入的应用程序Hive(Application hives)机制为应用提供了私有注册表空间,解决了传统注册表访问的公共性问题。通过RegSaveKeyEx和RegLoadAppKey... 国内服务器 2个月前260