RabbitMQ 核心角色:什么是生产者和消费者?全流程图解+实战详解 前言一、核心概念定义:什么是 RabbitMQ 生产者和消费者?1.1 生产者(Producer):定义与作用1.2 消费者(Consumer):定义与作用1.3 两者关系总结二、工作流程图解:生产者... 国内服务器 3天前40
Kafka ISR与AR深度解析:副本同步机制核心概念 一个分区分配的所有副本集合,包括Leader和所有Follower。fill:#333;important;important;fill:none;color:#333;color:#333;impo... 国内服务器 3天前50
Flink 窗口与 Event Time 调试看懂 Watermark,到底卡在哪个分区? 本文介绍了Flink中currentInputWatermark指标的核心作用,它反映了每个task接收的最低watermark,决定了全局事件时间的推进。通过Web UI或JMX监控该指标,可以快速... 国内服务器 3天前40
HAProxy安装与RabbitMQ负载均衡配置 本文介绍了在Ubuntu和CentOS系统中安装配置HAProxy实现RabbitMQ负载均衡的方法。主要内容包括:通过apt-get/yum安装HAProxy;配置HAProxy统计页面(监听810... 国内服务器 3天前50
大数据领域 Kafka 的消费组管理策略 Kafka 的消费组(Consumer Group)是实现“多消费者并行消费”的关键机制。消费组的底层运行逻辑3 种主流分区分配策略(Range/RoundRobin/Sticky)的原理与适用场景消... 国内服务器 3天前40
如何使用Kafka Connect轻松实现数据导出:完整指南 Apache Kafka是一个分布式流处理平台,而Kafka Connect作为其核心组件,提供了简单高效的数据导入导出解决方案。本文将详细介绍如何使用Kafka Connect工具实现数据导出,帮助... 国内服务器 3天前50
一文带你掌握Kafka常见面试题 架构:Producer、Consumer、Broker、Topic、Partition、Replica、Controller。性能:顺序写、Page Cache、零拷贝、批量、压缩、分区并行。可靠性... 国内服务器 3天前60
Go消息系统项目复盘:从RabbitMQ到自研轻量MQ的技术选型历程 从RabbitMQ到自研MQ的选型历程,核心不是技术对比,而是"什么方案最适合这个场景"的成本效益分析。日均30万条消息的场景,RabbitMQ的复杂性是冗余的自研约400行Go代... 国内服务器 3天前50
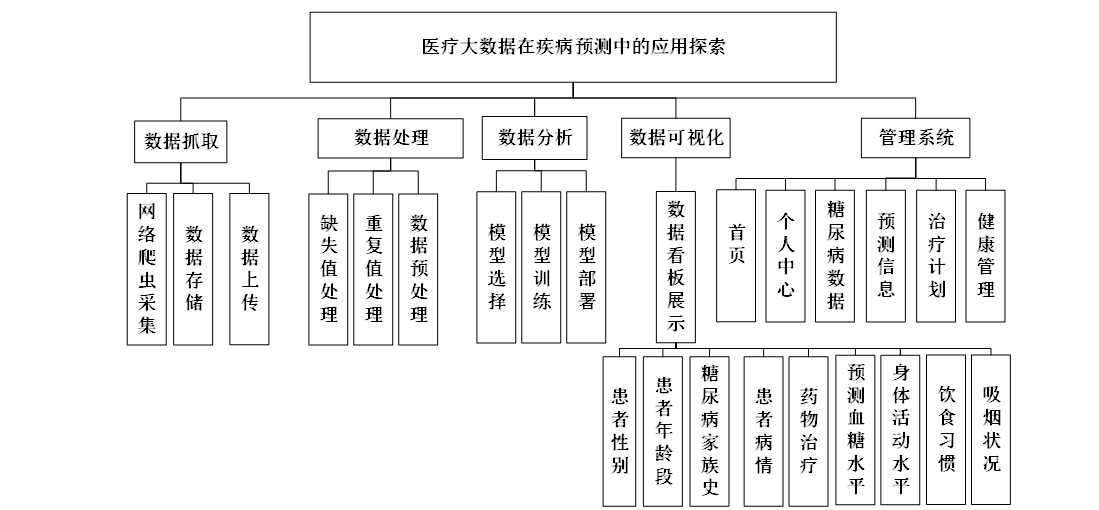
计算机毕业设计之医疗大数据在疾病预测中的应用探索 摘要:本研究构建了基于医疗大数据的糖尿病预测管理系统,采用随机森林回归算法建立预测模型,实现了从数据采集、处理到分析的全流程管理。系统包含网络爬虫数据抓取、数据清洗预处理、模型训练部署及可视化展示功能... 国内服务器 3天前60
【RabbitMQ】与ASP.NET Core集成 ASP.NET Core提供了IHostedService接口和BackgroundService基类,用于实现长时间运行的后台任务。OrderProcessor.Service:消费订单消息,处理业... 国内服务器 3天前50