探索C++17中的文件系统库:std::filesystem C++17中的std::filesystem库为文件系统操作提供了一套强大而易用的工具。通过使用std::filesystem,开发者可以更加轻松地处理文件路径、创建和删除文件与目录、遍历目录内容等任... 国内服务器 3个月前240
基于Doris的实时数据仓库建设:从理论到实践的完整指南 随着企业数字化转型加速,实时数据处理需求呈爆发式增长。传统数据仓库在面对高并发实时查询、海量数据实时写入时逐渐显现性能瓶颈,而Apache Doris作为一款高性能分析型数据库,凭借其极简架构与强大的... 国内服务器 3个月前240
Java 大视界 — Java 大数据在新能源微电网能量优化调度与虚拟电厂协同控制中的应用实践(282) 本文以 IEEE 标准为依托,结合国家电网雄安、德国 E.ON 等全球标杆项目,系统阐述 Java 在新能源微电网与虚拟电厂中的全生命周期技术应用,涵盖数据融合、智能算法、区块链协同及自主控制等前沿领... 国内服务器 3个月前240
计算机毕业设计hadoop+spark+hive旅游推荐系统 旅游可视化系统 地方旅游网站 旅游爬虫 旅游管理系统 大数据毕业设计 机器学习 深度学习 知识图谱 本文介绍了一个基于Hadoop+Spark+Hive技术的旅游推荐系统。系统采用分层架构设计,整合多源旅游数据,通过协同过滤与内容推荐的混合算法模型,实现高效精准的个性化推荐。重点阐述了数据采集、存储... 国内服务器 3个月前240
Kafka Streams聚合性能优化:3大瓶颈与4种提升策略 掌握Kafka Streams聚合操作性能优化关键,解决吞吐量低、延迟高、资源占用多三大瓶颈。涵盖窗口聚合、状态存储优化与并行处理等四大策略,适用于实时统计、指标监控等场景,显著提升处理效率,值得收藏... 国内服务器 3个月前240
Spring Boot中RabbitMQ的六种工作方式及应用场景与代码示例 RabbitMQ支持多种消息传递模式,每种模式适用于不同的业务需求。Simple(简单模式)Work Queue(工作队列模式)Publish/Subscribe(发布/订阅模式)Routing(路由... 国内服务器 3个月前240
Flink 2.2 从本地 Standalone 到 Docker/Kubernetes,把 Hive 批流打通,并在 SQL 里接入 OpenAI 推理 Flink集群部署模式与优化实践 Flink集群包含Client、JobManager和TaskManager等核心角色,支持Session和Application两种部署模式。Session模式适合... 国内服务器 1个月前230
RabbitMQ – 客户端底层通信:AMQP 协议核心帧结构 AMQP(Advanced Message Queuing Protocol)是一个开放标准的应用层协议,专为消息中间件设计。它的目标是提供一种标准化的方式来实现消息队列服务,使得不同厂商的消息中间件... 国内服务器 2个月前230
【AI时空分析】AI 预测 2026 五一假期:基于时空大数据的旅游迁徙趋势分析 本文深入探讨了如何利用 AI 技术和时空大数据分析,精准预测 2026 年五一假期的旅游迁徙趋势。通过融合历史出行数据、气象信息、经济指标和社交媒体热度等多维数据源,构建 LSTM + Transfo... 国内服务器 2个月前230
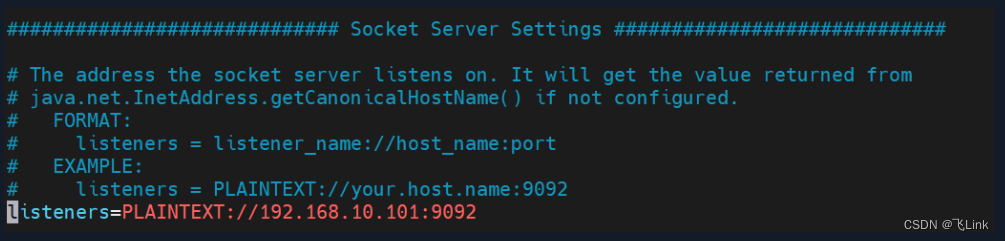
Kafka~本地Python Kafka发送数据,服务端Kafka消费不到 在本地通过python的Kafka模块和Pykafka模块创建Kakfa生产者往服务器的Kakfa发送数据,在服务端使用Kakfa消费者消费不到数据。(我的服务器ip为192.168.10.101... 国内服务器 2个月前230