基于Hadoop的汽车合法改装推荐系统 💛博主介绍:大家好,我是码趣猪仔,一名拥有4年码龄的全栈程序员,Java/Python/Node 三系驾照,SpringCloud + Vue3 + 小程序 + DevOps一条龙能自己跑通,也是一位... 国内服务器 2周前100
大数据新视界 — Impala 性能突破:复杂数据类型处理的优化路径(上)(25 / 30) 本文围绕 Impala 处理复杂数据类型,阐述其如星云黑洞般多样的挑战,介绍数据预处理、存储格式与索引等优化路径,通过电商、医疗、金融、社交舆情案例展示效果,及数据丢失损坏、资源过度消耗风险与应对,助... 国内服务器 2周前90
5分钟搞定RabbitMQ!Docker一键安装 + 核心概念图解 还在为安装RabbitMQ头疼?用Docker只需一行命令!本文提供超详细Docker安装教程,无需复杂配置,复制粘贴即可运行。安装成功后,通过可视化管理界面(http://localhost:156... 国内服务器 2周前110
HDFS 在大数据领域的重要性及应用场景 在大数据时代,数据量呈现爆炸式增长,传统的文件系统难以应对如此大规模的数据存储和管理需求。HDFS 作为 Hadoop 生态系统的核心组件之一,旨在提供一个高容错、高吞吐量的分布式文件系统,以满足大数... 国内服务器 2周前100
Kafka 安全认证全景解析:从 Kerberos 到 OAuth 的选型之路 文章通俗解析了Kerberos、mTLS、SCRAM与OAuth 2.0四大主流方案的核心原理与优劣势。结合大数据、金融及微服务等实战场景,提供选型对比与建议,助您精准选择最适合的“门神”,轻松构建企... 国内服务器 2周前120
RabbitMQ深度解析:从入门到原理再到实战应用 优势说明可靠性持久化、消息确认、高可用集群灵活性多种Exchange类型,支持复杂路由生态丰富丰富的客户端库和管理工具易用性简单的API,完善的文档企业支持活跃的社区和商业支持RabbitMQ作为企业... 国内服务器 2周前90
【信息科学与工程学】【数据科学】数据科学领域 第十二篇 大数据主要算法02 展示Apache Spark MLlib中主要算法、函数、参数及其涉及的跨学科理论。实际应用中每个算法还有更多细节和扩展。Spark MLlib的设计充分考虑了分布式计算的特性,同时借鉴了多个学科的理... 国内服务器 2周前100
工业大数据时序数据库选型方法论:核心指标与技术适配分析 结合工业时序数据的核心痛点与选型标准来看,通用型时序数据库大多侧重云端场景优化,对边缘部署、工业层级结构、乱序数据适配、长期存储成本控制等场景考虑不足。而 Apache IoTDB 从底层架构出发,针... 国内服务器 2周前90
Lightspark使用教程:从浏览器插件到独立应用 Lightspark是一款开源Flash播放器实现,让你能够在现代浏览器和独立应用中轻松播放Flash内容。本教程将带你快速掌握Lightspark的安装配置与使用技巧,解锁Flash内容的全新体验... 国内服务器 2周前90
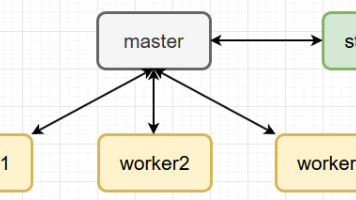
小肥柴的Hadoop之旅 快速实验篇(0-1)虚拟机模拟完全分布式环境搭建 一套在(本地)虚拟机中模拟完全分布式Hadoop环境搭建过程,适配3.0以上版本;对潜在踩坑都做了预判,能够快速上手这门非遗技术。 国内服务器 2周前90