Zookeeper 从入门到精通 本文系统介绍了ZooKeeper分布式协调服务的核心知识,包括基础概念、架构原理、安装部署、操作命令、Java客户端编程以及实际应用场景。详细讲解了ZooKeeper的节点类型、数据模型、ACL权限控... 国内服务器 3个月前220
Flink窗口机制详解:大数据时间处理的核心 在大数据实时处理场景中,数据通常以无界流的形式持续产生,如何对无限数据流进行有限化处理是核心挑战。Flink的窗口机制通过将数据流分割成有限的“窗口”,实现对指定时间范围或数据量的聚合计算。本文将系统... 国内服务器 3个月前220
【后端开发】RabbitMQ、RocketMQ、Kafka 怎么选?我从业务场景重新梳理了一遍 关于三种消息队列 RabbitMQ、RocketMQ和Kafka 如何选择,刚开始学消息队列的时候,我其实也很容易陷入一种误区:把 RabbitMQ、RocketMQ、Kafka 放在一张表里硬背。比... 国内服务器 1个月前210
大数据领域的制药数据研发与创新 制药行业正经历着前所未有的数字化转型。本文旨在系统性地阐述大数据技术如何重塑制药研发流程,提高药物发现效率,降低研发成本。药物靶点发现与验证化合物筛选与优化临床试验设计与分析药物安全监测与上市后研究本... 国内服务器 2个月前210
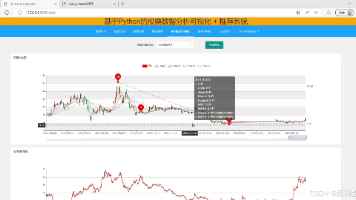
计算机毕业设计:Python股票投资辅助决策系统 django框架 request爬虫 协同过滤算法 数据分析 可视化 大数据 大模型(建议收藏)✅ 本文介绍了一个基于Python和Django框架开发的股票数据分析可视化系统。系统主要功能包括:用户注册登录与信息管理、股票新闻爬取展示、历史价格与成交量等数据可视化分析(支持K线图、折线图等多种图表... 国内服务器 2个月前210
RabbitMQ 高级篇保姆级架构思维总结(微服务) 本文系统总结了消息队列(MQ)的核心问题与解决方案。MQ主要用于解决系统间的解耦、削峰和异步问题,但会引入消息丢失、数据不一致、系统稳定性和业务体验四大挑战。通过确认机制+持久化+幂等+重试+延迟处理... 国内服务器 2个月前210
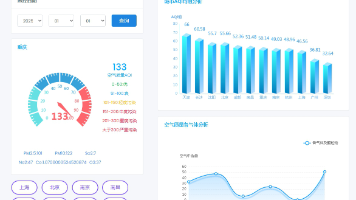
计算机毕业设计hadoop+spark+hive空气质量预测系统 空气质量大数据分析可视化 大数据毕业设计(源码+LW文档+PPT+讲解) 本文提出了一种基于Hadoop、Spark和Hive的空气质量预测系统,通过整合多源异构数据,利用分布式计算与LSTM模型实现高精度预测。实验表明,该系统在北京市PM2.5预测中,72小时预测平均绝对... 国内服务器 2个月前210
hadoop+Spark+springboot基于大数据的高校网络舆情监控引导系统(源码+文档+调试+可视化大屏) 摘要:本文介绍了一个基于SpringBoot和大数据技术的高校网络舆情监控引导系统。该系统采用Java语言开发,整合Hadoop、Spark等大数据处理技术,结合Vue.js前端框架,实现对校园网络舆... 国内服务器 2个月前210
PySpark vs传统方法:大数据处理效率提升10倍的秘密 尝试了传统Pandas方法和PySpark两种方案后,效率差距让我大吃一惊。我生成了包含1000万条记录的模拟电商订单数据,每条记录包含订单ID、用户ID、商品ID、购买数量、金额和时间戳等字段。为了... 国内服务器# kimi 2个月前210