Docker快速部署HBase:从零搭建到Java应用集成 本文详细介绍了如何使用Docker快速部署HBase并集成Java应用。通过Docker容器化技术,开发者可以轻松搭建HBase单机环境,避免复杂的依赖配置,并实现高效的Java应用集成。文章还提供了... 国内服务器 1个月前190
计算机毕业设计|基于大数据的社交媒体舆情数据可视化分析系统 基于Hadoop的社交媒体舆情数据可视化分析系统 基于Spark的社交媒体舆情数据可视化分析系统 大家打卡 文章 更新 140/ 365天精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻Java精彩实战项目案例Java精彩新手项目案例Python精彩新手项目案例NodeJS精彩项目。 国内服务器 1个月前190
【大数据技术基础 | 实验十】Hive实验:部署Hive 本实验介绍Hive的工作原理和体系架构,学会如何进行Hive的内嵌模式部署,启动Hive,然后将元数据存储在HDFS上。 国内服务器 1个月前190
计算机毕业设计Spark地铁客流量预测 交通大数据 交通可视化 大数据毕业设计 深度学习 机器学习 大数据毕业设计(源码+LW文档+PPT+讲解) 本文系统综述了基于Spark的地铁客流量预测系统技术架构与应用实践。研究采用"数据采集-存储-处理-预测-可视化"五层架构,整合多源异构数据,通过Spark MLl... 国内服务器 2个月前190
深入理解分布式锁:ZooKeeper vs Redis 维度一:生命周期持久节点(Persistent)— 客户端断开后,节点依然存在临时节点(Ephemeral) — 客户端断开后,节点自动删除 ← 锁用这个维度二:是否有序普通节点 — 名字就是你指定的... 国内服务器 2个月前190
3步搞定Hadoop在Kubernetes的存储配置:PVC与StorageClass实战秘籍 Apache Hadoop作为大数据处理的开源框架,在Kubernetes容器化部署中面临着存储配置的挑战。本文将为您提供完整的Hadoop Kubernetes存储配置指南,涵盖PVC(Persis... 国内服务器 2个月前190
Kafka 全面解析 Kafka是Apache开源的高性能分布式流处理平台,具备高吞吐、低延迟、高可用等核心特性。其架构基于生产者-消费者模型,通过分区机制实现并行处理,利用副本机制保证数据可靠性。关键优化包括:生产者批量... 国内服务器 2个月前190
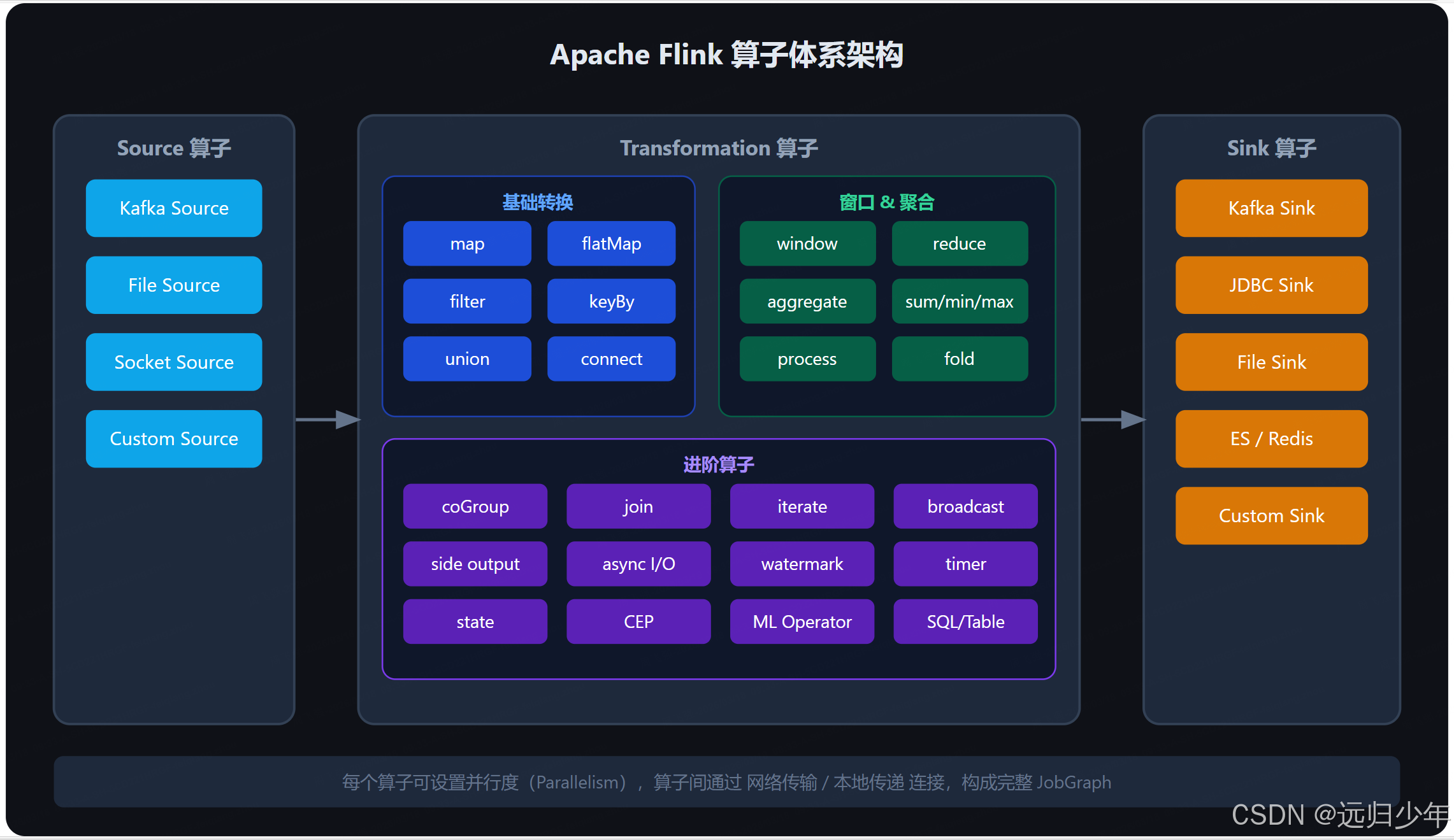
Apache Flink 算子(Operator)深度解析 Flink算子(Operator)是流处理程序的基本计算单元,负责数据转换、聚合等操作,构成有向无环图(DAG)。核心概念包括并行度(Parallelism)和算子链(Operator Chain... 国内服务器 2个月前190
NVIDIA DGX Spark 开发环境深度配置与优化指南 定期系统维护每月执行一次完整的系统更新监控存储空间使用情况,及时清理临时文件定期检查硬件健康状况开发习惯优化使用tmux或screen管理长时间运行的任务配置自动化测试和代码质量检查建立完善的项目文档... 国内服务器 2个月前190