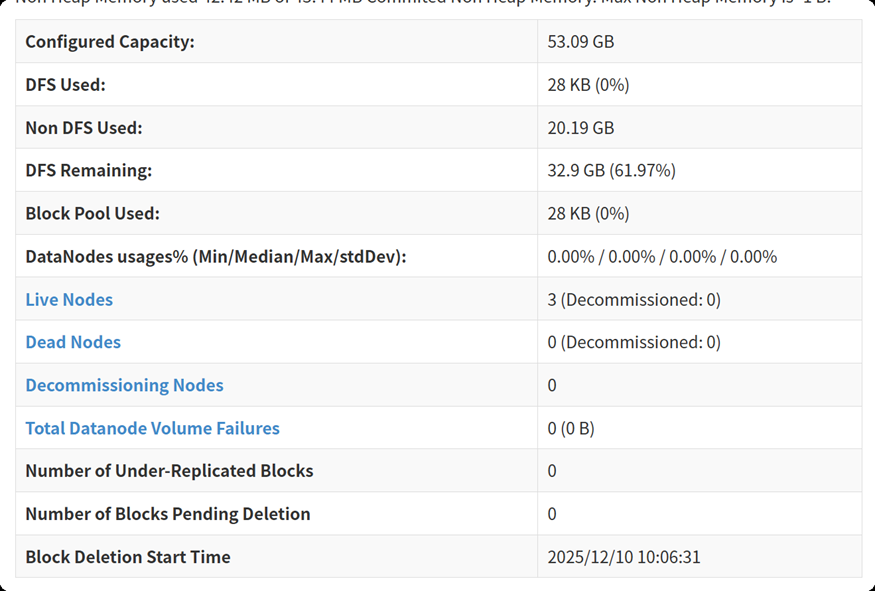
【赫兹威客】完全分布式HBase测试教程 本文详细介绍了在3台虚拟机(hadoop01~hadoop03)组成的完全分布式环境中进行HBase组件独立测试的全流程。测试内容包括环境准备、服务启停、Web页面验证和表操作命令验证等核心功能。文档... 国内服务器 2周前150
【Ranger】Ambari开启Kerberos 后 ,Ranger 中 Hive 策略里,Resource lookup fail 线程池超时优化 摘要:Ranger配置Hive资源时快速输入会触发"Resource lookup fail"错误,主要因Kerberos环境下Hive JDBC查询超时导致。问题... 国内服务器 2周前100
Storm 与 Kafka 集成完全指南:从原理到性能优化 在实时流处理领域,是一对黄金搭档。Kafka 作为高吞吐的分布式消息队列,负责数据的缓冲和持久化;Storm 作为实时计算引擎,负责数据的处理和分析。两者的结合,构成了无数实时数据管道的核心。本文将深... 国内服务器 2周前90
全面指南:如何监控Kafka Topic的生产者客户端 方法适用场景优点缺点命令行工具快速检查简单直接信息有限JMX 监控长期监控实时指标需额外工具日志分析故障排查详细日志需日志权限自动化运维可编程集成需开发成本网络抓包安全审计无侵入式可能影响性能生产环境... 国内服务器 2周前150
大数据新视界 — Hive 临时表与视图的应用场景(下)(30 / 30) 本文深度挖掘 Hive 临时表与视图在多领域应用场景,融合前沿技术与创新思路,剖析底层原理与复杂案例,借助多元互动与视觉辅助,为大数据从业者呈上全方位数据处理指南,激发数据价值最大化创新实践。 国内服务器 2周前150
CentOS 7环境下Hadoop高可用(HA)集群部署完全指南 1. fs.defaultFS=hdfs://ns(HDFS 入口)2. ha.zookeeper.quorum=master:2181,slave1:2181,slave2:2181(ZK 集群地址... 国内服务器 2周前210
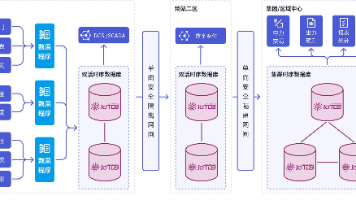
时序数据库选型指南:从大数据与工业场景出发,为什么 Apache IoTDB 值得重点关注 根据其官网介绍,企业版能力覆盖时序数据采集、写入、存储、查询、分析到应用的全生命周期,并强调高性能写入、TB 级查询与高压缩能力,同时已在能源、电力、制造、轨交等多个行业场景中落地。如果你正在寻找一款... 国内服务器 2周前130
RabbitMQ工作模式详解 RabbitMQ 的 6 种工作模式详解 本文系统介绍了 RabbitMQ 消息队列的 6 种核心工作模式: 简单模式(Hello World):单生产者-单队列-单消费者,最简单的点对点通信 工作队... 国内服务器 2周前130
Flink原理与实战(java版)#第11章Flink的应用(第三节Table & SQL 连接器之Hive(八)) 介绍Hive作为Table API和SQL的外部连接器使用,并且结合实际应用中会使用kafka作为数据源进行介绍。 国内服务器 2周前150
数据仓库基石:数据模型设计完全指南 数据模型是对现实世界数据特征的抽象描述,它定义了数据的结构、关系、约束和操作。在数据仓库领域,数据模型是连接业务需求和技术实现的桥梁。核心价值统一业务口径,消除歧义规范数据结构,提高复用性优化查询性能... 国内服务器 2周前120