Kafka 与 Elasticsearch 的集成应用案例深度解析 本文探讨了Kafka与Elasticsearch的集成应用案例,深入分析了这两种技术如何协同工作以优化数据处理和搜索能力。通过集成Kafka的实时数据流处理与Elasticsearch的强大搜索功能... 国内服务器 6个月前790
终极Kafka管理神器:Kafka-UI完全使用指南 还在为复杂的Kafka集群管理而头疼吗?Kafka-UI作为一款免费开源的Web界面工具,彻底改变了Apache Kafka的管理方式。这个轻量级但功能强大的工具让您能够直观地监控和管理Kafka集群... 国内服务器 6个月前790
第十三章 性能意识入门:你代码慢在哪?profiling 的工程化思路 本文介绍了数据分析与AI工程中的性能优化方法,重点讲解了如何通过profiling工具定位代码性能瓶颈。主要内容包括: 建立性能意识框架:通过度量-优化-验证的流程系统性地解决性能问题 三类瓶颈识别... 国内服务器 6个月前790
【期末考试总结】spark课程知识点 在安装Scala之前,需要下载、安装并配置好JDK环境所谓匿名函数,就是没有名字的函数,即定义函数时省略函数名称。函数名称使用“=>"来定义,等号左边为函数的参数列表,箭头右边为函数主... 国内服务器 6个月前790
2026高职大数据与会计专业就业方向与能力发展指南 大数据与会计专业的核心竞争力在于“跨界融合”。成功的关键不在于掌握最前沿的算法,而在于能否用数据分析工具解决实际的财务和业务问题。从现在开始,有意识地培养自己的复合技能,积累实战经验,你就能在2026... 国内服务器 4个月前780
传热学仿真-主题097-热疲劳寿命预测 热疲劳是工程结构在循环热载荷作用下产生的渐进性损伤现象,是导致航空发动机涡轮叶片、核反应堆压力容器、汽车排气系统等高温部件失效的主要机制之一。本文系统阐述热疲劳的物理机理、损伤累积理论和寿命预测方法... 国内服务器 5个月前780
【数据库】时序数据库选型指南:从大数据角度解析IoTDB的优势 时序数据库选型不是单纯的技术比较,而是需要综合考虑业务场景、团队能力、成本预算、生态依赖等多维度的系统工程。Apache IoTDB自2018年开源以来,已在国家电网、中冶赛迪、华为云、阿里巴巴等数千... 国内服务器 5个月前780
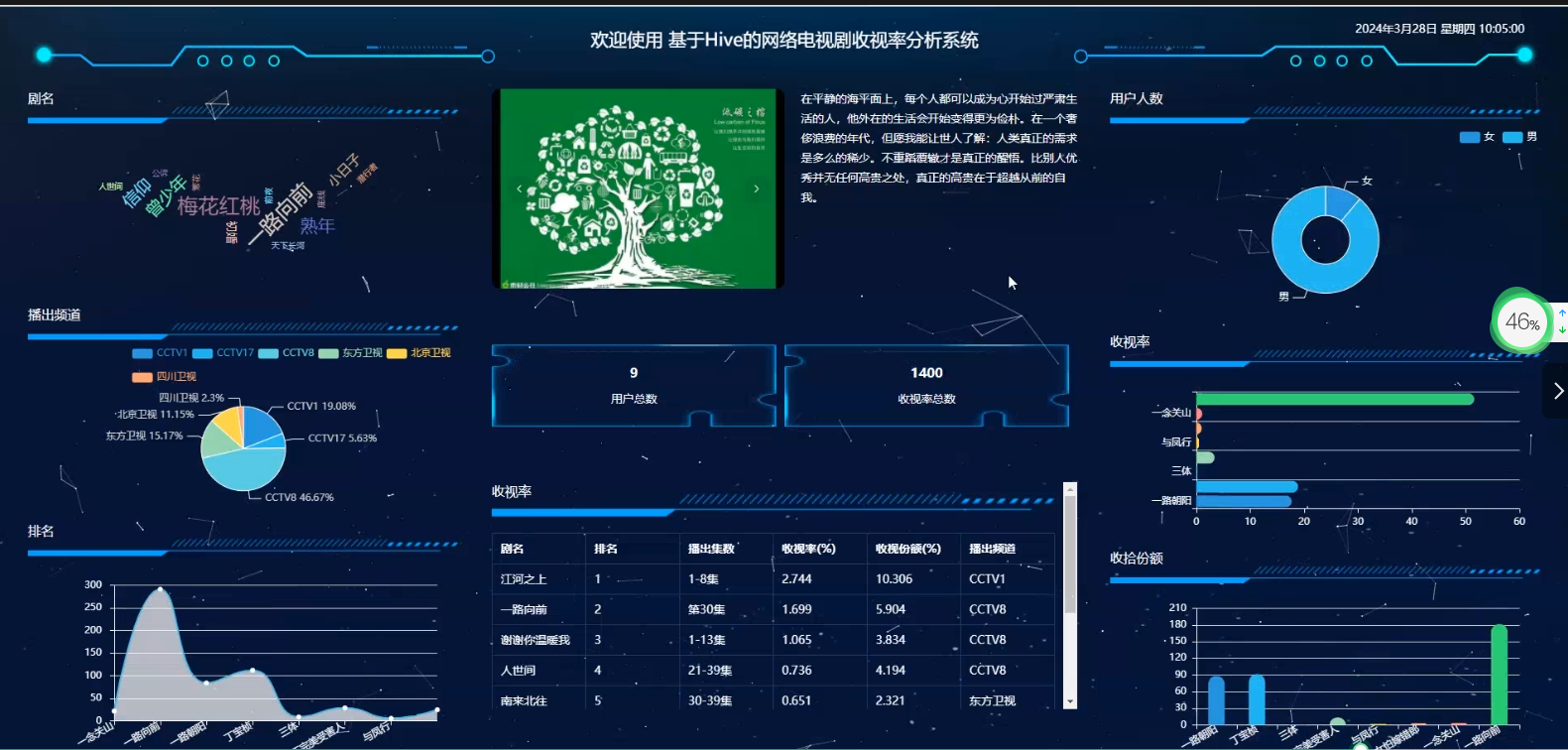
基于大数据爬虫+SpringBoot+Hive的网络电视剧收视率分析与可视化平台系统(源码+论文+PPT+部署文档教程等) 摘 要在当今数字化时代,网络电视剧作为一种新兴的娱乐形式,受到了广泛的关注和欢迎。随着网络电视剧市场的不断扩大和竞争的加剧,各大卫视平台纷纷推出了大量优质的网络电视剧,努力吸引观众和提升收视率。然而... 国内服务器 6个月前780