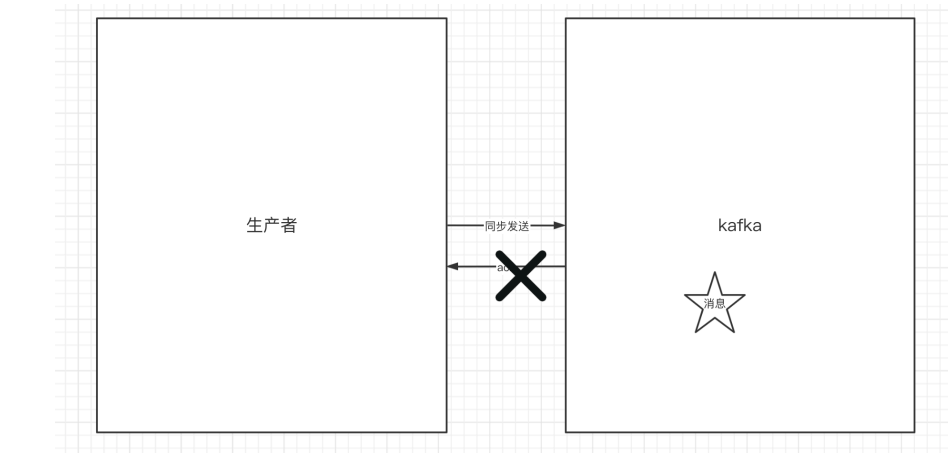
一篇文章速通kafka——day02 本文详细介绍了SpringBoot集成Kafka的实践过程,主要包括: Kafka生产者的实现方式(同步/异步发送、ACK配置、消息缓冲区) 消费者的核心实现(手动提交offset、长轮询机制、健康检... 国内服务器 3个月前190
大数据领域情感分析的挑战与应对策略 在当今数字化时代,大数据如同一个巨大的宝藏,蕴含着无数有价值的信息。情感分析作为大数据挖掘中的一项重要技术,旨在从大量的文本数据中提取人们的情感倾向,比如是积极的、消极的还是中立的。这项技术在很多领域... 国内服务器 3个月前190
用大模型构建“虚拟人”:驱动、口播与互动的全链路技术 2026 年的虚拟人技术已进入**“全链路实时化”**时代。虚拟人 = LLM(大脑) × Streaming(流式) × 多模态驱动(躯体)。技术选型建议口播/录播场景Wav2Lip+ 商用 TTS... 国内服务器 2周前180
Windows 保姆级 Docker 安装教程(WSL2 版),一篇入门docker 本文介绍了 Docker 的概念、核心组件、与虚拟机的区别及实用优势,并基于 WSL2 环境,详细讲解 Windows 系统下 Docker Desktop 的完整安装步骤。文中拆解镜像、容器、仓库三... 国内服务器 4周前180
Java 大视界 — Java 大数据在智慧文旅游客流量预测与景区运营优化中的应用(110) 本文系统解析 Java 大数据在智慧文旅中的创新应用,涵盖客流量预测、个性化推荐、景区管理等核心技术,结合 5A 级景区实战案例,提供 LSTM 预测、协同过滤推荐等可复用的代码方案。 国内服务器 4周前180
dolphinschedule+seatunnel+spark+hadoop 编辑,它决定了当seatunnel启动后数据输入、处理和输出的方式及逻辑。下面是配置文件的示例,它与上面提到的示例应用程序相同。 国内服务器 4周前180
Flink Batch Shuffle Blocking vs Hybrid 怎么选?Hash vs Sort 怎么调?一篇把坑点讲透的实战文 Flink的批处理shuffle机制(Blocking/Hybrid)与流处理的Pipelined Shuffle有本质区别,前者更关注资源效率、稳定性和总耗时的平衡。Blocking Shuffle... 国内服务器 4周前180
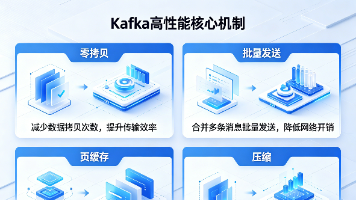
【Kafka核心】Kafka高性能的四大核心支柱:零拷贝、批量发送、页缓存、压缩 本文系统解析Kafka高性能四大支柱:页缓存(规避JVM GC,实现内存级读写)、零拷贝(sendfile/mmap减少CPU拷贝与上下文切换)、批量发送(全链路聚合降低IO次数)及端到端压缩(批次级... 国内服务器 4周前180
计算机毕业设计hadoop+spark+hive共享单车预测系统 共享单车数据可视化分析 大数据毕业设计(源码+LW文档+PPT+讲解) 本文介绍了一个基于Hadoop+Spark+Hive的共享单车需求预测系统项目任务书模板。项目旨在通过分布式技术处理海量时空数据,实现高精度的区域级需求预测。主要内容包括:系统架构设计(Hadoop存... 国内服务器 1个月前180
Django大数据爬虫新疆旅游景点推荐与可视化平台开题报告 Django大数据爬虫新疆旅游景点推荐与可视化平台开题报告一、课题研究背景与意义1.1 研究背景随着我国旅游业的蓬勃发展和数字经济的深度融合,旅游消费进入智能化、个性化时代,游客对旅游信息的获取效率... 国内服务器 1个月前180