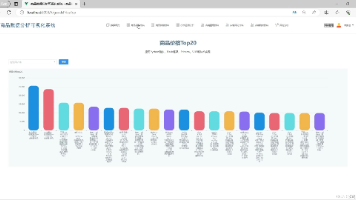
大数据领域数据可视化在电商科技领域的应用 随着电商科技的飞速发展,每天都会产生海量的数据,如用户的浏览记录、购买行为、商品销售数据等。这些数据蕴含着巨大的商业价值,但如果不能有效地进行分析和呈现,就无法为电商企业的决策提供有力支持。数据可视化... 国内服务器 2周前160
Hadoop之HDFS集群搭建与操作(二) 本文介绍了HDFS伪分布式集群搭建的关键步骤。首先详细说明了JDK8的安装过程,包括创建目录、上传安装包、配置环境变量等操作。其次讲解了Hadoop目录结构,重点介绍了bin、etc、lib等重要目录... 国内服务器 2周前160
ZooKeeper 集群角色详解:Leader、Follower、Observer 职责全解析 ZooKeeper 作为分布式协调服务,需要在高可用、高性能和一致性之间取得平衡。单一角色的设计无法满足这些需求,因此引入了三种角色:fill:#333;important;important;fil... 国内服务器 2周前130
Stable-Diffusion-v1-5-archive中文用户专项指南:翻译工具链+Prompt校验工作流 本文介绍了专为中文用户设计的Stable Diffusion v1.5创作工作流。通过利用星图GPU平台,用户可以自动化部署stable-diffusion-v1-5-archive镜像,并借助文中详... 国内服务器 2周前140
3分钟学会:开源工具ArchivePasswordTestTool帮你轻松找回压缩包密码 你是否曾经因为忘记压缩包密码而无法访问重要文件?ArchivePasswordTestTool作为一款基于7zip引擎的开源密码测试工具,正是解决这一难题的完美方案。这款工具通过自动化密码组合测试,能... 国内服务器 2周前110
Kafka 高可用架构:副本数不是越多越安全 Kafka 高可用不是简单增加副本数,而是合理配置 ack、ISR、生产者幂等、消费者并行和监控告警。可靠性、吞吐、延迟和成本必须一起评估。 国内服务器 2周前130
微服务的“通讯录“:深度解析 Consul、Etcd 与 Zookeeper 的服务发现机制 本文深入解析了微服务架构中的三大主流服务发现工具:Consul、Etcd 和 Zookeeper。文章首先阐述了服务发现的重要性,指出它是云原生环境下微服务通信的基础设施。随后介绍了客户端发现和服务端... 国内服务器 2周前190
Spark 与 ClickHouse 选型:离线计算和即时分析不要互相冒充 Spark、Hive、ClickHouse 不是简单替代关系。离线计算要算得准,即时分析要查得快,分层和口径说明让它们协同工作。选型的核心,是让引擎承担自己擅长的责任。 国内服务器 2周前160
计算机毕业设计源码:基于Flask与Vue的python数据分析可视化系统 可视化 hadoop (建议收藏)✅ 本文介绍了一个基于Python的京东商品数据分析可视化系统。系统采用Flask后端和Vue前端框架,结合Echarts实现数据可视化。通过requests爬虫获取京东商品数据,处理后存入MySQL数据... 国内服务器 2周前140
PrimeKG精准医疗知识图谱:解锁生物医学大数据的终极指南 在当今精准医疗研究领域,数据碎片化是制约科研进展的主要瓶颈。不同来源的基因数据、药物信息、疾病本体相互孤立,研究者需要耗费大量时间进行数据清洗和整合。PrimeKG知识图谱应运而生,它通过整合20个权... 国内服务器 2周前180