Java 大视界 —— Java 大数据在智能农业病虫害精准识别与绿色防控中的创新应用 Java大数据赋能智能农业病虫害精准识别与绿色防控 本文探讨了Java大数据技术在智能农业病虫害防治中的创新应用。传统农业依赖人工巡检和经验判断,存在误判率高(达45%)、预警滞后和农药滥用等问题。而... 国内服务器 5个月前430
AI赋能,智链未来:基于领码SPARK融合平台的银行制造业贷后风控“千里眼”系统技术方案 本方案为贵州银行与渤海银行提供基于领码SPARK平台的智能风控管理系统,实现制造企业贷款全流程穿透式管理。方案通过融合AI、大数据、IoT等技术,构建"数字孪生"风... 国内服务器 5个月前450
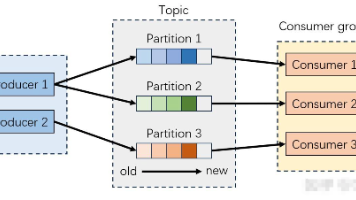
深度解析Kafka重平衡,触发机制、执行流程与副本的核心关联 Kafka中重平衡与副本机制深度解析 摘要:本文深入剖析Kafka中重平衡与副本两大核心机制的关联关系。重平衡作为消费端的负载均衡机制,与Broker端的副本调度操作虽维度不同,却通过Leader副本... 国内服务器 5个月前460
Java高性能Socket编程实战 理解 Socket 内核机制是基础,结合 Java NIO/Netty 的异步非阻塞模型,配合参数调优与监控,可实现百万级并发的高性能网络服务。 国内服务器 5个月前470
【大数据基础】大数据处理架构Hadoop:03 Hadoop的安装与使用 本文讲解在Ubuntu Kylin 16.04 LTS下Hadoop安装配置流程,涵盖安装系统与软件、创建用户、配置SSH、安装Java,以及单机和伪分布式安装与测试等关键步骤。 国内服务器 5个月前420
【Hadoop+Spark+python毕设】咖啡店销售数据分析系统、计算机毕业设计、包括数据爬取、数据分析、数据可视化、实战教学 【Hadoop+Spark+python毕设】咖啡店销售数据分析系统、计算机毕业设计、包括数据爬取、数据分析、数据可视化、实战教学 国内服务器 5个月前590
spark、mapreduce、flink核心区别及浅意理解 主流分布式数据处理框架对比:MapReduce、Spark和Flink分别代表批处理、内存计算和流批一体三个技术时代。MapReduce适合超大规模离线处理但延迟高;Spark在批处理和准实时场景表现... 国内服务器 5个月前650
新能源汽车大数据画像:从零到一实现K-means用户分群 本文阐述了大数据分析的相关原理及方法,并展示了在用户特征分析、用户画像挖掘、产品画像挖掘方向上涉及大数据技术的新能源汽车画像研究,同时基于 K-means 改进算法的画像研究应用。 国内服务器 5个月前500
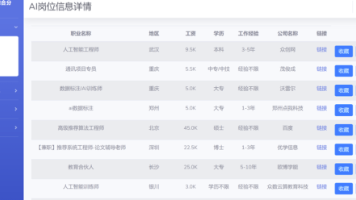
基于hadoop的招聘网站数据分析与可视化系统【开源代码】 本文设计并实现了一个基于Hadoop生态的招聘数据分析与可视化系统。系统通过爬虫获取多源招聘数据,利用HDFS存储,Hive构建数据仓库,Spark进行分布式处理分析,最终通过SpringBoot+V... 国内服务器 5个月前540
本地 Kafka 4.0+ 最新版 完整部署教程 + Kafka-UI 可视化 + 项目配置适配(全版本通用,避坑完整版) Kafka-UI 是目前最好用的 Kafka 可视化管理工具,功能全覆盖:创建 / 删除主题、查看生产 / 消费消息、管理消费者组、查看消费偏移量、监控 Kafka 状态等,完全替代繁琐的命令行操作... 国内服务器 5个月前620