Apache Kafka 是什么? Apache Kafka是一个开源的分布式事件流平台,具有高吞吐、持久化、可扩展等特点。其核心概念包括主题、分区、副本等,架构围绕生产、存储、消费三个环节设计,支持高吞吐、低延迟的消息处理。Kafka... 国内服务器 1个月前140
Kafka消息队列+zookeeper 摘要:Kafka作为分布式消息队列系统,具有高吞吐、低延迟、分布式持久化等特性,广泛应用于大数据与微服务场景。文章详细解析了消息队列的核心概念与优势(解耦、削峰、异步等),深入讲解了Kafka的架构原... 国内服务器 1个月前140
Open-AutoGLM竞争暗流涌动:5大数据揭示谁在悄悄领先? 洞察Open-AutoGLM行业竞争格局演变,5大关键数据揭示主流玩家技术路径与应用场景突破。聚焦自动化代码生成、模型效率优化等核心优势,解析领先者如何抢占AI开发先机。数据驱动决策,值得收藏。 国内服务器 1个月前140
新版本Docker Desktop 自定义安装路径和下载镜像地址路径修改(附must be owned by an elevated account问题解决) Docker自定义安装指南摘要 本文详细介绍了Windows系统下Docker Desktop的自定义安装方法。主要内容包括: 安装准备:需确保Docker Desktop已下载并开启虚拟化功能 自定... 国内服务器 1个月前140
RabbitMQ 重复消费问题:最通俗易懂的解决方案(幂等性)+ 实战总结 一、为什么会出现重复消费?二、核心解决思路:实现**幂等性**三、最常用、最稳定的 3 种解决方案(工作必用)方案1:唯一ID + Redis 分布式锁(生产 90% 场景用这个)方案2:数据库唯一索... 国内服务器 1个月前140
Google Cloud与AWS大数据AI服务对比(2026) 摘要: Google Cloud(GCP)和AWS在大数据与AI服务上的核心差异在于:GCP强于AI原生集成、数据密集型任务性价比,而AWS生态更完整,适合企业级灵活性与混合云场景。GCP的BigQu... 国内服务器 1个月前140
语音合成工具Spark-TTS实战指南:从零部署到高效调优的8大关键环节 作为一款基于LLM架构的开源语音合成系统,Spark-TTS在音色克隆和语音生成方面表现出色。本文通过8个关键环节的深度解析,帮助开发者快速掌握Spark-TTS的部署、配置和优化技巧,避开常见技术陷... 国内服务器 1个月前140
《国产系统运维笔记》第7期:打工人换统信UOS国产电脑后,第一件事:装RabbitMQ! 本文详细介绍了在统信UOS操作系统上安装配置RabbitMQ消息队列的完整流程。内容涵盖系统环境确认、APT源安装、管理插件启用、用户权限配置等关键步骤,并重点讲解了MQTT插件的安装与验证方法。通过... 国内服务器 1个月前140
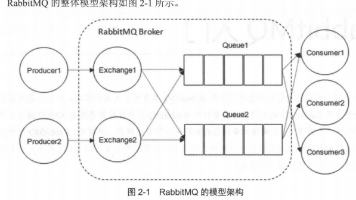
消息队列之Rabbitmq面试笔记总结 RabbitMQ是一个开源消息代理软件,其核心概念包括生产者(发送消息)、消费者(接收消息)、Broker(服务节点)、队列(存储消息)和交换器(路由消息)。交换器有四种类型:fanout(广播)、d... 国内服务器 1个月前140
Flink与Dgraph集成:分布式图数据库集成 随着社交网络、知识图谱、推荐系统等领域的快速发展,图数据的实时处理需求日益增长。传统关系型数据库在处理复杂图结构时性能受限,而分布式图数据库Dgraph凭借原生图存储和高效图查询能力成为首选。Apac... 国内服务器 1个月前140