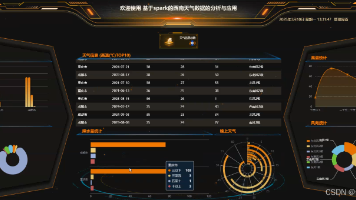
基于Spark+爬虫+Echarts的地区天气数据分析系统设计与实现 今天带来的是基于Spark+爬虫+Echarts的西南天气数据分析系统设计与实现,本研究基于Spark大数据技术,对西南地区气象数据进行多维度分析。通过Python爬虫采集多源气象数据,利用Spark... 国内服务器 3周前120
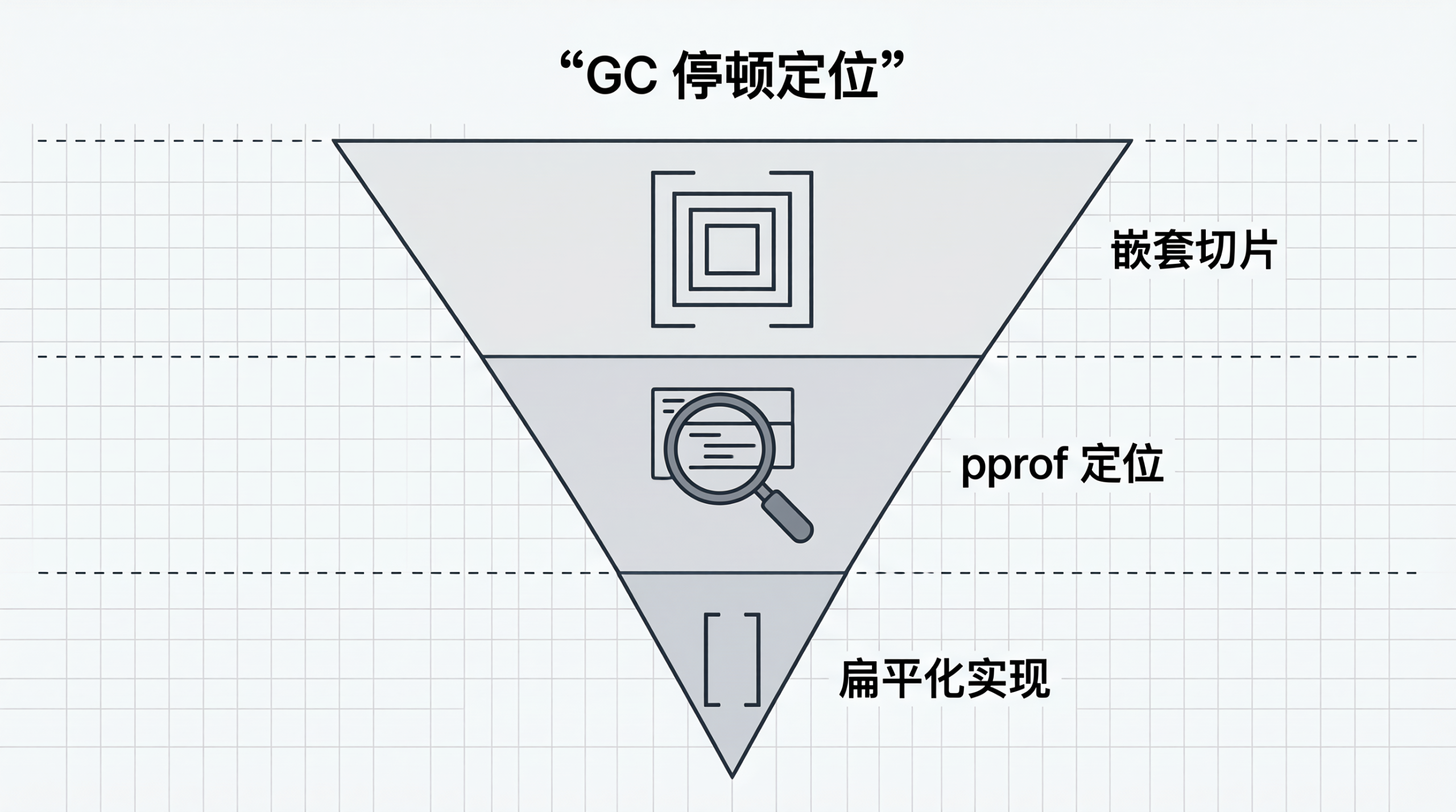
解决 Go 大数据切片 GC 暂停:使用 pprof 性能工具定位内存瓶颈 不久前团队遇到一个诡异的问题:一个数据处理服务每天凌晨 3:00 准时出现一次 CPU 尖刺和延迟抖动,持续大约 3-5 秒后自动恢复。监控显示 GC Pause 曲线有规律性的尖峰,每次持续 2-3... 国内服务器 3周前120
Hadoop与Python:PySpark大数据处理指南 你是否遇到过这样的问题:用Python的Pandas处理1GB数据很轻松,但处理100GB数据时,电脑直接"罢工"?这是因为普通Python工具只能处理单机内存中的数据,而大数据... 国内服务器 3周前120
查询加速:数据仓库 SQL 性能优化完全指南 问题表现业务影响技术原因报表加载慢用户体验差,等待焦虑全表扫描、数据倾斜定时任务超时数据延迟,影响下游资源竞争、不合理 Join资源消耗过高成本增加,影响其他任务数据膨胀、缺乏过滤并发能力差高峰时段系... 国内服务器 3周前120
Kafka Exporter实战指南:构建企业级监控体系 Kafka Exporter是专为Prometheus设计的Kafka监控解决方案,能够实时采集Kafka集群的核心性能指标,帮助运维团队快速定位问题、优化集群性能。本文将从实战角度出发,详细解析如何... 国内服务器 3周前120
Flink状态后端安全:RocksDB数据加密配置与性能调优 在实时计算场景中,Flink的状态数据是业务逻辑的核心——它可能存储着用户的交易记录、会话状态、累积统计值等敏感信息。然而,默认情况下,Flink的RocksDB状态后端会将数据以明文形式存储在本地磁... 国内服务器 3周前120
探索大数据领域数据预处理的前沿技术与发展趋势 在大数据的世界里,数据就像一座巨大的宝藏矿山,但这些数据往往是杂乱无章的。数据预处理的目的就是把这些杂乱的数据变成可以直接使用的“黄金”。我们这篇文章的范围就是研究数据预处理中那些最先进的技术,以及它... 国内服务器 3周前120
HDFS 在大数据领域的重要性及应用场景 在大数据时代,数据量呈现爆炸式增长,传统的文件系统难以应对如此大规模的数据存储和管理需求。HDFS 作为 Hadoop 生态系统的核心组件之一,旨在提供一个高容错、高吞吐量的分布式文件系统,以满足大数... 国内服务器 3周前120
【信息科学与工程学】【数据科学】数据科学领域 第十二篇 大数据主要算法02 展示Apache Spark MLlib中主要算法、函数、参数及其涉及的跨学科理论。实际应用中每个算法还有更多细节和扩展。Spark MLlib的设计充分考虑了分布式计算的特性,同时借鉴了多个学科的理... 国内服务器 3周前120
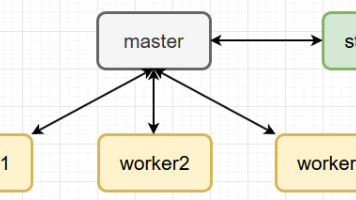
小肥柴的Hadoop之旅 快速实验篇(0-1)虚拟机模拟完全分布式环境搭建 一套在(本地)虚拟机中模拟完全分布式Hadoop环境搭建过程,适配3.0以上版本;对潜在踩坑都做了预判,能够快速上手这门非遗技术。 国内服务器 3周前120