大数据环境下数据仓库的混沌工程 随着企业数字化转型深入,数据仓库已从传统OLAP系统演变为支撑实时分析、机器学习的数据中枢。Gartner数据显示,78%的企业数据仓库故障源于分布式组件异常,但传统测试仅覆盖20%-30%的边缘场景... 国内服务器 1周前90
一文分清:数据治理、数据管理、数据管控、数据安全、数据仓库、数据湖、数据要素、数据资源、数据资产、数字资产、数字资产入表 数据要素(国家层面)引领 → 企业沉淀数据资源→ 经过数据治理/管控/管理的体系加工和护航,并依赖数据安全保护 → 资源在数据仓库/数据湖中被存储与计算 → 转化为数据资产(属于更广的数字资产范畴... 国内服务器 1周前90
Kafka消息可靠性:从生产到消费的全链路不丢不重 本文通过一个外卖订单的类比,系统性地分析了Kafka消息系统中消息丢失和重复消费的问题根源。文章指出消息可靠性需要贯穿生产者、Broker和消费者三个环节,并提出了"At-Least-Onc... 国内服务器 2周前90
RabbitMQ 篇-深入了解延迟消息、MQ 可靠性(生产者可靠性、MQ 可靠性、消费者可靠性) 如果消息的延迟时间设置较长,可能会导致堆积的延迟消息非常多,会带来较大的 CPU 开销,同时延迟消息的时间会存在误差。不过 SpringAMQP 提供的重试机制时阻塞式的重试,也就是说多次重试等待的过... 国内服务器 2周前90
Flink从入门到精通:全面实战指南 Apache Flink是一个开源的分布式流批一体处理框架,核心特点包括高吞吐低延迟、精确一次语义、强大的状态管理和事件时间处理能力。本文全面介绍了Flink的核心架构与组件,包括分层设计(部署层、R... 国内服务器 2周前90
计算机毕业设计:Python基于Spark与协同过滤的小说数据分析推荐系统 Spark Hadoop Hive Django 可视化 图书 大数据(建议收藏)✅ 技术栈Python 语言、Spark 分布式计算框架、Hadoop 分布式存储、Hive 数据仓库、Django Web 框架、Echarts 可视化库、基于用户的协同过滤推荐算法、scikit-le... 国内服务器 2周前90
深入剖析Spark UI界面:参数与界面详解|得物技术 围绕 Spark UI 监控模块,解析 Executors、SQL、Stages 等核心入口与关键指标,结合表扫描慢、Shuffle 并行度不足等典型场景,给出基于内存、并行度及 AQE 参数的调优方... 国内服务器 2周前90
RabbitMQ与Kafka的区别? 从实现思路上看,RabbitMQ 更像把消息投递给消费者处理,Kafka 更像把消息顺序写入分区日志,消费者通过 offset 自己控制消费进度。也能保证可靠性,但它更偏“分区日志”的思路,路由灵活性... 国内服务器 2周前90
从归档项目openclawbrain-archive解析数据采集与智能处理系统架构 数据采集与智能处理系统是现代信息技术中处理海量信息的基础设施,其核心原理是通过自动化程序从互联网或特定数据源获取原始数据,并经过清洗、解析、结构化等智能处理流程,转化为有价值的结构化信息。这类系统的技... 国内服务器 2周前90
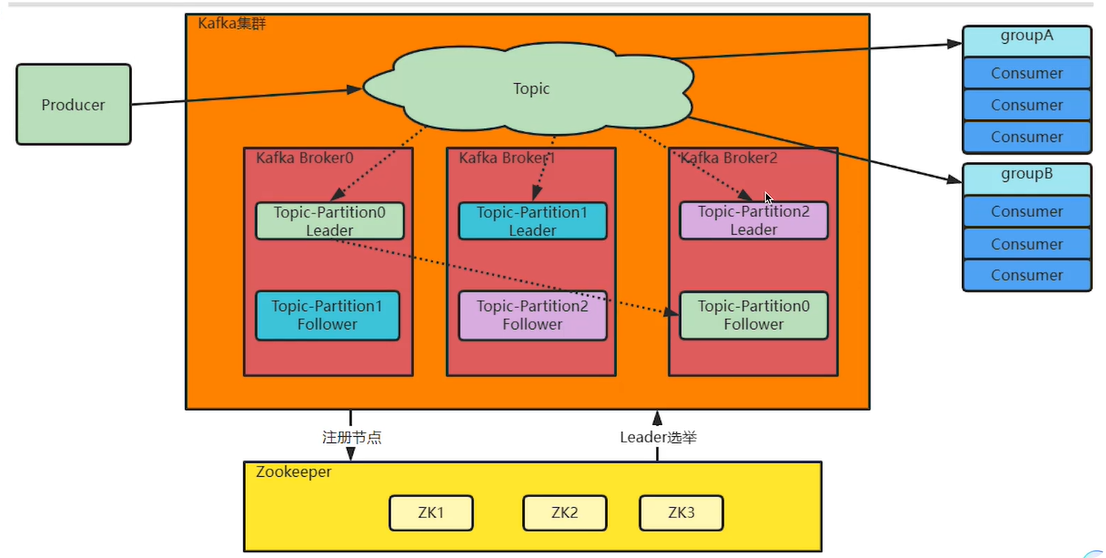
消息队列之Kafka(一)搭建服务 最后:Kafka集群中的这些Broker信息,包括Partiton的选举信息,都会保存在额外部署的Zookeper集群当中,这样,kaka集群就不会因为某一些Broker服务崩溃而中断。Kaka是面向... 国内服务器 2周前90