Flink原理与实战(java版)#第11章Flink的应用(第三节Table & SQL 连接器之Hive(三)) 介绍Hive作为Table API和SQL的外部连接器使用,并且结合实际应用中会使用kafka作为数据源进行介绍。 国内服务器 5个月前460
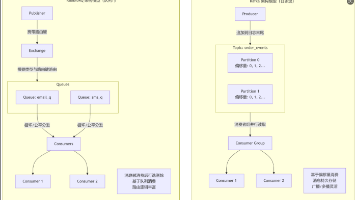
【终极对决】Kafka vs RabbitMQ:深入剖析消息中间件双雄,附选型指南与代码实战 Kafka vs RabbitMQ:消息中间件选型指南 本文深入对比了两大主流消息中间件: 架构差异: RabbitMQ采用交换器-队列模型,擅长消息路由与可靠投递 Kafka基于分布式日志设计,专注... 国内服务器 5个月前650
基于大数据的社交网络内容审核系统设计 在当今数字化时代,社交网络已经成为人们日常生活中不可或缺的一部分。每天,数以亿计的用户在社交平台上分享各种内容,包括文字、图片、视频等。然而,这些海量的用户生成内容(UGC)中,不可避免地会包含一些违... 国内服务器 5个月前550
大数据计算机毕设之基于flask框架的微博大数据分析与可视化系统与实现微博舆情分析可视化系统(完整前后端代码+说明文档+LW,调试定制等) 大数据计算机毕设之基于flask框架的微博大数据分析与可视化系统与实现微博舆情分析可视化系统(完整前后端代码+说明文档+LW,调试定制等) 国内服务器 5个月前630
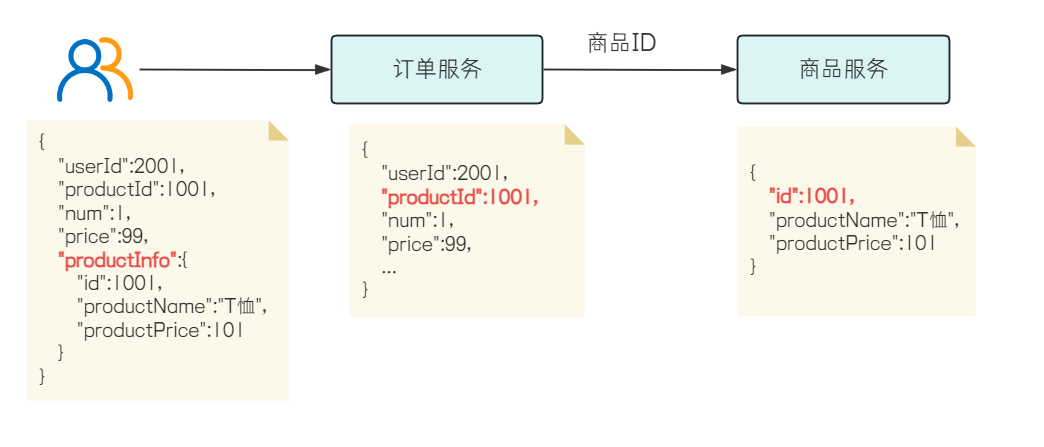
Eureka 服务注册和服务发现的使用 这三种特性是不能同时兼顾的,比如,在主数据库和从数据库同步数据的过程中网络出现了问题,那么这个过程就会被拉长,如果保证可用性,那么用户此时获取到的信息就不是强一致性的数据,在微服务架构中, P 是必须... 国内服务器 5个月前600
ArchivePasswordTestTool完整指南:快速找回压缩包密码的终极解决方案 在数字资产管理日益重要的今天,加密压缩包已成为保护敏感数据的常用手段。然而,密码遗忘问题却时常困扰着用户,导致重要文件无法访问。ArchivePasswordTestTool作为基于7zip引擎的自动... 国内服务器 5个月前510
【智能大数据分析 | 实验二】Spark实验:部署Spark集群 智能大数据分析实验二,Spark实验:部署Spark集群。理解Spark体系架构,学会部署Spark集群,能够配置Spark集群使用HDFS。最后在master上提交并运行Spark示例代码WordC... 国内服务器 5个月前620
Java 大视界 — Java+Flink CDC 构建实时数据同步系统:从 MySQL 到 Hive 全增量同步(443) 本文介绍基于Java+Flink CDC构建实时数据同步系统,实现MySQL到Hive的全增量数据同步。文章首先分析传统数据同步方案的痛点,对比Flink CDC在实时性、可靠性和运维成本等方面的优势... 国内服务器 5个月前690
Spark 核心角色深度剖析:Driver, Executor, Master, Worker 全解析 Spark 的世界就像一场大型协作演出:Driver 负责指挥全局,Cluster Manager 分配资源,Worker 和 Executor 则在后台默默干活。每个 RDD 分区都化身为并行 Ta... 国内服务器 5个月前620
RabbitMQ 在消息队列(MQ)中,确保消息成功传递是关键问题。消息传递过程包括生产者、交换机、队列和消费者四个阶段。为提高可靠性,生产者需配置重试机制,MQ需启用确认机制(Publisher Confirm和Pu... 国内服务器 5个月前560