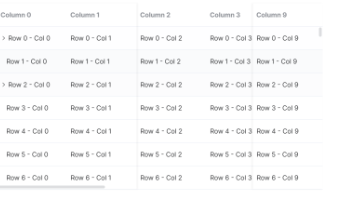
vue3+element-plus实现虚拟列表来解决大数据的问题 当我们列表数据特别多的时候,往往会带来卡顿与性能问题,按我们之前的逻辑,都是通过虚拟列表的方式来实现,现在在使用element后,他的vue3版本最新新增的功能本身就有虚拟列表,给我们带来了极大的便利... 国内服务器 5个月前750
解析ESP-SparkBot开源大模型AI桌面机器人的ESP32-S3核心方案 ESP-SparkBot是一款基于ESP32-S3微控制器的开源AI桌面机器人,采用边缘-云端协同架构实现多模态交互。核心硬件包括双核处理器、Wi-Fi/蓝牙模块及丰富外设接口,支持语音识别、图像处理... 国内服务器 5个月前750
Flutter for OpenHarmony 实战:Hive CE — 极速 NoSQL 本地存储 本文介绍了在Flutter for OpenHarmony应用开发中使用Hive CE实现数据持久化的方案。Hive CE作为纯Dart编写的键值存储库,具有高性能和良好兼容性优势。文章详细讲解了环境... 国内服务器 5个月前750
【Kafka】与【Hadoop】的集成应用案例深度解析 本文深入探讨了Kafka与Hadoop两大大数据处理技术的集成应用案例。首先,文章概述了Kafka作为分布式流处理平台的优势,包括其高吞吐量、低延迟以及强大的容错能力,这些特性使其成为处理实时数据流的... 国内服务器 5个月前750
实战|W餐饮平台智能化菜品推荐方案(含Spark实操+算法选型+完整流程) 文章摘要 W餐饮外卖平台面临老用户下单率下滑问题,主要由于热门菜品推荐同质化导致用户兴趣减退。本文提出基于Spark的智能化菜品推荐方案,通过分析用户历史评分数据,采用协同过滤算法实现个性化推荐。方案... 国内服务器 6个月前750
大数据领域的创新应用案例 当你每天刷手机产生的100条行为数据、超市收银机每秒打印的20张小票、医院CT机生成的3GB影像文件……这些看似无用的"数字碎片",正在通过大数据技术变成改变世界的"数字... 国内服务器 6个月前750
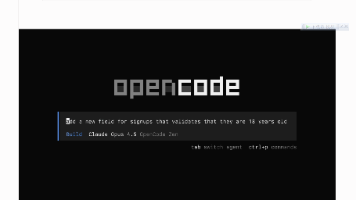
【笔记】Windows 上安装 OpenCode AI 编码助理:从踩坑到成功的简单记录 Windows用户安装OpenCodeAI编码助理的踩坑经验分享。作者尝试了5种安装方式,包括官方curl脚本、npm安装、桌面安装器等均失败,最终通过Chocolatey在管理员模式下成功安装。使用... 国内服务器 6个月前750
大数据领域Doris与MongoDB的集成方案 fill:#333;important;important;fill:none;color:#333;color:#333;important;fill:none;fill:#333;height:1... 国内服务器 6个月前750
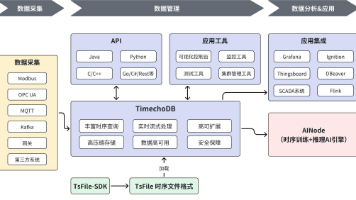
时序数据库选型权威指南:从大数据视角解读IoTDB的核心优势 时序数据库选型与IoTDB优势解析 随着物联网设备激增,传统数据库难以应对时序数据的特殊需求。本文从五大维度分析时序数据库选型要点,重点解读Apache IoTDB的核心优势: 选型关键:数据模型灵活... 国内服务器 6个月前750
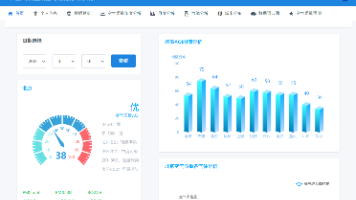
基于spark的空气质量数据分析可视化系统 本教程使用所有软件版本:ubuntu20.04,pycharm 25.2 ,spark 3.4.2 ,hadoop 3.4.1, MySQL8.0.35,Navicat for MySQL15ubun... 国内服务器 6个月前750