大数据计算机毕设之基于python的深度学习音乐推荐系统基于Python+Django的深度学习个性化音乐推荐系统(完整前后端代码+说明文档+LW,调试定制等) 主要内容:免费开题报告、任务书、全bao定制+中期检查PPT、代码编写、🚢文编写和辅导、🚢文降重、长期答辩答疑辅导、一对一专业代码讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。 国内服务器 3周前120
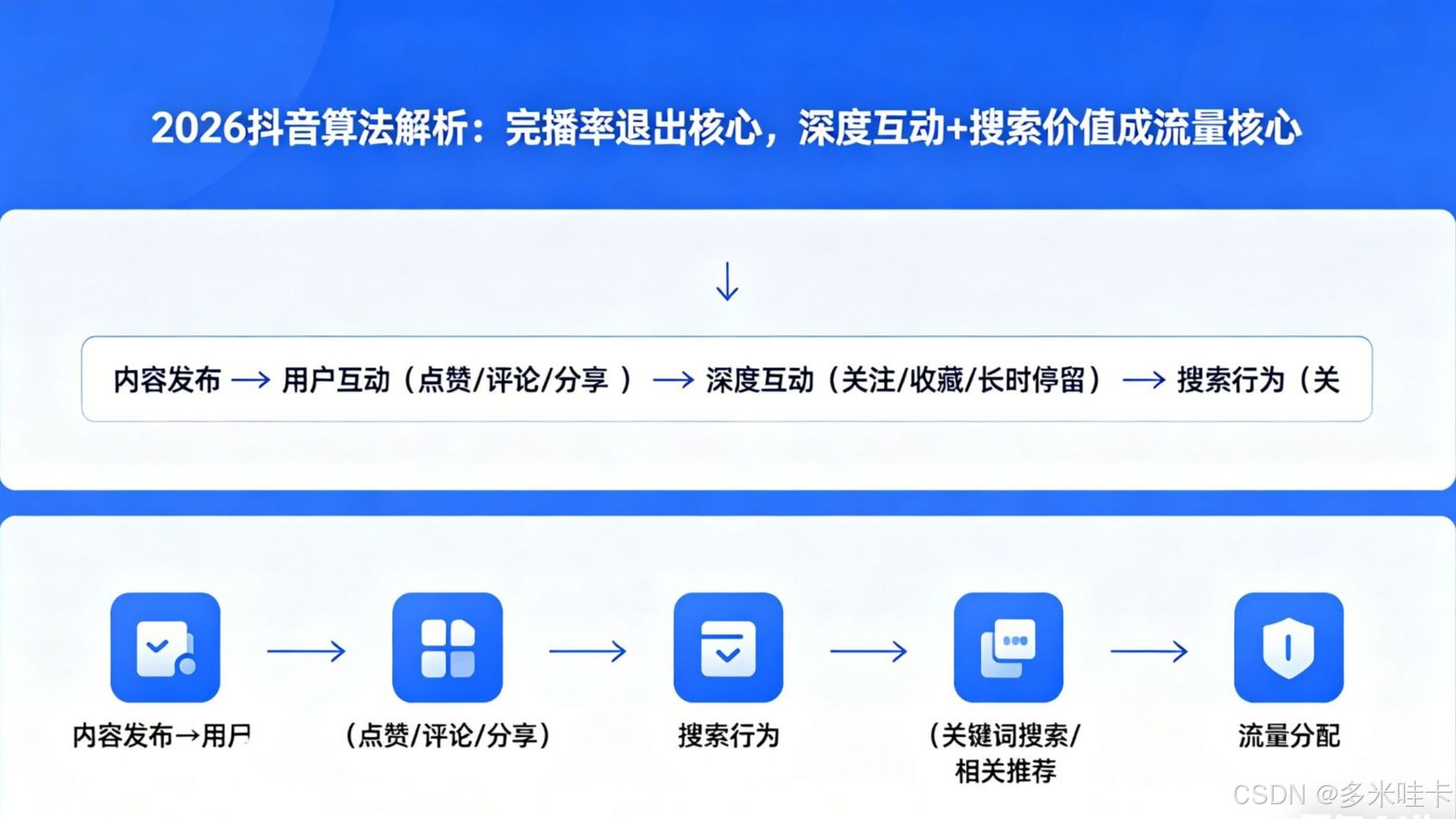
2026抖音算法解析:完播率退出核心,深度互动+搜索价值成流量核心 还在执着于完播率?2026年抖音算法已转向“深度互动+搜索价值”,多数运营尚未吃透新规要点。这篇实操干货,详细拆解适配新逻辑的方法,助力运营者合理获取流量。 国内服务器 3周前300
dolphinschedule+seatunnel+spark+hadoop 编辑,它决定了当seatunnel启动后数据输入、处理和输出的方式及逻辑。下面是配置文件的示例,它与上面提到的示例应用程序相同。 国内服务器 3周前150
Flink Batch Shuffle Blocking vs Hybrid 怎么选?Hash vs Sort 怎么调?一篇把坑点讲透的实战文 Flink的批处理shuffle机制(Blocking/Hybrid)与流处理的Pipelined Shuffle有本质区别,前者更关注资源效率、稳定性和总耗时的平衡。Blocking Shuffle... 国内服务器 3周前160
电商系统中RabbitMQ的5个典型应用场景 当用户下单时,订单服务只需将订单信息发送到RabbitMQ的Direct交换机,由专门的消费者服务异步处理后续流程(如生成订单号、计算优惠等)。这种模式避免了用户长时间等待,即使订单处理服务暂时不可用... 国内服务器 3周前150
大数据时代 RabbitMQ 对数据安全的防护 在电商大促、金融交易、医疗数据互通等场景中,每天有数以亿计的消息通过消息队列传输。如果消息在传输中被“截胡”,或被无权用户偷看、篡改,后果可能是用户隐私泄露、交易数据错乱甚至企业法律纠纷。本文聚焦Ra... 国内服务器 3周前110
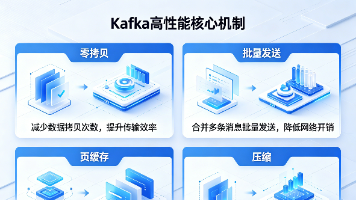
【Kafka核心】Kafka高性能的四大核心支柱:零拷贝、批量发送、页缓存、压缩 本文系统解析Kafka高性能四大支柱:页缓存(规避JVM GC,实现内存级读写)、零拷贝(sendfile/mmap减少CPU拷贝与上下文切换)、批量发送(全链路聚合降低IO次数)及端到端压缩(批次级... 国内服务器 3周前160
类型体操实战:Union 转 Intersection 在 TypeScript 中的探索 在 TypeScript 的类型系统里,Union(联合类型)和 Intersection(交叉类型)是两种极为重要且常用的类型构造方式。联合类型允许一个变量是多种类型中的一种,而交叉类型则是将多个类... 国内服务器 3周前110
计算机毕业设计Hadoop+Spark+Hive小红书评论情感分析 小红书笔记可视化 小红书舆情分析预测系统 大数据毕业设计(源码+LW+PPT+讲解) 本文介绍了一个基于Hadoop+Spark+Hive技术栈的小红书评论情感分析系统开发任务书。项目通过爬取小红书评论数据,利用大数据处理技术进行数据清洗、存储和分析,结合NLP技术实现情感分类(积极... 国内服务器 3周前130
TypeScript 递归条件类型实现深拷贝 在 TypeScript 开发中,深拷贝是一个常见且重要的操作。它能够将一个对象或数组及其所有嵌套的子对象或子数组都进行完整复制,生成一个全新的独立副本,避免因引用共享而导致的数据意外修改问题。下面将... 国内服务器 3周前130