【Java 进阶3】Kafka从入门到实战:全面解析分布式消息队列的核心与应用 本文全面介绍Apache Kafka分布式消息系统的核心架构与应用实践。首先从基础认知入手,阐述Kafka作为高吞吐、持久化发布-订阅系统的定位,对比分析其与RabbitMQ等产品的特性差异。重点解析... 国内服务器 6个月前740
NVIDIA DGX Spark实战指南:从开箱到部署200B参数大模型 本文详细介绍了NVIDIA DGX Spark桌面AI超级计算机的开箱体验与实战部署指南。文章深入解析了其Grace Blackwell架构与128GB统一内存的核心优势,并逐步演示了从系统初始化、运... 国内服务器 5个月前730
深入解析 systemd 服务启动失败问题:以 Kafka 服务为例 如何分析systemd服务失败日志。排查 Kafka 服务崩溃的常见原因(如配置错误、资源不足)。优化systemd单元文件和启动脚本。预防类似问题的措施(如日志管理、资源限制)。systemd服务管... 国内服务器 6个月前730
大数据Apache Doris从入门到入土(一) Apache Doris是一款基于MPP架构的高性能、实时分析型数据库。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris既能支持高并发的点查询场景,也能支持高吞吐... 国内服务器 6个月前730
【EI稳定】检索第六届大数据经济与信息化管理国际学术会议(BDEIM 2025) 第六届大数据经济与信息化管理国际学术会议(BDEIM2025)将于2025年12月19-21日在中国成都召开,由西南财经大学主办,西南财经大学计算机与人工智能学院、广州理工学院承办,上海海事大学支持... 国内服务器 6个月前730
Hadoop 与 Spark:大数据框架的对比与融合 Hadoop 和 Spark 是大数据处理领域的两大主流框架,各自具有独特的优势和适用场景。Hadoop 以分布式文件系统(HDFS)和 MapReduce 计算模型为核心,适合处理大规模批处理任务... 国内服务器 6个月前730
【MQ】Kafka与RocketMQ深度对比 本文深入对比了Kafka与RocketMQ两大消息队列的核心差异。RocketMQ采用"架构做减法、功能做加法"的设计理念:简化架构(如用NameServer替代Z... 国内服务器 6个月前730
PostgreSQL 数据仓库实战:实时数仓构建 + 离线分析 + 数据湖集成 摘要:PostgreSQL凭借混合负载能力,为中小企业提供轻量级实时数仓解决方案。相比传统Hive+Spark架构,PG数仓具有四大优势:1)架构轻量,部署成本降低80%;2)支持秒级实时同步;3)灵... 国内服务器 6个月前730
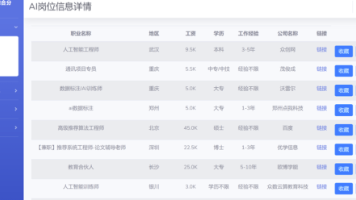
基于hadoop的招聘网站数据分析与可视化系统【开源代码】 本文设计并实现了一个基于Hadoop生态的招聘数据分析与可视化系统。系统通过爬虫获取多源招聘数据,利用HDFS存储,Hive构建数据仓库,Spark进行分布式处理分析,最终通过SpringBoot+V... 国内服务器 6个月前730