别让大数据“全表扫描”掏空你:数据分区策略与分区裁剪的实战心经 摘要: 数据分区与裁剪是大数据性能优化的核心策略。合理分区(按时间、业务维度等)能减少扫描范围,避免全表扫描。关键点包括:选择高过滤性字段、避免分区字段加工(如函数处理)、控制小文件问题。正确分区裁剪... 国内服务器 3周前110
Java 大视界 — Java 大数据机器学习模型在社交媒体舆情传播预测与舆论引导策略制定中的应用(289) 本文结合省级政务与头部企业案例,系统解析 Java 在舆情管理中的全流程应用,涵盖 LSTM-Attention 预测、BERT-XGBoost 特征融合、强化学习策略生成等核心技术,提供可落地的工业... 国内服务器 3周前160
缓存预热有哪些遵守原则?有哪些常见方案? 本文探讨了缓存预热的本质与实施方案。预热的核心是在业务流量到来前将热点数据加载到缓存,避免冷启动问题。文章提出六大预热原则,包括按优先级预热、选择合适时机、资源控制等。介绍了四种预热方式:项目启动时自... 国内服务器 3周前130
从“存下来”到“算得快”:工业大数据下半场的胜负手 工业数字化转型正从"连接万物"迈向"即时决策"阶段,DolphinDB时序数据库通过存算一体架构解决了工业4.0的新瓶颈。传统方... 国内服务器 3周前120
深入解析MCU安全启动中的HSM与CMAC校验机制 本文深入解析了MCU安全启动的核心机制,重点阐述了硬件安全模块(HSM)如何作为可信根,与基于AES的CMAC校验技术协同工作,构建从BootROM到应用程序的完整信任链。文章结合汽车电子实战经验,探... 国内服务器 3周前140
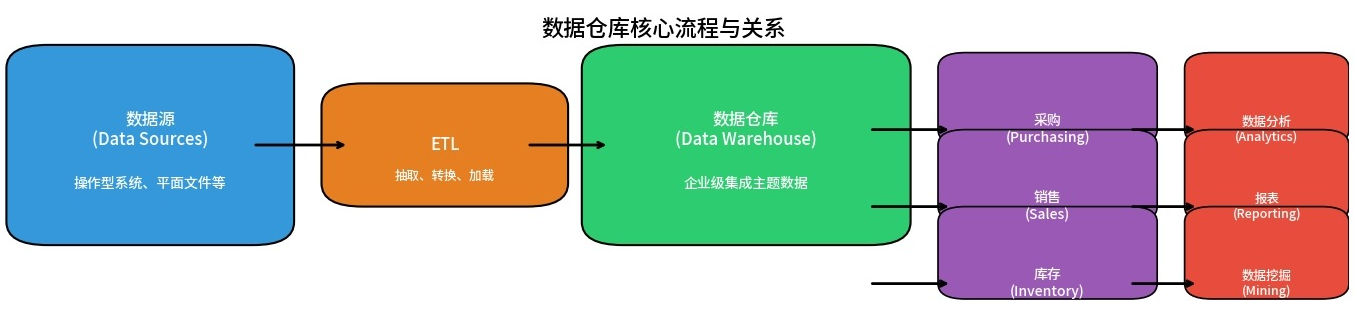
数据仓库理论基础 从数据仓库中按部门/主题(如采购Purchasing、销售Sales、库存Inventory)抽取数据,形成部门级分析库。:基于数据集市或数据仓库开展数据分析(Analytics)、报表(Report... 国内服务器 3周前160
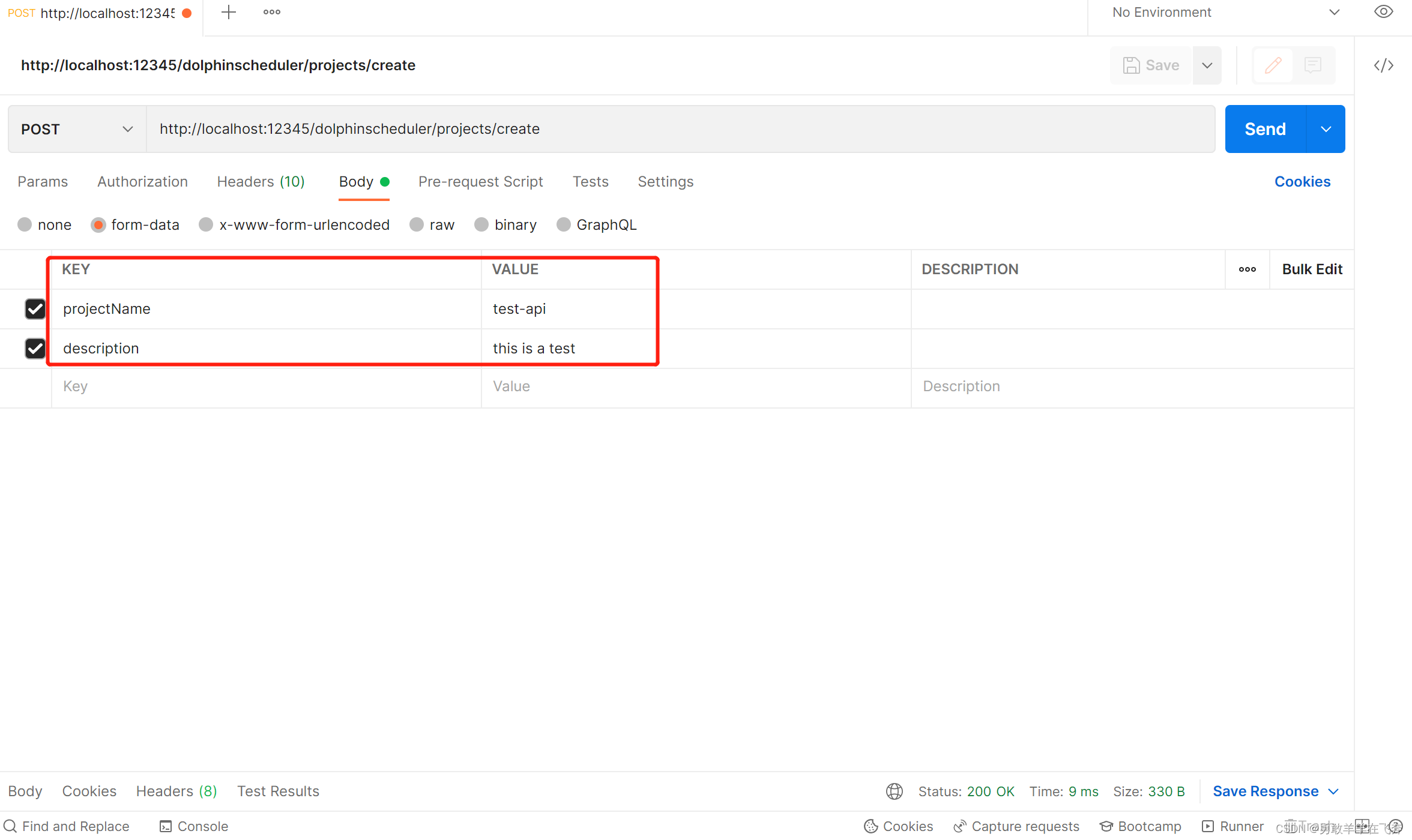
Apache DolphinScheduler:深入了解大数据调度工具 都会遍历所有的 worker,使其 current\_weight+weight,同时累加所有 worker 的 weight,计为 total\_weight,然后挑选 current\_weigh... 国内服务器 3周前120
缓存穿透、缓存击穿、缓存雪崩都有哪些常见处理? 本文总结了缓存穿透、击穿和雪崩三种常见缓存问题的解决方案。对于缓存穿透,建议参数校验、缓存空值、使用布隆过滤器拦截无效请求;缓存击穿可通过永不过期热点数据、互斥锁限流和服务降级处理;缓存雪崩则推荐错开... 国内服务器 3周前120
基于Spark的大规模数据集成处理实战教程 在数字化时代,企业数据像“爆炸的烟花”——来源多(日志、数据库、IoT设备)、格式杂(CSV/JSON/关系表)、规模大(TB级甚至PB级)。传统工具(如Python脚本、Excel)处理这类数据时... 国内服务器 3周前150
Springboot结合RabbitMQ实现延时队列 RabbitMQ实现延时队列的两种方案比较 摘要:本文介绍了RabbitMQ实现延时队列的两种方案。方案一利用死信交换机(DLX)和消息TTL机制,无需插件但存在队头阻塞问题,且需要为不同延迟时间创建... 国内服务器 3周前110