Java-208 RabbitMQ Topic 主题交换器详解:routingKey/bindingKey 通配符与 Java 示例 消息携带 routingKey(dotted-word,长度≤255字节),队列用 bindingKey 绑定到交换器;* 匹配“恰好1个词”,# 匹配“0到多个词”,通配符必须作为独立词出现。结合日... 国内服务器 3周前130
Spring Boot 4.0 整合 Kafka 企业级应用指南 生产者配置设置acks=all确保消息可靠性启用幂等性合理设置重试次数和超时时间使用压缩减少网络传输消费者配置禁用自动提交,使用手动提交合理设置避免内存溢出配置合适的心跳和会话超时时间使用消费者组实现... 国内服务器 4周前120
Kafka 消息持久化深度解析:从 PageCache 到磁盘的奥秘 消息持久化是指将消息数据保存到非易失性存储介质(如磁盘)中,以确保在系统故障、重启等情况下数据不会丢失。Kafka 的设计哲学之一是"数据不丢失",它将所有消息持久化到磁盘,并提供... 国内服务器 3周前100
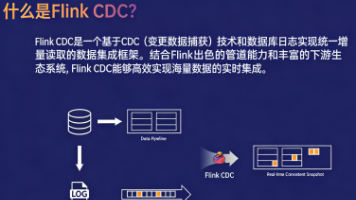
保姆级教程:Apache Flink CDC(standalone 模式)部署 MySQL CDC、PostgreSQL CDC 及使用方法 Apache Flink CDC 是一个数据集成框架,它基于数据库日志的 CDC(变更数据捕获)技术实现了统一的增量和全量数据读取。结合 Flink 出色的管道能力和丰富的上下游生态系统,Flink ... 国内服务器 4周前120
基于Spark的毕业设计论文:从实战项目选题到可运行系统的完整实现 面对大数据处理框架,常见的选择有Hadoop MapReduce、Spark和Flink。对比Hadoop MapReduce:Spark基于内存计算,速度上有数量级的优势,其API(RDD、Data... 国内服务器 3周前120
Flink监控体系实战:从零构建企业级运维平台 Apache Flink作为流处理领域的领军框架,其强大的实时数据处理能力已被广泛应用于各类企业级场景。然而,随着集群规模扩大和作业复杂度提升,构建一套完善的监控体系成为保障系统稳定运行的关键。本文将... 国内服务器 4周前120
揭秘大数据领域数据预处理的核心要点 在大数据时代,企业每天产生的海量数据中仅有不到20%能直接用于分析。数据预处理作为连接原始数据与数据分析模型的桥梁,其核心目标是将杂乱无章的原始数据转化为高质量的分析输入。本文将深入探讨数据预处理的五... 国内服务器 3周前140
时序数据库选型指南:大数据场景下的5种最佳解决方案 InfluxDB是时序数据库的“老牌玩家”,2.x版本整合了可视化(Chronograf)、流处理(Kapacitor)、存储,提供“一体化时序平台”。它用Flux语言替代了1.x的InfluxQL... 国内服务器 4周前140
RabbitMQ-阿里云部署实战:从Erlang环境搭建到安全配置 本文详细介绍了在阿里云ECS上部署RabbitMQ的完整流程,从Erlang环境搭建到安全配置与性能优化。通过源码编译安装Erlang、配置RabbitMQ集群、实施安全加固措施(如删除默认账户和启用... 国内服务器 3周前140