工作流调度平台 Dolphinscheduler – Standalone 单机部署 + Flink 部署【kafka消息推送、flink 消费】 Dolphinscheduler - Standalone 单机部署 + Flink 部署 国内服务器 4周前150
语音合成工具Spark-TTS实战指南:从零部署到高效调优的8大关键环节 作为一款基于LLM架构的开源语音合成系统,Spark-TTS在音色克隆和语音生成方面表现出色。本文通过8个关键环节的深度解析,帮助开发者快速掌握Spark-TTS的部署、配置和优化技巧,避开常见技术陷... 国内服务器 4周前100
《国产系统运维笔记》第7期:打工人换统信UOS国产电脑后,第一件事:装RabbitMQ! 本文详细介绍了在统信UOS操作系统上安装配置RabbitMQ消息队列的完整流程。内容涵盖系统环境确认、APT源安装、管理插件启用、用户权限配置等关键步骤,并重点讲解了MQTT插件的安装与验证方法。通过... 国内服务器 4周前100
头歌-Spark SQL 多数据源操作(Scala) 读取本地文件 file:///data/bigfiles/demo2.json,使用 Parquet 完成分区,列名为 student=2,保存到本地路径file:///result/下。读取本地文件... 国内服务器 4周前130
Spark机器学习实战:从数据预处理到模型部署全流程 我们的目的是让大家了解如何使用Spark进行机器学习的完整流程,从最开始的数据预处理,到中间的模型训练和评估,再到最后的模型部署。这个范围涵盖了Spark机器学习中最核心的部分,希望大家学完之后能够独... 国内服务器 4周前100
大数据OLAP中的列式存储技术深度解析 本文旨在深入解析大数据OLAP(联机分析处理)中的列式存储技术,包括其工作原理、优势特点、实现方式以及在实际系统中的应用。我们将从基础概念出发,逐步深入到技术细节和优化策略。文章首先介绍列式存储的基本... 国内服务器 4周前100
从一次 Kafka 启动失败,深挖本地服务间通信的“隐形陷阱” 本文通过一个Kafka启动失败的典型案例,揭示了本地服务间通信的关键优化点。当配置使用内网IP连接ZooKeeper时,会出现20秒以上的延迟,而改用localhost后响应时间缩短到10毫秒。根本原... 国内服务器 1个月前100
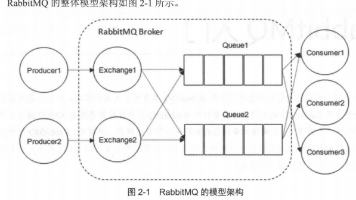
消息队列之Rabbitmq面试笔记总结 RabbitMQ是一个开源消息代理软件,其核心概念包括生产者(发送消息)、消费者(接收消息)、Broker(服务节点)、队列(存储消息)和交换器(路由消息)。交换器有四种类型:fanout(广播)、d... 国内服务器 1个月前120
2026年(第19届)中国大学生计算机设计大赛大数据主题赛参赛指南——“健康数据洞察” 旨在鼓励参赛者探索智能体在健康数据分析中的创新应用,例如利用智能体进行自动化数据探索、关联模式发现、预测建模以及资源优化策略的模拟推演,以人机协作的方式深化对健康生态系统复杂性的理解,并生成更具洞察力... 国内服务器 1个月前170
RabbitMQ与大数据图计算:实时关系传递 随着社交网络、知识图谱、供应链网络等复杂关系数据的爆炸式增长,传统批量处理的图计算模式已难以满足实时决策需求。RabbitMQ作为高性能消息队列系统,能够提供可靠的实时数据传输通道,与图计算框架结合可... 国内服务器 1个月前140