《Windows Internals》10.1.20 Hive structure:为什么一个 Hive 在内部不是“键和值的平铺集合”,而是 block、base block、bin、cell 这种 本文解析了Windows注册表Hive的分层存储结构,指出其并非简单的键值平铺集合。Hive内部采用4KB block作为基础存储单元,首个base block存储全局元信息(如regf签名、校验和等... 国内服务器 4周前150
存储系统的容量规划与管理:从预测到优化 存储容量规划是指根据业务需求和数据增长趋势,预测存储系统的容量需求,并制定相应的扩容和管理策略的过程。满足需求:确保存储容量能够满足业务需求避免浪费:避免过度配置,减少资源浪费优化成本:优化存储成本... 国内服务器 4周前120
Hadoop容错机制深度解析:从单点故障到集群自愈 fill:#333;important;important;fill:none;Hadoop容错体系数据容错副本机制数据块校验自动复制计算容错任务重试推测执行节点迁移服务容错ZooKeeper仲裁应用... 国内服务器 4周前130
大数据领域数据预处理的质量评估指标 数据预处理是大数据项目中最耗时且关键的环节,据统计,数据科学家80%的时间都花费在数据清洗和预处理上。本文旨在系统性地介绍数据预处理阶段的质量评估指标体系,帮助读者建立科学的数据质量评估框架。核心概念... 国内服务器 4周前130
Dubbo- 注册中心实战:Zookeeper 部署与 Dubbo 集成配置 摘要:本文详细介绍了Dubbo与Zookeeper的集成实践,从注册中心的核心作用到Zookeeper单机/集群部署配置。主要内容包括: 注册中心原理:阐述Zookeeper如何通过临时节点、Watc... 国内服务器 4周前210
大数据处理中HBase的表设计最佳实践 高并发随机读写:如电商网站的用户购物车数据、社交平台的消息存储;海量数据存储:如物联网的传感器数据(每秒钟产生百万条记录);半结构化数据:如日志数据(字段不固定,需灵活扩展列)。HBase的表设计是技... 国内服务器 4周前80
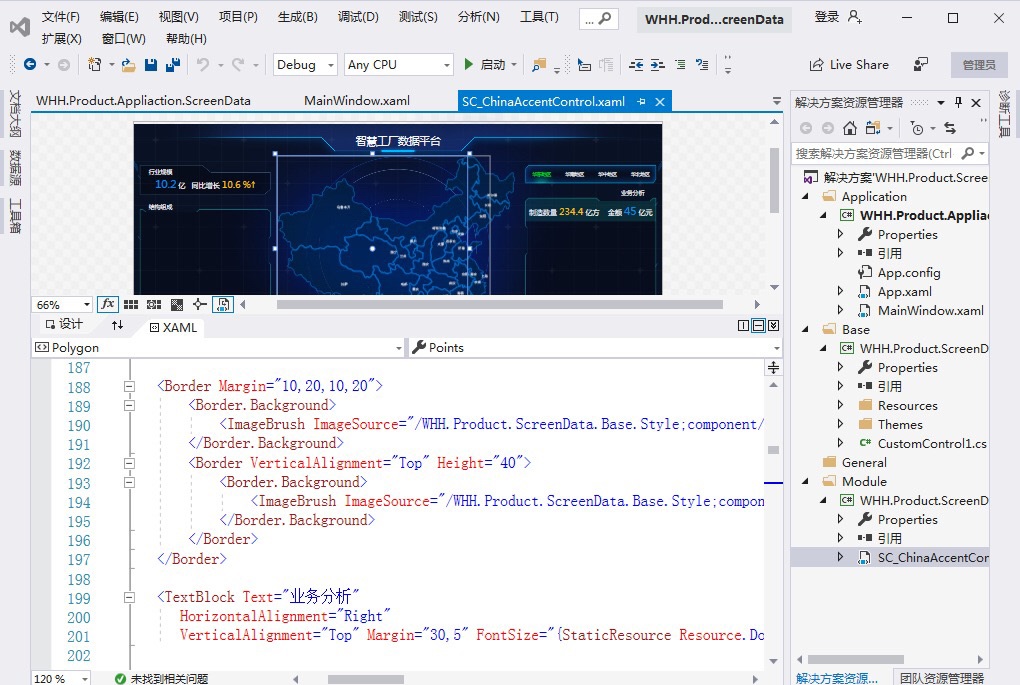
探索C# WPF大数据电子看板源码:打造智慧工厂数据平台 C#WPF大数据电子看板源码WPF智慧工厂数据平台1, 提供一个智慧工厂数据平台框架。2,理解wpf的设计模式。3,学习如何绘制各种统计图。4,设计页面板块划分。5,如何在适当时候展现动画。6,提供纯... 国内服务器 4周前110
Internet Archive下载器完整教程:轻松获取数字图书馆珍贵资源 想要永久保存Internet Archive和HathiTrust数字图书馆中的珍贵书籍吗?Internet Archive下载器就是你的完美解决方案!这款强大的浏览器扩展能够轻松下载借阅书籍,让你随... 国内服务器 4周前130
RabbitMQ 驱动下的工厂模式:AI 对话式向量化架构的“消息派单”实战 本文介绍了在campusai智慧园区项目中,如何通过工厂模式结合消息队列实现后台公告管理与AI向量化服务的解耦方案。针对后台管理系统版本低、业务类型多样化的挑战,设计了基于RabbitMQ的消息驱动架... 国内服务器 4周前140