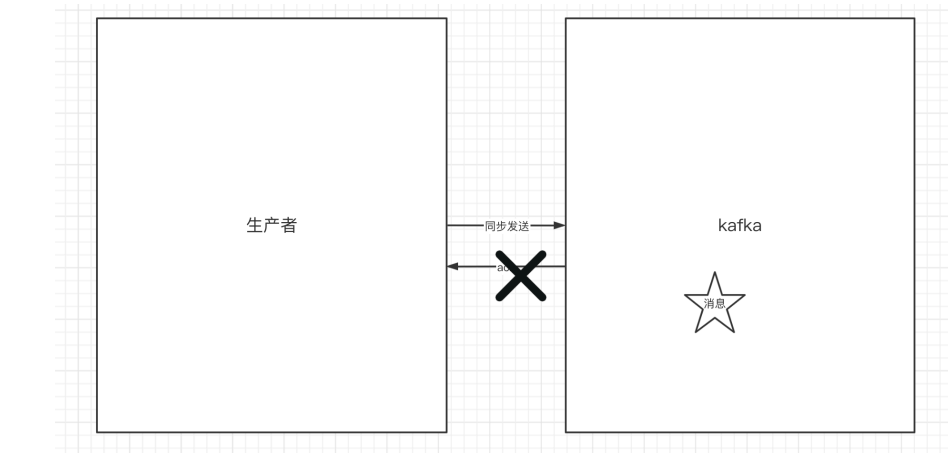
一篇文章速通kafka——day02 本文详细介绍了SpringBoot集成Kafka的实践过程,主要包括: Kafka生产者的实现方式(同步/异步发送、ACK配置、消息缓冲区) 消费者的核心实现(手动提交offset、长轮询机制、健康检... 国内服务器 4周前120
基于Doris的实时数据仓库建设:从理论到实践的完整指南 随着企业数字化转型加速,实时数据处理需求呈爆发式增长。传统数据仓库在面对高并发实时查询、海量数据实时写入时逐渐显现性能瓶颈,而Apache Doris作为一款高性能分析型数据库,凭借其极简架构与强大的... 国内服务器 1个月前170
大数据新视界 –大数据大厂之大数据与区块链双链驱动:构建可信数据生态 本文深入剖析大数据与区块链双链驱动,涵盖其背景、技术融合、多领域应用场景(包括金融、供应链管理、医疗健康、智能交通、能源管理等)、挑战及未来展望。通过丰富案例、表格及代码示例展现双链驱动优势,探讨量子... 国内服务器 4周前150
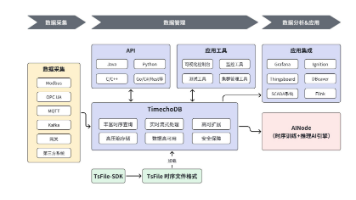
时序数据库选型:聚焦时间序列数据库Apache IoTDB——为工业物联网与大数据而生 摘要:本文系统分析了时序数据库的选型核心要素,对比了InfluxDB、TimescaleDB、VictoriaMetrics和Apache IoTDB等主流产品。时序数据具有时间戳、测量值和标签等特征... 国内服务器 1个月前130
深度实战:数据仓库缓慢变化维度SCD类型2处理全解析 在数据仓库维度建模中,缓慢变化维度(SCD)是核心知识点,其中SCD类型2是企业级数据仓库最常用、最能保留历史全链路数据的处理方式。很多数仓开发工程师在业务数据更新时,会遇到历史统计口径错乱、无法追溯... 国内服务器 4周前120
AI智能体行为分析实战:云端3步搞定,2块钱玩转大数据 极速启动:3步操作即可获得专业级分析结果,无需等待IT支持成本可控:按需使用GPU资源,基础分析仅需2元成本智能洞察:自动发现人工难以察觉的行为模式和异常点报告就绪:直接生成可视化图表和文字结论,汇报... 国内服务器 1个月前130
【大数据存储与管理】分布式数据库HBase:04 HBase的实现原理 本文讲解HBase的实现原理。HBase功能组件协同工作,表分区成Region分布存储。三层定位结构保障数据查找,客户端缓存提升效率,且能自动处理缓存失效,整体设计使Master负载降低。 国内服务器 4周前110
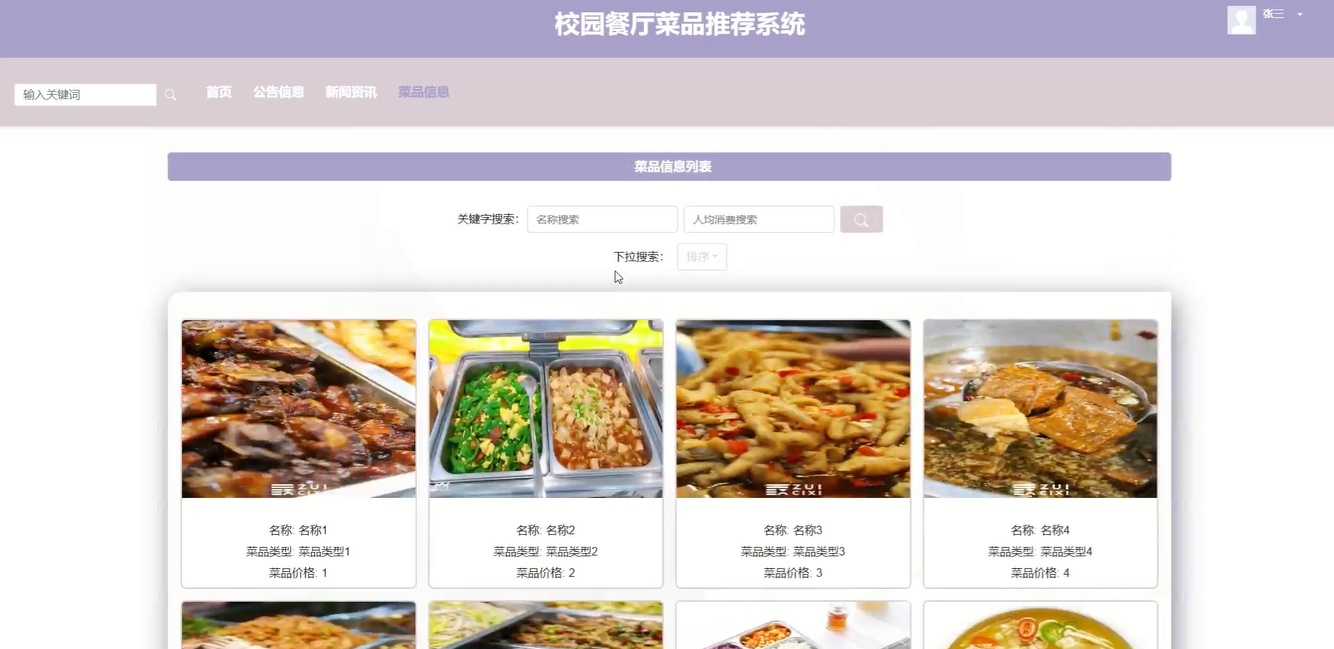
JavaHadoop校园餐厅菜品推荐系统 毕业设计—附源码29730 利用Hadoop强大的分布式计算能力,系统对用户历史行为和菜品特征进行深度分析,结合内容推荐与协同过滤算法,生成个性化的菜品推荐结果。前端用户界面友好,支持用户注册登录、菜品浏览、评论收藏、下单支付等... 国内服务器 1个月前150
SAP Ariba | EDI 传输:名称/单号被截断了怎么办? SAP系统中常出现供应商名称或订单号在EDI传输时被截断的问题,主要原因是主数据字段与EDI/IDoc结构的长度限制不匹配(如REGUH表仅支持35字符)。解决方案包括:拆分长名称到NAME2字段(N... 国内服务器 4周前150
Hadoop Checkpoint机制深度解析:原理、优化与最佳实践 Checkpoint优化检查清单checks = ["✓ 集群是否已启用HA?(HA下Standby自动承担Checkpoint)","✓ 当前Checkpoint频率是... 国内服务器 1个月前130